RFBNet是ECCV2018的一篇文章,文章的主要创新点在于通过Inception结构以及dilated conv模拟了人类的视觉结构—越往外视觉感受野也越大,提出了RFB结构,并将RFB结构应用于SSD结构上,实现了在不增加过多计算量的情况下模型效果的提升。
作者: Songtao Liu, Di Huang, Yunhong Wang
论文链接: RFBNet论文
代码链接: https://github.com/ruinmessi/RFBNet
RFB背景
我们说为什么深度学习的效果会比其他的机器学习方法要好,关键点在于CNN的表征能力比较强,而往往越深的网络,表征能力也越强,带来的也是更多的计算量,更慢的速度。所以要达到速度快,精度高的目标,就需要我们在轻量级网络中,通过设计某种方法,提高网络的特征表征能力。本文作者的灵感来源于人类的视觉系统,在人类的视觉系统中,往往离中心比较近的地方,感受野会比较小,而比较远的地方,感受野会比较大,借鉴于此,本文就引入了RFB结构,达到了这个目标。
在人类视觉系统中,视觉感受野是一个视网膜离心率的函数,下图表示了离心率与感受野尺寸的示意图,可见,离心率越大,尺寸也越大。
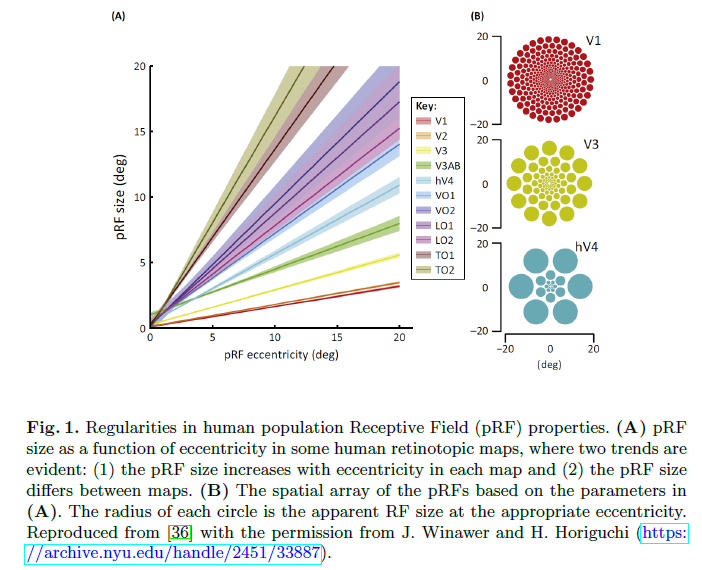
反观,我们现在的CNN网络,感受野基本都是一致的,这就会带来一定的特征的损失。
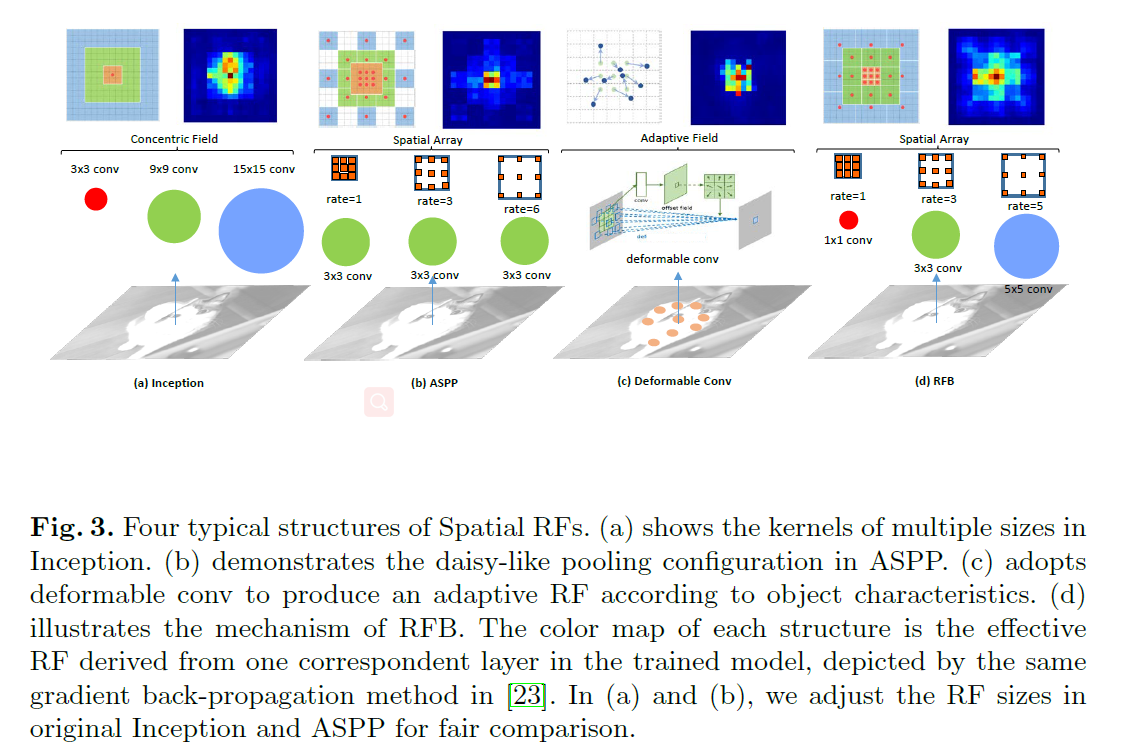
