创新点:ResNeXt在ResNet的基础上,结合ResNet的block stack策略以及Inception结构分组卷积的思想,设计aggregrated transformations策略,在不增加模型复杂度的情况下,提高了模型识别的准确率,虽然没有提出特别新奇的网络结构,但是ResNeXt利用更简单的拓扑结构在不增加参数的情况下取得更好的效果,值得借鉴与思考。**其实resnext仅仅就是利用了group convolution,降低了网络的参数量,但是同时,增加了channel,发挥channel的效果,使得resnext的效果得到了一定的提升.
论文链接:https://arxiv.org/abs/1611.05431
如出现图像显示不完整,或者公式显示不完整,可访问如下博客
CSDN博客地址:http://blog.csdn.net/chunfengyanyulove/article/details/79450450
1.简介
ResNeXt是2017年CVPR的一篇文章,其模型在2016年ImageNet分类比赛中,取得了第二名的成绩。
论文中,作者首先提到,在进行网络结构设计时候,随着超参数的增加(width,filter size, strides, layers等),难度越来越大。
为解决这个问题,多种策略被提出:
- 1.VGG-nets、ResNet等采用策略:stack building blocks of the same shape
- 2.Inception策略: split-transform-merge:
首先利用1*1卷积降维,然后利用3*3卷积进行运算,最后利用concatenation进行融合。Inception虽然复杂度较低,效果较好,但是其filter的设计针对性较强,不利于模型的迁移。
本文作者的做法是:将ResNet中高维特征图分组为多个相同的低维特征图,然后在卷积操作之后,然后将多组结构进行求和,得到ResNeXt模型,如图1所示。
细心的读者可以发现,左边是64维,右边32个4实际上是128维,作者在此处实际上是保证了相同的模型复杂度,后面的说明中也有提到
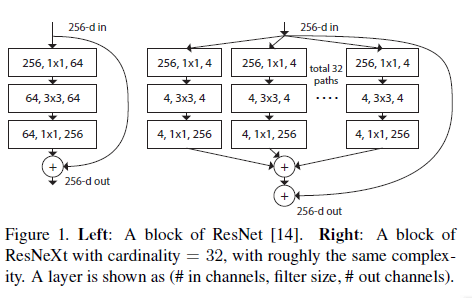
同时,作者提出cardinality概念,即图一中分组的组数(上图为32)。并且作者指出,增加cardinality比增加模型的深度和宽度更有助于提高模型的精度(后面实验有证明)
2.模型详解
作者说模型的blocks设计的两个原则:
- 如果产生相同尺寸的特征图,则他们共享超参数(width,filter size等)
- 如果特征图的大小减少一半,则block的数量增加一倍。
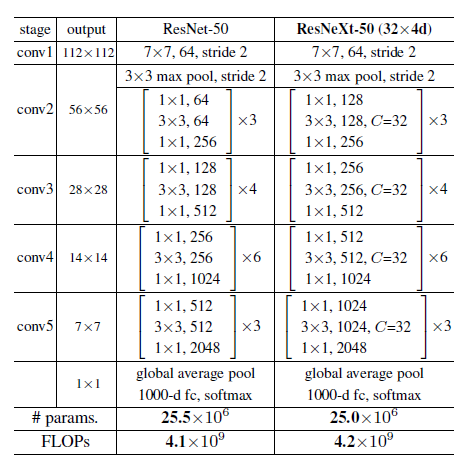
如下图2为ResNet与ResNeXt的模型对比,其模型的复杂度基本相同。
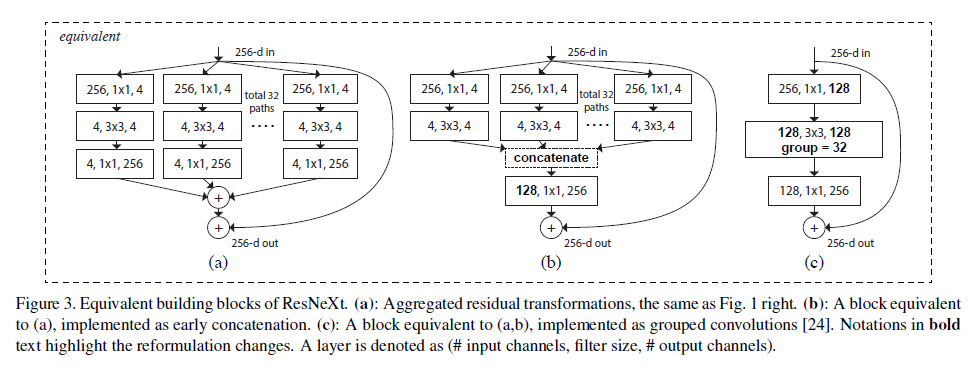
