ACNet,借鉴了模型加速的一些方法,在原始的dxd的卷积上,通过增加并行的1xd以及dx1卷积(即AC Block),实现模型精度的增强,同时在部署阶段,又将dxd、1xd、dx1卷积通过公式进行合并计算得到新的dxd卷积,并没有增加原有dxd卷积的计算量以及inference的时间,精度速度双收,作者将ACBlock应用于多个网络,效果还是比较显著的,值得借鉴。
论文名称:ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks
作者:Xiaohan Ding & Yuchen Guo 等
论文链接:https://arxiv.org/abs/1908.03930
摘要
提升网络的精度以及速度,一直是广大研究人员孜孜不倦的追求。那么如何提升网络的精度?我们可以看看网络的发展,从VGG->ResNet->DenseNet->SENet->FPN等,网络的结构在逐渐的复杂,从VGG单纯的stack模式,到ResNet引入identity mapping,到DenseNet的Dense Connecting以及SENet的attention,FPN的不同特征图的叠加,网络的发展使其变得越来越复杂。那么如何提升网络的速度?模型压缩:剪枝、量化。总的来说,大体就是通过各种方法减少计算量,减少运算中的中间变量,减少网络的复杂度。
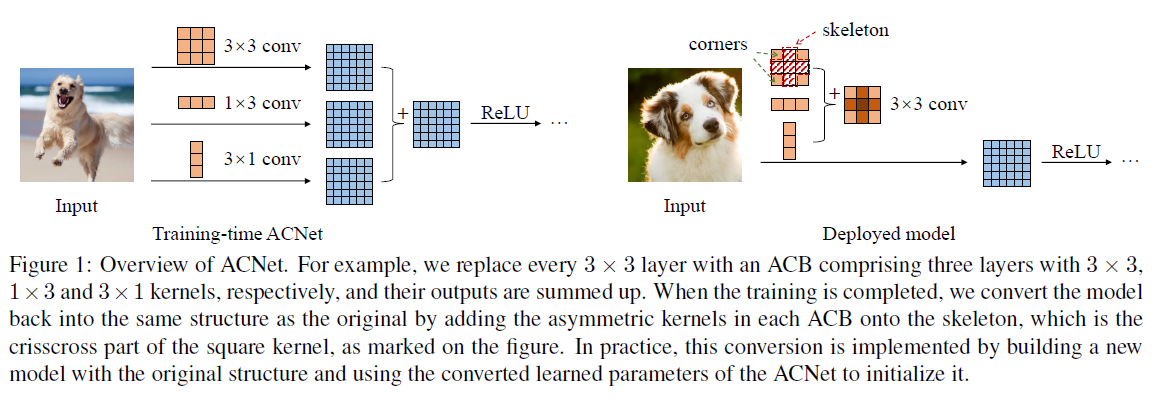
这篇文章的最大创新点就在于虽然对网络结构进行了稍微的修改,提出了ACB模块,(网络的修改,结合了Inception论文中的方法,还是挺巧妙的),提高了精度,但是在部署的时候,通过计算合并,并没有增加网络的计算量,保持了原来的速度,下图是ACB模块简单的图示,左边是训练时的结构,右面是部署时的合并。
ACB(Asymmetric Convolution Block)
如上图所示,ACB模块就是将原本dxd的卷积,修改为3个平行并列的卷积,分别为原来的dxd以及新增的1xd以及dx1,上图中的展示为d=3的情况,虽然d不限制,不过大部分网络d都是等于3的。然后将3个平行输出的特征图做相加操作。
