FoveaBox是CVPR2019的一篇anchor free的目标检测文章,其思想跟FCOS很相似,都是在RetinaNet的基础上,在不同stage输出的特征图上,直接得到目标类别并回归出目标的位置,相比FCOS,FoveaBox要更简单一些,FoveaBox在COCO的精度可以达到42.1。
作者:Tao Kong Fuchuan Sun 等
论文链接:https://arxiv.org/abs/1904.03797
代码链接:https://github.com/taokong/FoveaBox
Introduction
- 使用anchor的缺点
- 超参数的引入
- 泛化性不够,对不同的任务需要设计不同的anchor
- 正负样本不均匀
- 灵感来源
- MetaAnchor
- Guided-Anchoring
FoveaBox
在介绍FoveaBox之前,首先展示一张FoveaBox的结构图,如下。FoveaBox的整体结构跟RetinaNet基本一致,同样采用FPN结构,同样是不同的level分出两个subnet,一个用于预测类别,一个用于预测坐标框。不一样的地方在于,class subnet最后的输出这里是W*H*K,而RetinaNet是W*H*A*K,没有了anchor的参数A,box subnet的输出也是同理。
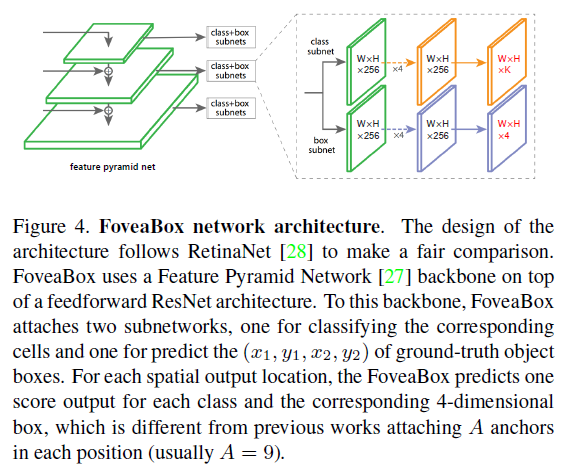
在FoveaBox中,共有5个level分出subnet,分别是$P_{l},l=3,4,…,7$,每个level输出的特征图的大小为$\frac{1}{2^{l}}$
Scale Assignment
由于目标尺寸变换范围较大,FoveaBox跟SSD方法一致,同样采用了不同的level预测不同尺寸的目标的方法,另外在FCOS中(一个跟FoveaBox很相似的anchor free目标检测方法),解释到,使用多level预测的目的是为了解决anchor free的时候,目标重叠的问题,因为重叠就没有办法分配正负样本了,这样可以有效减少目标重合。
这里作者将7个level的尺寸设置成$32^{2}$-$512^{2}$,用公式表示就是$S_{l}=4^{l}S_{0}$其中$S_{0}=16,l=3,4,…,7$,并且,为了控制不同level之间的重合度,作者增加了$\eta$参数,进一步调节不同level的尺度范围,$[\frac{S_{l}}{\eta_{2}},S_{l}\eta^{2}]$,通过调节参数,一个目标可能会在多个level中进行检测。
Object Fovea
接下来我们来看一下,Fovea在训练中如何定义正负样本。
