Fast R-CNN是RBG大神于2015年发表的目标检测网络,其在SPP-Net的基础上,通过进一步的改进,使得目标检测精度以及检测速度有了进一步的提升,下面详细介绍Fast R-CNN的创新点。主要创新点在于:1. Fast R-CNN设计了multi-loss方式进行目标分类以及位置回归,不需要进行特征存储到disk,使得效率有了大大的提升,2. 不需要multi-pipeline。3. CNN参数全更新。4. 单个ROI-pooling不再是SPP-Net的多级pooling,ROI pooling可以理解为SPP-Net的特殊形式。5. 使用mini-batch SGD方式进行训练。6. 利用SVD方式进行速度的提升。
重要链接
如果存在图像公式无法查看可访问如下博客:
csdn博客:https://blog.csdn.net/chunfengyanyulove/article/details/79835557
论文链接:https://arxiv.org/abs/1504.08083
Q1:SPP-Net存在哪些待改进问题?
- SPP-Net仍然采用R-CNN的策略,需要将CNN提取的特征存储到disk中,然后利用SVM分类器进行分类,效率比较低,并且存储比较消耗空间。
- SPP-Net在训练CNN的过程中,对于pooling前面的卷积层并没有进行参数的更新,这带来了一定精度的损失,在本篇论文中,作者也有对比。
- SPP-Net的训练仍然是multi-pipeline的,无法做到端到端,总体而言比较费劲。
Q2:Fast R-CNN做了哪些创新点呢?
- Fast R-CNN设计了multi-loss方式进行目标分类以及位置回归,不需要进行特征存储到disk,使得效率有了大大的提升,如图1所示。
- 不需要multi-pipeline。
- CNN参数全更新。
- 单个ROI-pooling不再是SPP-Net的多级pooling,ROI pooling可以理解为SPP-Net的特殊形式.
- 使用mini-batch SGD方式进行训练。
- 利用SVD方式进行速度的提升。
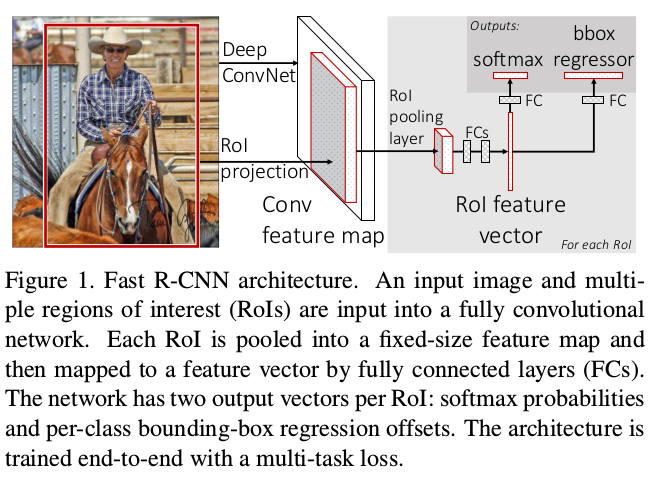
Q3:ROI-pooling
fast r-cnn网络的roi-pooling没有选择与spp-net相同的多级金字塔式的池化,而是选择了单级固定大小的池化,作者也通过实验证明,其实选择多级金字塔池化对精度会有一定的提升,但是影响不大,但是会降低速度,所以有点鸡肋。
Q4: Fast R-CNN训练整个网络,而SPP-net只训练了roi-pooling后面的网络
为什么SPP-Net没有训练全网络,而只是训练了roi-pooling后面的网络呢?
作者给的解释如下:
The root cause is that back-propagation through the SPP layer is highly inefficient when each training sample (i.e.RoI) comes from a different image, which is exactly how R-CNN and SPPnet networks are trained. The inefficiency stems from the fact that each RoI may have a very large receptive field, often spanning the entire input image. Since the forward pass must process the entire receptive field, the training inputs are large (often the entire image).
解释一下就是,在R-CNN以及SPPNet的训练策略中,在训练的时候,首先每个图像提取proposal,会提取很多个的proposal,但是在训练的时候,并不是每次前向的都是相同图像的proposal,而是很可能来自不同图像的,而事实是,往往提取的proposal都很大,这样耗时就会很严重,进而导致训练的特别慢。
Fast R-CNN给的方法如下:
作者采用分层SGD训练的方法,默认每次选取2张图像,并在每张图像选取64个roi进行训练,其实就是限制了前向的只能来自两张图像,进而限制了前向的计算量,提升效率。
作者说,这种方法由于是在两张提取的proposal,很有可能相似性很大,导致收敛很慢的现象,但是实验证明并没有发生。
Q5: 多任务损失设计
Fast R-CNN含有两个输出层,分别用于计算分类结果以及计算检测框的坐标结果。第一个输出层通过softmax计算相应ROI在各个类别中的概率。第二个输出层计算相应ROI的检测框的坐标值。算法采用多任务的损失函数对每个标定的ROI的类型和检测框坐标进行回归计算,损失函数公式如下。其中$L_{cls}$用于计算分类概率损失的函数,是一个softmax损失函数, $L_{loc}$是检测框坐标的损失函数, 定义如下:
$$L(p,u,t^{u},v)=L_{cls}(p,u) + \lambda[u>=1]L_{loc}(t^u,v)$$
$$L_{loc}(t^u,v)=\sum_{i in(x,y,w,h)}smooth_{L_{1}}(t_{i}^{u}-v_{i})$$
$$ if |x| < 1,smooth_{L_{1}}(x)=0.5x^{2},else,smooth_{L_{1}}(x)=|x|-0.5$$
- 在R-CNN以及SPPNet中,使用的是L2 loss,这里使用的是smooth L1 loss, smooth L1 loss相比较于L2 loss,对于离群点更加的鲁棒。
- 另外,在正负样本的选取上,选取25%的IOU>0.5的区域作为正样本。IOU在0.1到0.5的选取为负样本。
Q6: Back-propagation through RoI pooling layers.
