简介
笔者也是最近偶然的机会才开始接触TVM,使用过后发现,经过auto-tuning后的TVM模型在速度是竟然超过了TensorRT,并且笔者使用的是MXNet模型,TVM对MXNet绝对的友好,对于Pytorch等模型,可以使用ONNX,操作一样简单,使用起来基本类似一键操作,本篇文章是笔者对TVM的简单整理,也算是对TVM的入门。
当然如何想详细了解TVM,还请阅读TVM的主页以及论文,文章最后有链接。
正文
随着深度学习的发展,深度学习的能力可以说是越来越强大,识别率节节攀升,甚至超过人类。于此同时,深度学习框架也变得越来越多,目前比较主流的深度学习框架包括:Pytorch、TensorFlow、Mxnet、Caffe、Keras等。
一般进行深度学习任务包括两部分,一是训练出精度比较高的模型,然后将其部署到对应的目标机器上。
针对第一部分,自然我们可以使用各种深度学习框架,通过修改网络调参等,训练出精度比较满意的模型,一般情况,在训练深度学习模型的时候,都会使用到GPU。
针对部署,这里的目标机包括服务器、手机、其他硬件设备等等。部署的模型自然是希望越快越好,所以硬件厂商一般会针对自己的硬件设备进行一定的优化,以使模型达到更高的效率,比如Nvidia的TensorRT。但是框架这么多,硬件平台这么多,并不是所有的硬件平台都像Nvidia提供了硬件加速库,而即使做了加速,要适应所有的深度学习训练框架,也是一件比较难的事情。
其实介绍了这么多总结起来就是两个问题:
- 在进行模型部署的时候,我们是否可以对不同框架训练的模型均生成统一的模型,解决硬件平台需要适配所有框架的问题?
- 在进行模型部署的时候,我们是否可以自动化的针对不同的硬件进行优化,进而得到高效的模型?
TVM实际上就是在解决这两个问题,并且解决的还不错。
那么TVM是什么?
TVM is an open deep learning compiler stack for CPUs, GPUs, and specialized accelerators. It aims to close the gap between the productivity-focused deep learning frameworks, and the performance- or efficiency-oriented hardware backends.
TVM是一个开源的可面向多种硬件设备的深度学习编译器,它的作用在于打通模型框架、模型表现以及硬件设备的鸿沟,进而得到表现最好的可部署的深度学习模型,实现端到端的深度学习模型部署。
TVM做了哪些工作
针对第一个问题:
TVM将不同前端(深度学习框架)训练的模型,转换为统一的中间语言表示,如果想详细理解这里,可以了解一下NNVM,NNVM是陈天奇团队开发的可以针对不同框架进行深度学习编译的框架,在TVM中,陈天奇团队进一步优化,实现了NNVM的第二代Relay。Relay是TVM中实现的一种高级IR,可以简单理解为另一种计算图表示。其在TVM所处的位置如下图所示,并且该部分实现了比如运算融合等操作,可以提升一部分模型效率。
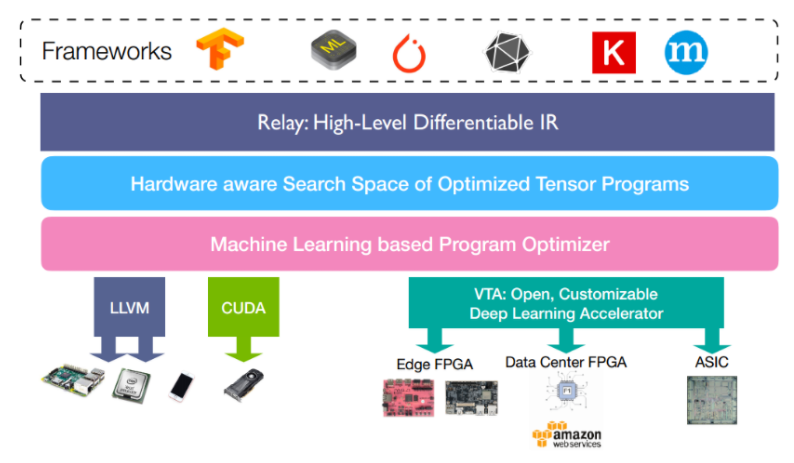
针对第二个问题:
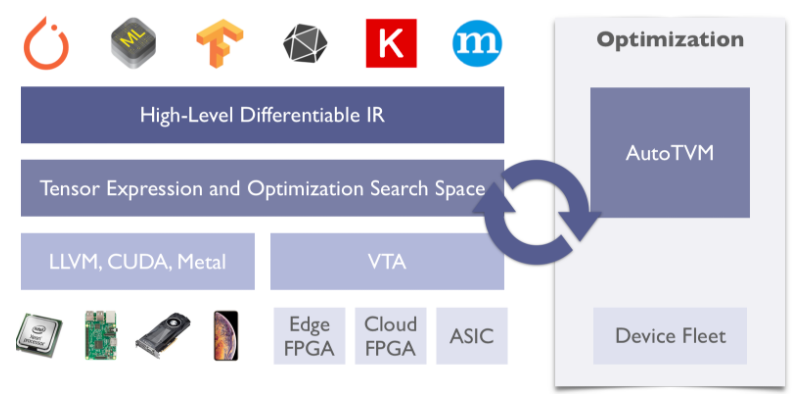
TVM设计了对不同的硬件后端,自动优化tensor操作,以达到加速的目的。该部分的实现,TVM使用机器学习的方法进行计算空间的最优化搜索,通过在目标硬件上跑大量trial,来获得该硬件上相关运算(例如卷积)的最优实现。详细介绍可以参考TVM主页以及论文。
TVM 安装
不同环境的安装方法可以参考tvm的官网:https://docs.tvm.ai/install/index.html
对于安装环境,我还是强烈推荐docker的,会少很多坑。
- 直接pull陈天奇上传到dockerhub上的镜像,就可以tvm的各种操作了
1 | docker pull tvmai/demo-gpu:latest |
这个镜像是cuda8.0版本,如果需要在2080ti上实验,是跑不起来的,会报错。
- 2080ti上重新build镜像
(1)首先,把github的tvm项目拉到2080ti机器上。
(2)进入dockers文件夹,找到Dockerfile.demo_gpu,其内容默认是下面这样的
1 | # Minimum docker image for demo purposes |
(3)将FROM tvmai/ci-gpu:v0.54修改为FROM tvmai/ci-gpu:latest
(4)重新build这个Dockerfile就可以了。
TVM 使用
TVM的使用可以阅读一下tvm提供的tutorials:https://docs.tvm.ai/tutorials/
主要推荐两部分:
- compile deep learning models
- auto tuning
其实简单的使用主要就是这两块内容,如果不想细研究其代码,可以将其当成一个工具使用,通过compile deep learning models,无论你使用什么样的框架,都可以生成统一的模型,一般会生成3个东西如下:
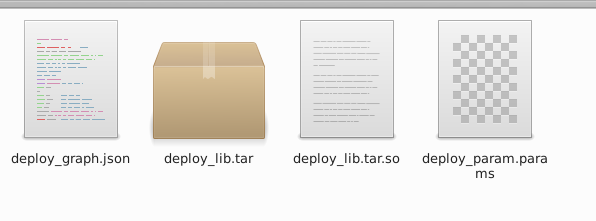
这里一般会做一些层的融合等操作,速度会有一定的提升的,但是不是特别大。这时如果你需要进一步提速可以试试auto tuning,这部分可以参考tutorials以及下面的例子代码,auto-tune的时间一般比较长,但是效果还是比较显著的,本地测试,resnet在nvidia 1080ti上可以提高3倍左右。