Inception block虽然使用了多个分支,构造了不同感受野,但是其融合的时候是以相同的中心进行融合的,ASPP网络,选择使用dilated conv实现了相同中心,不同距离的采样,但是感受野是一致的,如下图所示。
其实,RFBNet就是将Inception和ASPP进行了融合,达到更好的效果。如下图所示,使用空洞卷积来控制离心率,得到不同的感受野大小。通过这张图的方式得到右下角的感受野是不是就和右上角的人类视觉系统很像了呢。
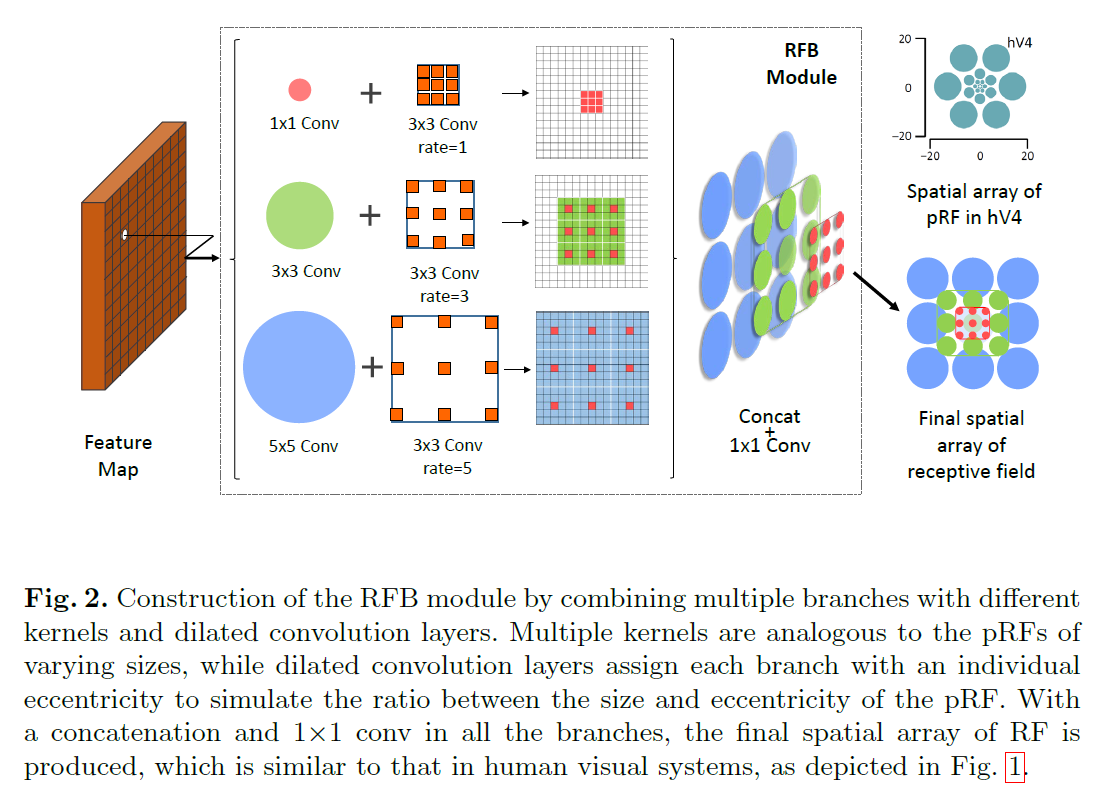
总结来看,RFB Block实际上就是两个部分
- 多分支的卷积
- dilated conv或者dilated pool
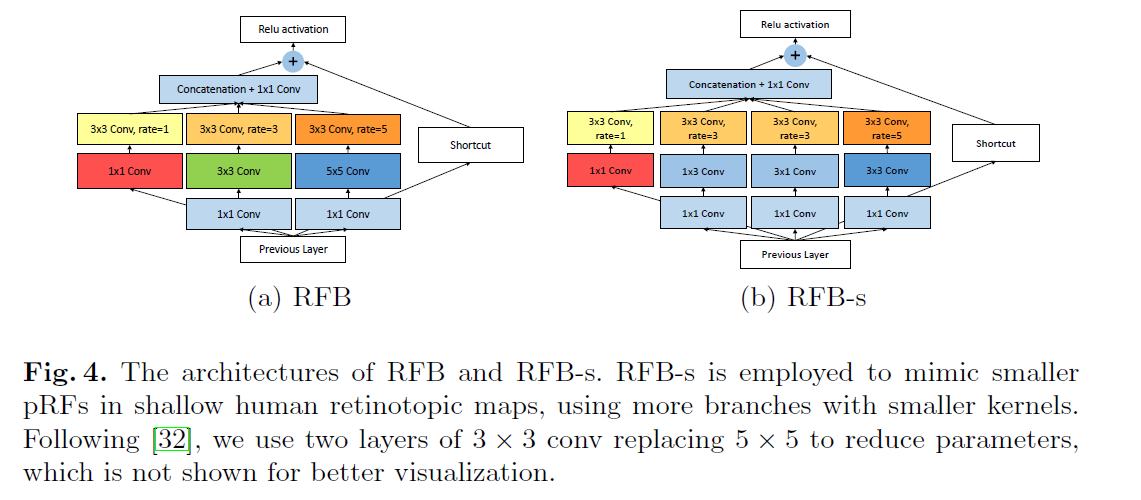