Fovea是anchor free的,所以在计算正负样本的时候,不需要想anchor那样计算IOU,fovea直接将ground-truth映射到对应level的特征图上,公式如下:
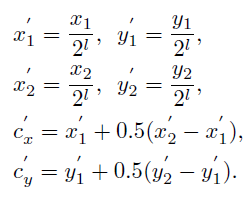
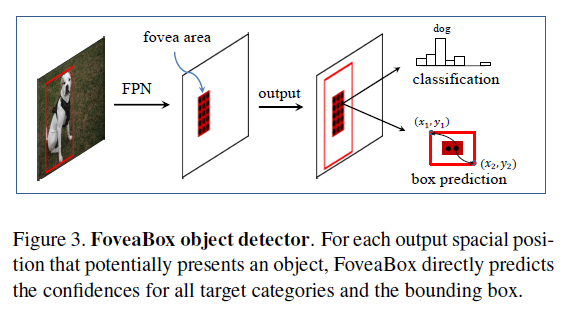
另外,在Fovea中,并不是ground-truth对应的区域均是正样本,如下图所示,狗虽然很大,但是真正的正样本,是中间红色区域部分,这也是fovea的精华,这里作者引入了个$\sigma$参数,可以根据参数,动态设置正样本范围。
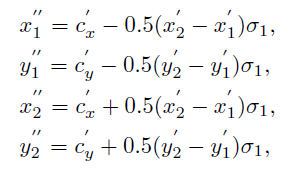
至于负样本,作者在上面公式中,设置$\sigma_{2}$,在$\sigma_{2}$之外的数据均为负样本,在作者的实验中$\sigma_{1}=0.3$,$\sigma_{2}=0.4$,位于0.3-0.4之间的区域就不参与训练了。由于仍然存在正负样本不均的情况,所以作者在训练分类的时候仍然采用了Focal Loss。
Box Prediction
在坐标预测上,FoveaBox中,在坐标预测方面,主要是通过学习了transformation函数来进行坐标的变换,如下,其中$z=\sqrt{S_{l}}$,x1等是Ground Truth,t代表网络输出,这里作者使用的是Smooth L1 loss作为计算坐标的loss函数。
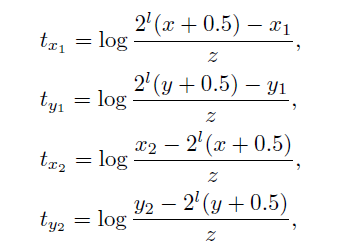
Inference
在inference的时候,首先使用阈值0.05,直接过滤掉不靠谱的点,然后在剩下的点中,选取得分排名前1000的点作为候选点,再然后,使用非极大值抑制,对这1000个点再次进行过滤,最后留下的top100个点作为最终的结果。
实验部分
Various anchor densities and FoveaBox
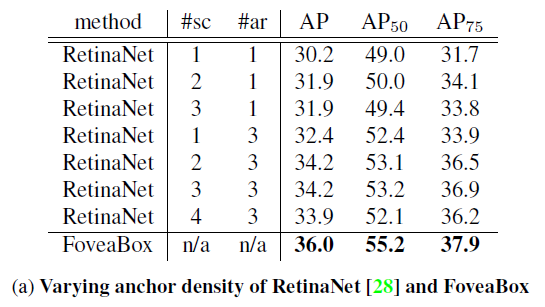
首先,anchor-based网络,一般跟anchor的选取有很大关系,那么fovea是不是比anchor-based方法更好呢?作者进行了实验,结果如下。可以发现,foveaBox比RetinaNet高的不是一点点。
Analysis of Scale Assignment
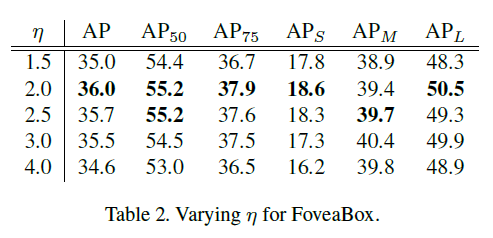
$\eta$控制着金字塔网络不同level的scale,到底选多少最为合适呢?下面的实验说明选择2是最为合适的。
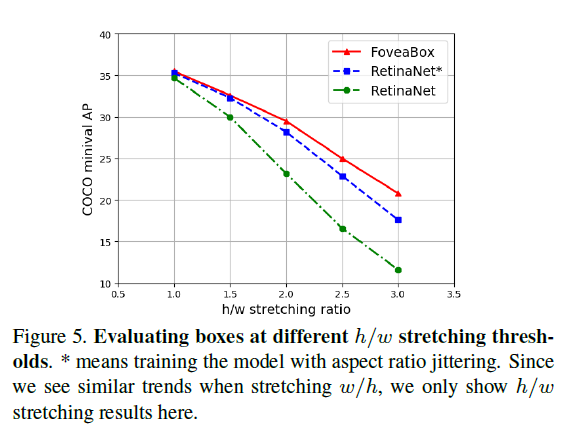
Fovea对于box是不是更鲁棒一些呢?
