知识点总结
- 首先利用Selective Search方法提取Region Proposal
- Region Proposal缩放后送入到CNN网络,为什么要缩放,因为fc层要求固定大小的输入。
- CNN提取特征后,送入到后面的SVM进行分类(这里还涉及到难例挖掘)
- 回归部分,利用4个线性回归,对proposal的坐标计算。
- CNN使用预训练模型,然后在VOC上进行finetune
重要链接
论文链接:https://arxiv.org/abs/1311.2524
GitHub代码链接:https://github.com/rbgirshick/rcnn
如果出现图片或者公式显示不完整,可访问图像博客
CSDN博客:http://blog.csdn.net/Chunfengyanyulove/article/details/79548472
正文
R-CNN是将深度学习用于目标检测的鼻祖之作,在目标检测精度几年不在提升之后,得到了约30%的精度提升,之后,开启了深度学习在目标检测领域的一统天下,包括后面提出的Fast R-CNN、Faster R-CNN等,不仅在精度上有了进一步的提升,在速度上也有较大的进步。
那么,作者实如何引入深度学习,又是为什么会产生如此大的提升,作者又是怎么做的呢?下面做详细介绍:
在深度学习之前,目标检测的方法多是使用人工提取的图像低层特征的组合(如:SIFT、HOG等),这样不仅图像提取的特征的维度非常大,而且由于其特征较为低级,很难突破瓶颈,导致在2010-2012年,图像目标检测的精度提升缓慢。
在2012年,AlexNet横空出世,在图像分类领域一枝独秀,作者在AlexNet以及特征多级提取的思想作用下,作者设计了R-CNN,并通过多次试验,达到了30%的精度提升。
那么R-CNN是怎么干的呢?如下图:

简单描述为:R-CNN首先利用Selective Search方法提取图像候选框,然后将候选框缩放到227*227,放入CNN网络(AlexNet)提取特征,CNN后,利用SVM进行类别分类。
那么为什么要这么做?每一步的细节又是什么样的呢?
利用Selective Search提取候选框
跟图像分类不同的是,目标检测需要对目标进行精确的定位,作者论文提到了如下一些方法:
- 直接使用回归进行定位,但是作者说该方法效果较差。
- 利用sliding-window,但是由于特征提取中我们的网络较深,所以最后提取的特征感受野较大,这使得sliding-window方法受限。
- recognition using regions
该方法通过类似Selective Search等方法,在图像中提取大量的候选框,然后对每一个候选框进行特征提取分析,找到做好的定位。与Selective Search相似的算法也比较多,作者选择Selective Search也是由于Selective Search可控性较强,而且速度还可以。
在提取候选框之后,便需要将图像输入到CNN中提取特征,作者又是如何做的呢?
输入图像处理方式
由于Selective Search提取的候选框的大小不一,但是CNN要求输入的图像大小固定(227*227),所以需要对SS方法提取的图像进行变换,作者尝试了几种方法如下:
1、直接截取较大的矩形区域,然后缩放到227*227。
2、直接填充训练图像的均值,得到矩形区域,然后缩放到227*227。
3、直接缩放到227*227。
4、对上述方法,预留16个像素的边界。
截取方法如下图所示,其中B、C、D分别对应1、2、3,每组的第一行为没有预留边界,第二行为预留了16个像素边界。