下图是作者设计的两种RFB结构,看图就很简单了,一目了然。(a)是比较普通版,(b)实际上就是参考inception进行升级版。rate代表的是dilated,rate=3代表dilated=3,最后的结果使用concat拼接到一起。
RFB in Detection
如下,便是作者在SSD-300进行的修改,其实主要做的东西就是将一部分卷积替换成了RFB结构,如下图已经很清晰了,不需要再详述了,注意观察RFB那几个框,作者不仅仅在分类检测分支使用了RFB,在主干也同样使用了RFB。
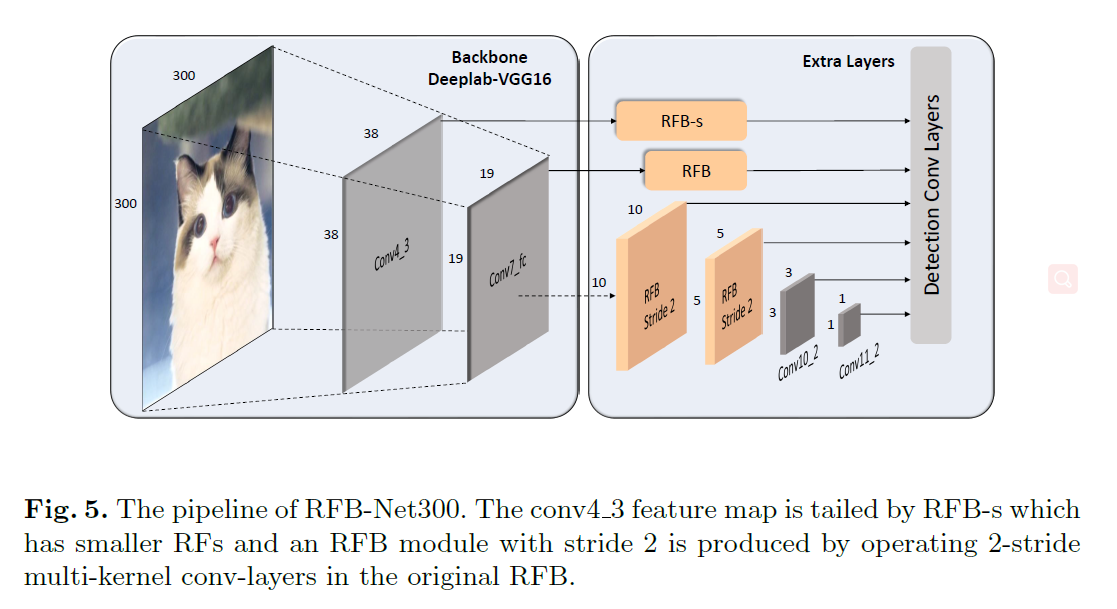
实验部分
作者在VOC上进行的实验
- warmup 5个epoch