为此作者进行了实验,通过修改验证集的长宽比等。
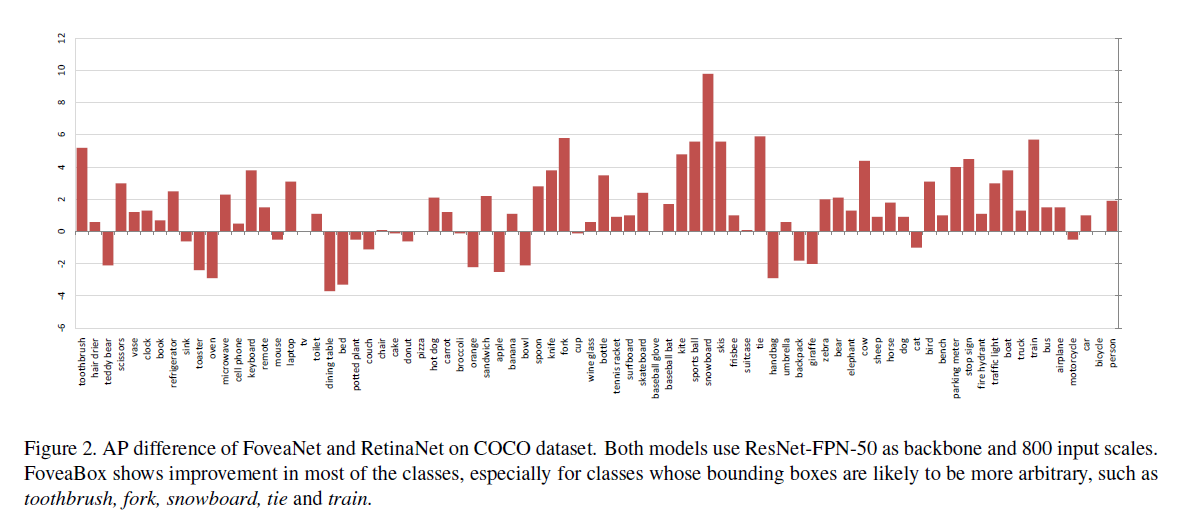
每个类别的差异
可见,大部分类别的效果都提升了。
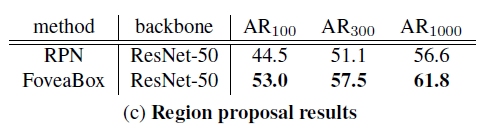
Fovea当做RPN效果
如果采用FoveaBox方式提取RPN效果如何呢?实验证明,效果要好于基于anchor的方法。
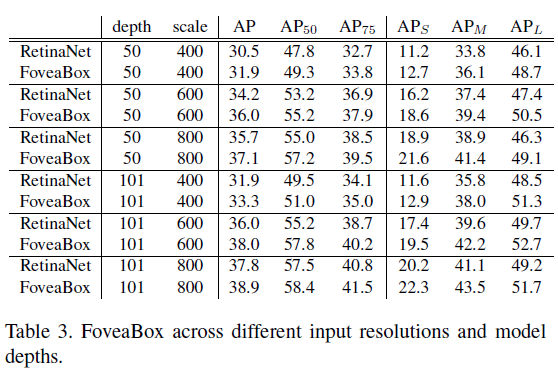
不同尺度与深度的Fovea效果对比
foveaBox效果还是不错的。
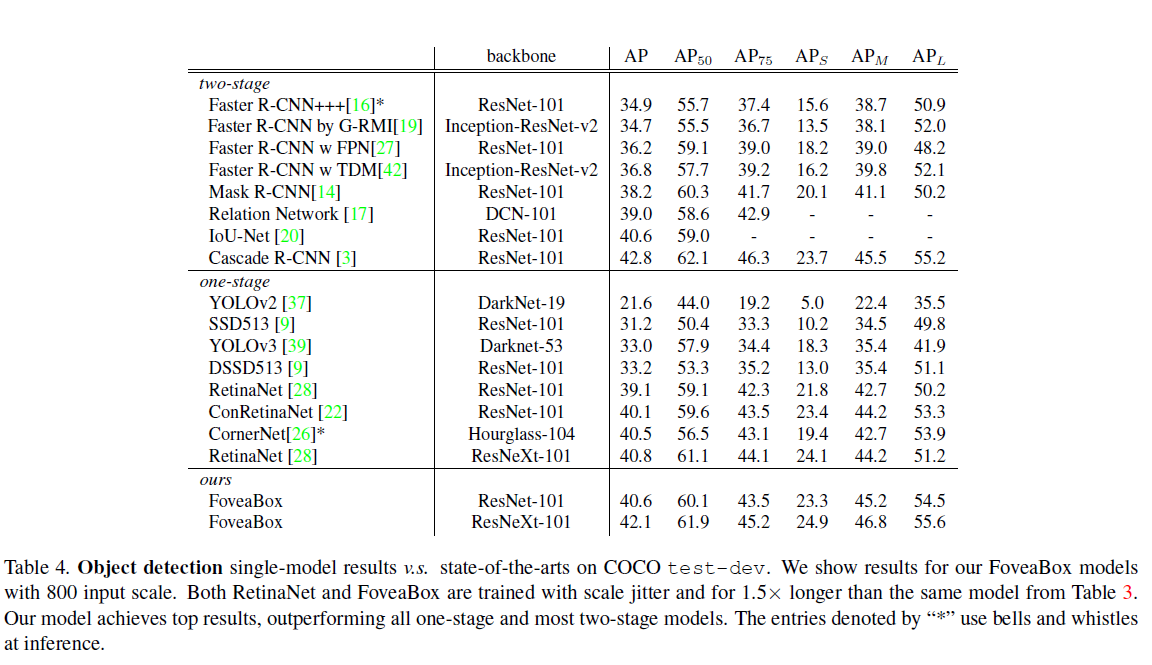
总结
文章整体来看,跟FCOS很像,思路基本一样,都是基于RetinaNet,同样是每一个location预测一个类别和四个坐标相关的数,只是FCOS预测到四个边界的距离,Fovea预测一个坐标转换。再有一个就是FCOS以gt boxes中的全部像素作为正例,而Fovea是采样了一个portion。其他关于FPN尺度分配的问题都是大差不差。