思考:通过计算分析,三种结构确实等价,b与c等价是显然的,c中的group convolution是将128个channel分成32组,然后每组进行3*3的卷积,最后concat在一起,然后利用一个256维的1*1卷积,将前面concat的128维,映射到256维;而在b中,首先将256维利用1*1卷积映射到4维,然后对4维进行3*3的卷积,这里跟c进行channel分组是一样的,最后接的concat以及映射到256维也是一样的。a与b等价的原因是:在a中,4维特征图通过1*1卷积变为256维,然后32个256维数据求和,而在b中,是先将4维数据concat成128维,在利用1*1卷积,实际上也就是求和过程,画图理解便很清晰了。
作者指出,图3的三种结构等价,由于第三种结构较为简单且具有较高的效率,所以作者在实验中选择第三种结构。
同时,作者指出,当depth = 2的时候,如下图4所示,网络拓扑结构仅仅是变得更宽了,并没有实现分组的价值,所以depth应该大于2。
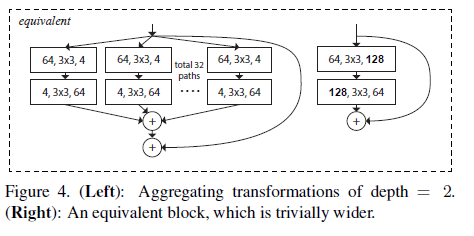
图5表示了在参数量基本相同的情况下,cardinality与width的关系。
此处可以看出,参数量相同1*64 == 32*4

ResNeXt模型block网络细节:
1 | class Bottleneck(nn.Module): |
3.实验
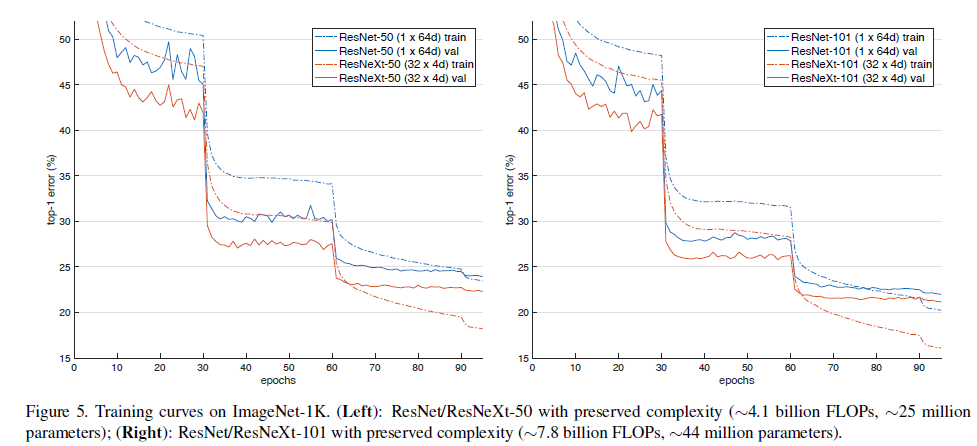
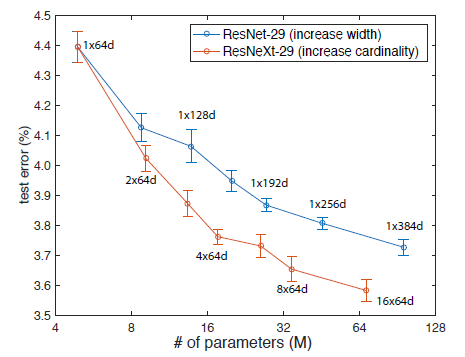
作者首先对比了Cardinality 与Width的关系,实验结果如下图6所示:
通过对实验结果分析可以发现,ResNeXt的error较ResNet有降低。并且随着分组数量的增加,error在下降。
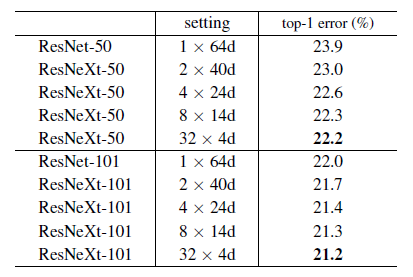
其次,作者比较了增加Cardinality以及增加deep/wider产生的效果。
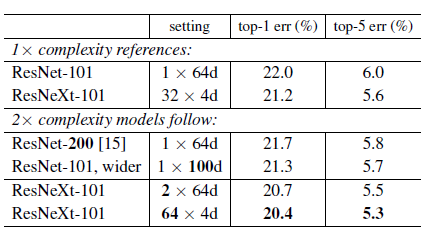
结果显示,增加cardinality比增加deeper/wider更有效,并且ResNeXt只用了一半的复杂度便达到了ResNet200的精度,也可以看出其效果,对比结果如下图所示:
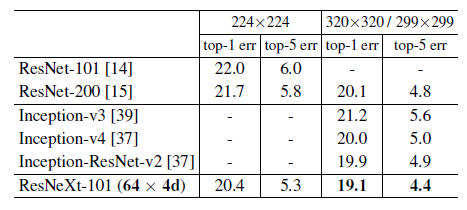
与state-of-the-art对比结果如下图:
在CIFAR数据集上实验,同样说明了增加cardinary相比增加width的效果更好
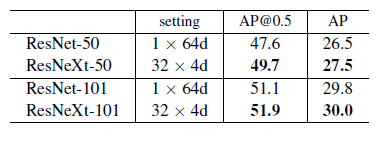
另外,作者利用Faster-RCNN模型,测试了ResNeXt结果在COCO数据集的效果,利用1K训练集预训练的模型,对Faster-RCNN产生了较小的改进,作者认为,如果选择更大的训练集,应该会取得较大的效果,COCO检测结果如下:
备注:
ResNeXt,PyTorch详细代码参考链接如下:
https://github.com/miraclewkf/ResNeXt-PyTorch