简单来说,就是对于每一个mini-batch的ROI区域,因为一张图会有多个ROI区域过ROIPooling,所以在反向传播的时候,对多个ROI的结果进行累加,即如果这个ROI对应的点被选中为最大值,则对其导数进行累加,得到反向传播的梯度:
$$\frac{\partial_{L}}{\partial_{x_{i}}}=\sum_{r}\sum_{j}[i=i*(r,j)]\frac{\partial_{L}}{\partial_{y_{r,j}}}$$
In words, for each mini-batch RoI r and for each pooling output unit yrj, the partial derivative ∂L/∂yrj is accumulated if i is the argmax selected for yrj by max pooling.
Q7:利用奇异值分解进行提速
作者提到,在进行前向传播中,将近一半的时间在全连接层,所以如果可以在此进行加速,将对整个网络的速度提升有较大帮助,因此作者提出可以利用奇异值分解。
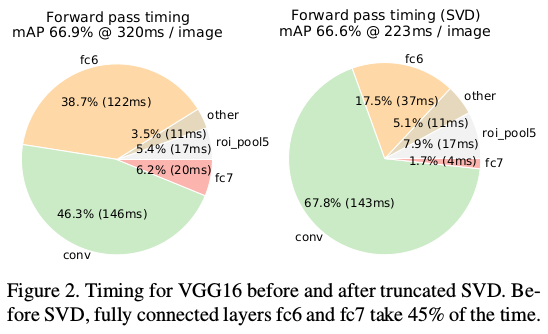
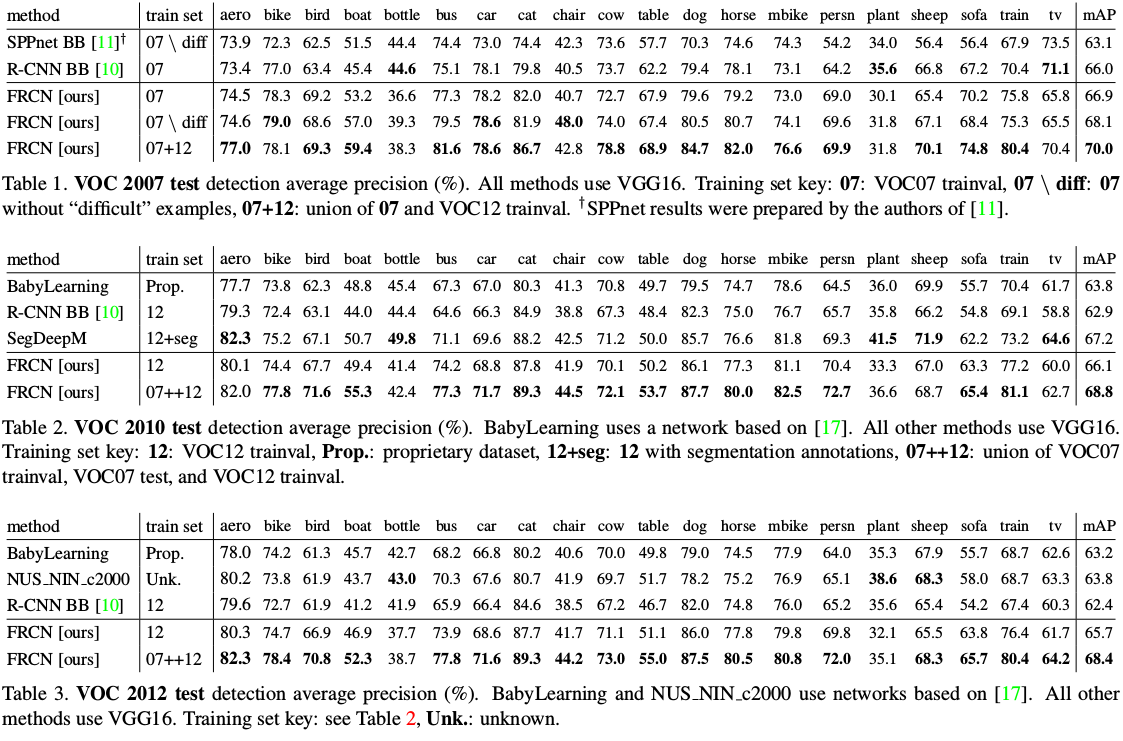
Q8: Fast R-CNN实验效果
看图最清晰了。
Q9:Which layers to fine-tune
作者通过实验证明,训练CNN网络的时候,前面几层训练带来的精度提升不明显,说明前面提取的特征如:边缘等比较固定有效,对于后面几层的训练对于精度提升比较明显。
对于越深的网络越需要训练。
Q10: 作者其他的说明
- 对于尺度不变的说明,作者实验证明了通过多尺度可以提高检测精度。
- 增加proposal有用吗?实验证明不是越多越好,越多反而会下降。