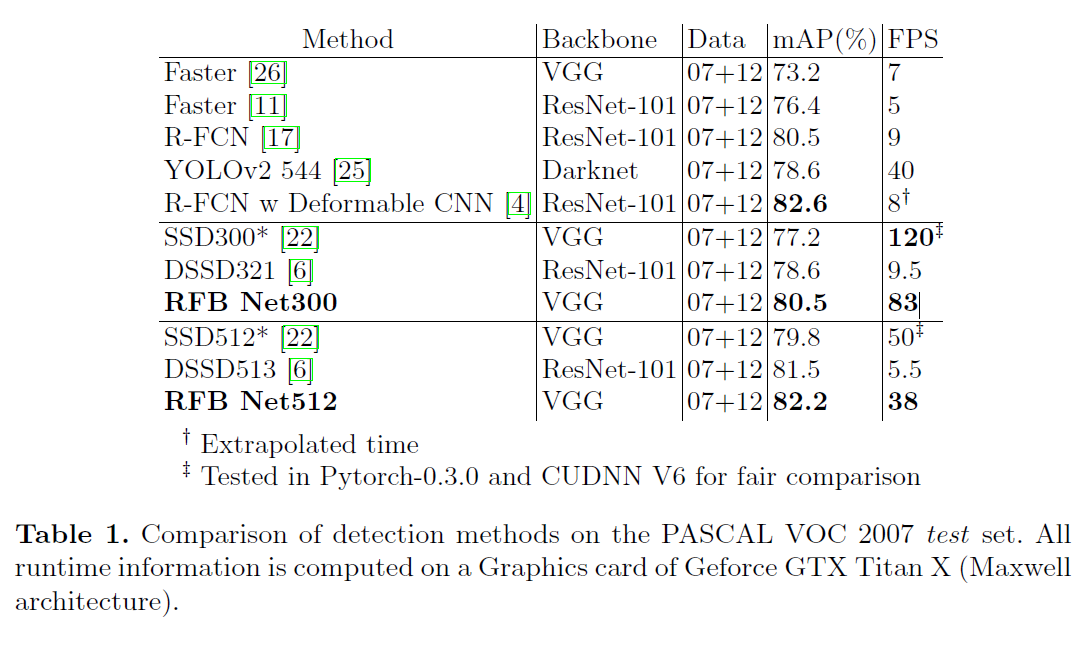
实验解析
- 其实从第一个实验RFB-max pooling已经显现出RFB的效果了。

与其他网络结构的对比
- 这里作者调整了网络结构,使得不同的网络参数量基本一致。
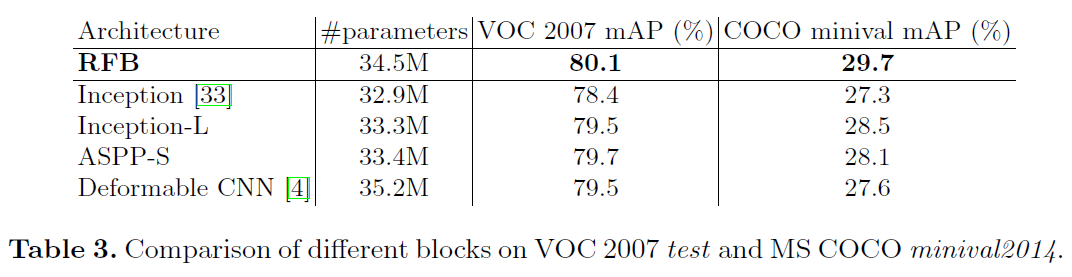
在COCO的实验结果:
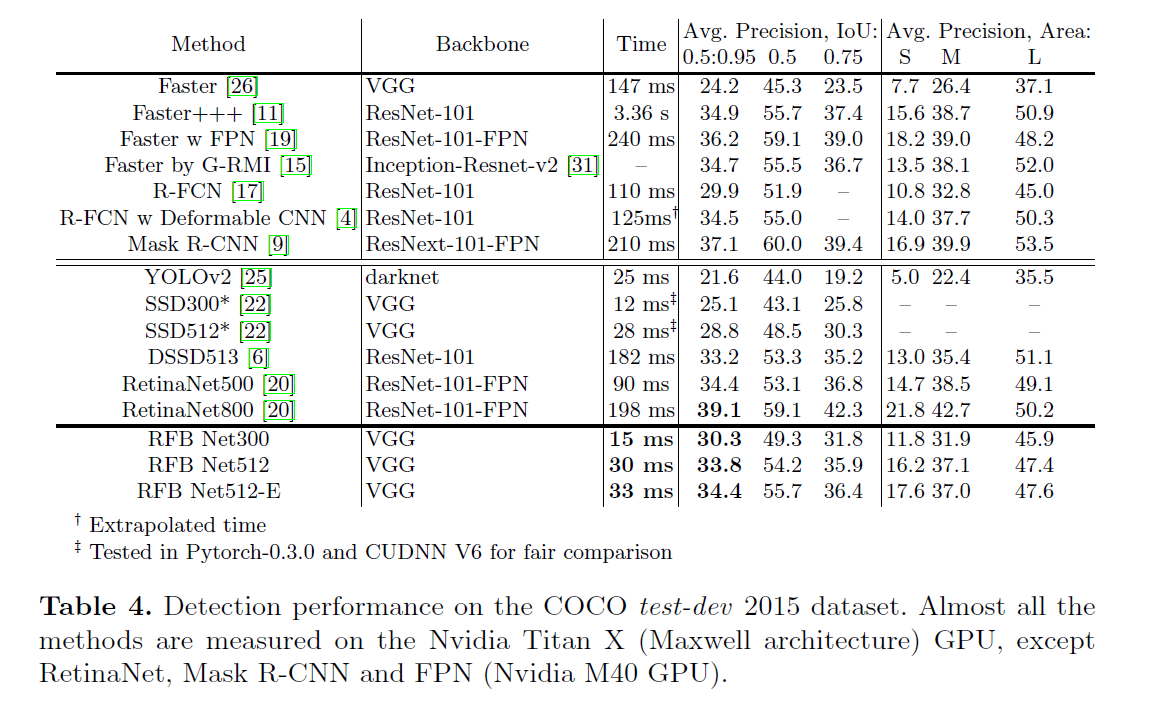
速度精度对比的一个图
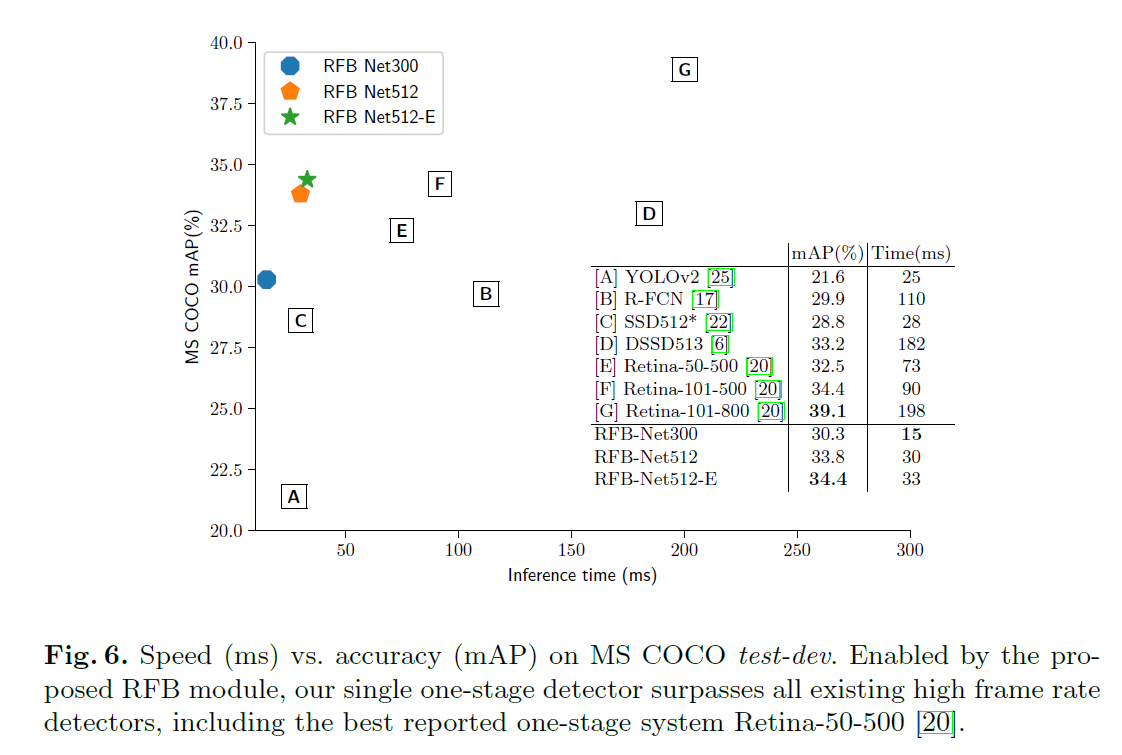
总结
总的来看,RFBNet的思想很简单,但是很新颖,并没有增加过多的东西,但是取得的效果还是很不错的,达到了一个速度与精度的平衡。