Demo代码
TVM的原理很复杂但是使用起来还是比较方便的,下面是使用MXNet进行TVM转换的demo。
代码一:生成TVM模型。
1 |
|
代码二:auto-tuning,这部分还是比较慢的,一个resnet101模型,在1080ti上面可能要tune1到2天的时间。
1 | import os |
测试结果
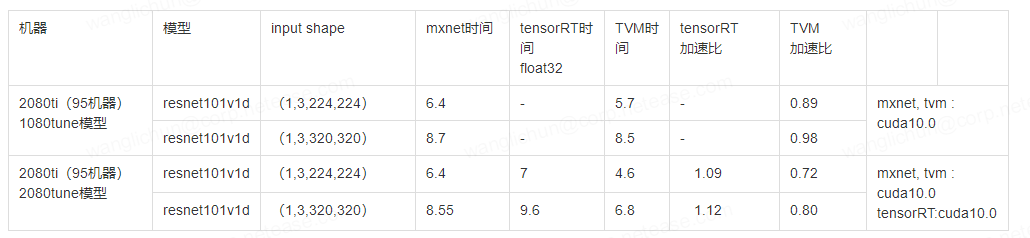
- 本地Nvidia 1080ti 测试
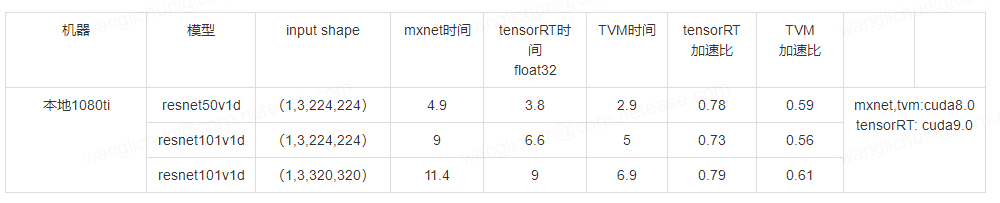
首先在,两卡机上测试性能,分别测试了resnet50v1d,resnet101v1d以及输入尺度320的resnet101v1d,测试结果如下表:
可以发现,相比较mxnet模型 tensorRT大约加速比70%-80%,TVM提速可以达到50%-60%
- Nvidia 2080ti 测试
如下分别测试了tvm加速在2080上的效果,可以发现:
- 在2080机器上,mxnet的提速还是比较明显的,加速比大概 70%
- 在2080机器上,tensorRT float32速度,跟在1080上基本一致,没有提速。
- 在2080机器上,TVM速度与在1080上相比,反而有一丢丢的减速。
在2080机器上重新auto-tune了TVM模型,可以发现:
- 重新在2080机器上tune后,相比不tune,效果的提升还是比较明显的。
- 重新在2080机器上tune后,跟在1080上的速度相差不大。
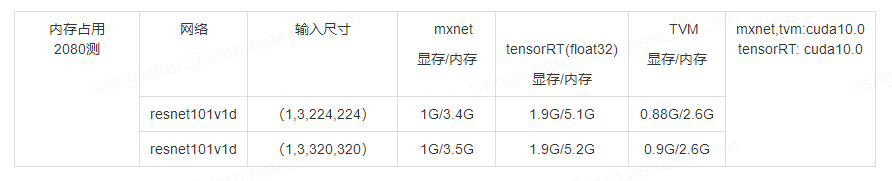
下面测试了内存的消耗。总体来看TVM比较省内存和显存。
补充:TensorRT
TensorRT是Nvidia出品的用于将不同框架训练的模型部署到GPU的加速引擎,可以自动将不同框架的模型转换为TensorRT模型,并进行模型加速。
TensorRT进行模型加速主要有两点:
- TensorRT支持int8以及FP16计算
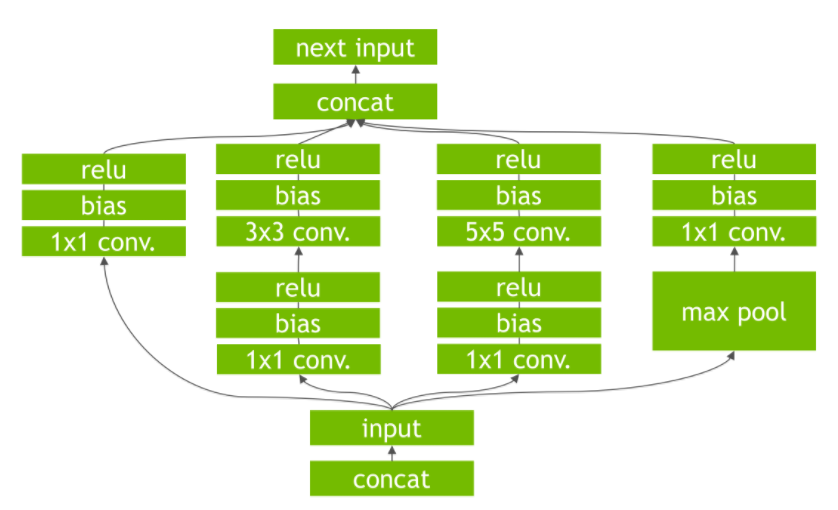
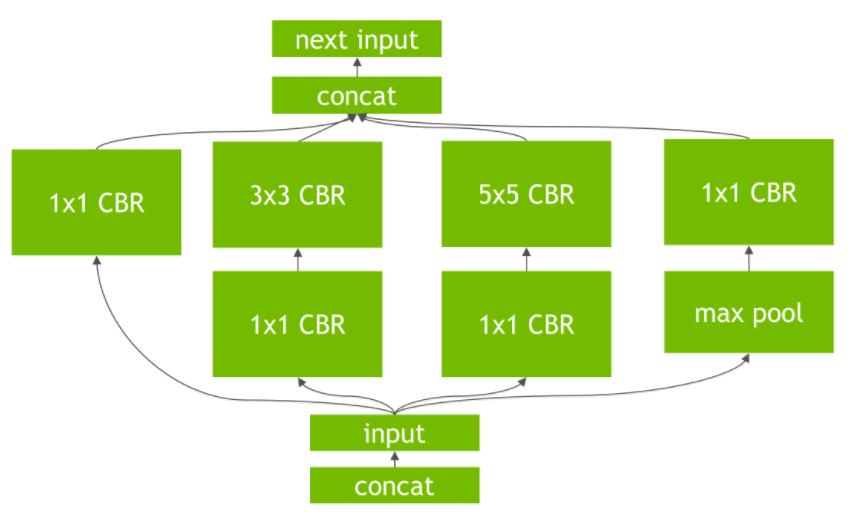
- TensorRT对网络进行重构以及优化:
去掉网络中的无用层
网络结构的垂直整合
网络结构的水平融合
参考资料
TVM论文:arxiv: https://arxiv.org/abs/1802.04799
tensorRT加速参考文献:https://blog.csdn.net/xh_hit/article/details/79769599
Nvidia参考文献:https://devblogs.nvidia.com/production-deep-learning-nvidia-gpu-inference-engine/