作者通过实验发现,采用直接缩放,并且预留16个像素边界的实验效果最好。
输入图像的问题解决了,那么该如何训练我们的网络呢?这里又遇到了第二个问题,训练数据集较小。
训练网络
由于在目标检测中,我们的数据量有限,所以作者首先采用ImageNet数据集预训练网络模型,然后利用VOC数据集进行fine-tuning,由于VOC数据集只包含20类,所以作者调整CNN模型只输出21类(20类+背景),并且为了增大数据集,作者将与Ground Truth的IOU大于0.5的Region Proposal标记为正样本,其余的为负样本,在训练的时候batch size为128,其中32个正样本,96个负样本。
训练SVM分类器
为了得到每个对象的类别,作者为每个类别训练了一个SVM分类器,作者将每个类别的Ground Truth作为正样本,对于IOU小于0.3的region proposal作为负样本。
并且由于训练的数据较大,需要占用较大内存,所以作者利用standard hard negative mining方法进行训练,实验证明该方法收敛迅速。
0.3这个阈值是作者通过grid search试出来的,{0,0.1,0.2,0.3,0.4,0.5}逐一试。
为什么训练CNN与训练SVM采用不同的训练样本?
这个参数的选择也是作者实验做出来的效果,采用该定义的时候,效果较好。
同样作者为了解释这个现象同样进行了对比实验,作者首先利用预训练的CNN提取的特征训练SVM,在训练过程中,作者发现,存在一些优化方法可以优化结果,这就包括本文式样的fine-tuning方法,然后作者使用训练SVM的样本定义方法进行fine-tuning,但是作者发现效果没有本文最后确定的方法好,作者解释如下:
对于在训练CNN以及SVM的时候,正负样本的定义不同,主要在于训练数据集有限。作者采用IOU为0.5增加了将近30倍的训练数据,这可以有效的在fine-tuning的过程中防止过拟合,但是由于使用了这些数据,导致其在目标定位中的精度下降。
这就带来了另一个问题,我们为什么不直接在网络后面利用回归进行检测而是训练SVM分类器呢?作者实际上使用softmax进行了测试,但是作者发现,其精度降低了,导致精度降低的主要有几方面,如:进行fine-tuning时候的目标精度本身就存在偏差,不是ground truth,另外softmax的训练采用的是随机的负样本而不是采用的hard negatives样本。
另外,作者提出,不使用SVM应该也可以达到类似的精度,可以进行进一步的研究。
Bounding-box Regression
进一步的,作者设计了Bounding-box Regression用于对坐标进行微调,使得得到的目标更接近于ground truth
对于region proposal 以及ground truth,本文分别用如下代替:
$$P_i=(P_{x}^{i},P_{y}^{i},P_{w}^{i},P_{h}^{i})$$
$$G_i=(G_{x}^{i},G_{y}^{i},G_{w}^{i},G_{h}^{i})$$
其中x,y为中心点坐标,w和h分别为长和宽。
作者通过线性变换,计算P的偏移量,得到预测坐标如下:
$$\hat{G}_{x} = P_wd_x(P)+P_x$$
$$\hat{G}_{y} = P_hd_y(P)+P_y$$
$$\hat{G}_{w} = P_wexp(d_w(P))$$
$$\hat{G}_{h} = P_wexp(d_h(P))$$
其中$d_*(P)$代表一种线性变换,对pool5特征进行计算,我们标记特征为$\phi_5(P)$,$d_*(P)=w_*^T\phi_5(P)$,作者设定优化函数为:
$w_*=argmin_{w_*}\sum(t_*^i-w_*^T\phi_5(P^i))^2+\lambda||w_*||$
$t_*$定义如下:
$$t_x=(G_x-P_x)/P_w$$
$$t_y=(G_y-P_y)/P_h$$
$$t_w=log(G_w/P_w)$$
$$t_h=log(G_h/P_h)$$
这里分析一下,为什么作者在x,y分别除了w和h,原因在于其偏移量产生的loss与proposal的大小有关,比如同样是向左偏移10个像素,如果proposal是100*100和10*10产生的误差是不一样的,所以作者除了w和h。
并且作者指出,必须选用有用的(P,G)组合才行,如果P离Ground Truth较远,那么进行转换便没有意义了,所以,这里作者只选用了距离ground truth较近的目标进行回归,作者设定的参数是IOU为0.6。
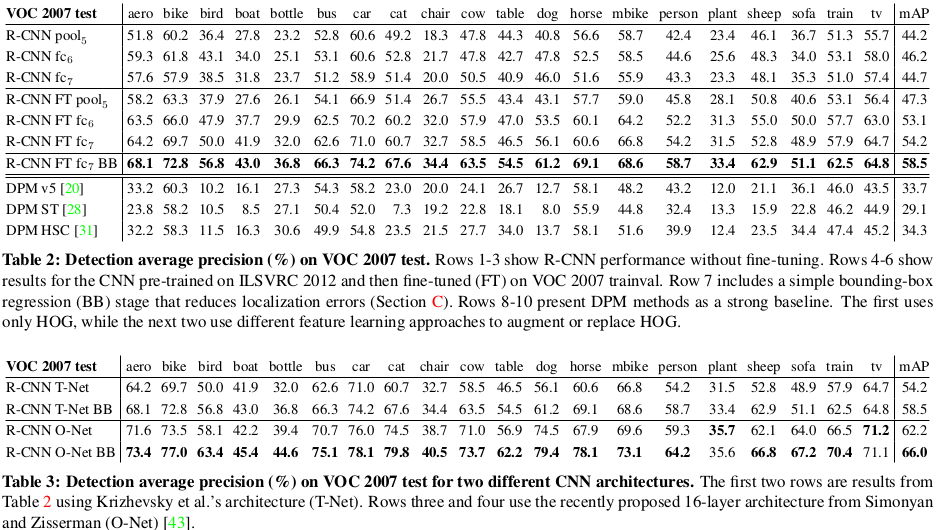
R-CNN精度对比
作者对比了R-CNN(是否包含bounding box方法),以及其他算法的精度,测试结果见下图,由下图可以发现,R-CNN BB的精度遥遥领先。

学习特征可视化
作者设计了一种无须参数的可视化方式,来判断每个unit学到的是什么,该方法首先选定一个特定的unit,然后在10万个region proposal中找到激活值最大的前几个,并利用非极大值抑制,最后显示出学到的区域,作者在CNN网络的pool5后进行实验,作者论文中展示了6组测试结果,如下:

Ablation studies
为了验证不同层在检测中的作用,作者进行了如下对比实验,实验结果如下图:
- 针对pool5,fc6,fc7层的分类能力对比,作者发现,其实pool5的分类能力已经很强,fc6和fc7虽然占有大量的参数,但是并没有取得实质的提升。row1-3
- 对pool5,fc6,fc7采用fune-tuning进行实验对比,作者发现,fune-tuning之后,模型的识别能力提升了近8%,fc6和fc7提升明显,但是pool5提升不明显,这样说明了pool5提取的特征具有一定的泛化性。row 4-7
- 与其他方法进行对比,优势明显。row 8-10