ACB由于并没有对网络结构进行大的调整,仅仅是调整了3x3的卷积,所以ACB模块可以应用于任何现有的网络,只要替换卷积就可以了。
在inception v3中,已经使用过这种方法,利用1x7和7x1替换原有的7x7的卷积,减少参数量的同时并没有降低精度,但其中也提到替换的结构在网络的低层表现不是很好。
分支可以使用如下Pytorch代码实现,比较简单:
1 | branch3x3dbl_1 = conv_block(c3, c3, kernel_size=(3, 3), padding=(0, 0)) |
ACB其实比较简单,下面介绍一下fusion操作吧。
Fusion
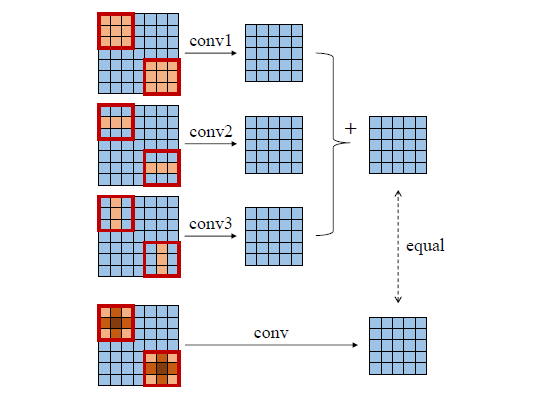
下图所展示的就是卷积的fusion,很好理解,不多介绍了。
卷积后面接BN是比较常见的操作,下面详细一下带BN的fusion,如下图所示,I代表特征图。
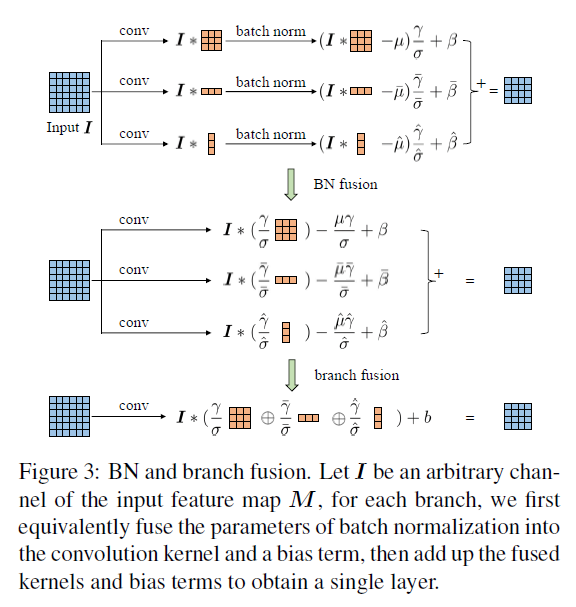
这张图已经很清晰的描述的计算过程,有的时候一图抵千言,第一行就是原始的操作,BN fusion,可以将每行的I提取出来,就变成了第二行,branch fusion就是将卷积操作合并到一起,然后将后面的参数统一计算成b,因为模型训练完成这些参数都是固定的,也就可以很方便的进行合并计算出来了,这是模型加速时候的常规操作。
还是比较简单的。
实验
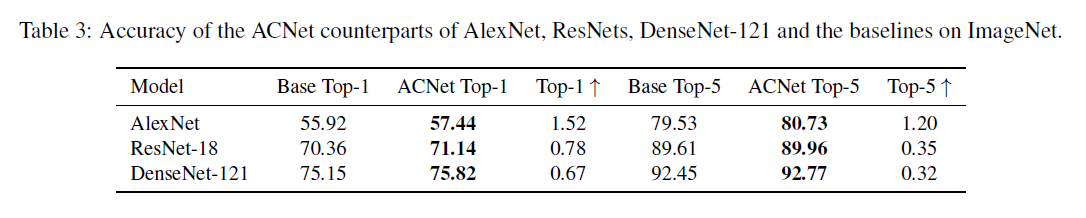
首先在ImageNet上面还是有效果的,可以看到不论是top1还是top5都有一定程度的提升。
加下来探索一下哪里产生的作用比较大
作者对比了如下三个变量:
- horizontal kernels
- vertical kernels
- batch normalization
可以发现,horizontal以及vertical kernels都会产生一定的积极效果,结合BN之后,效果就跟明显了。
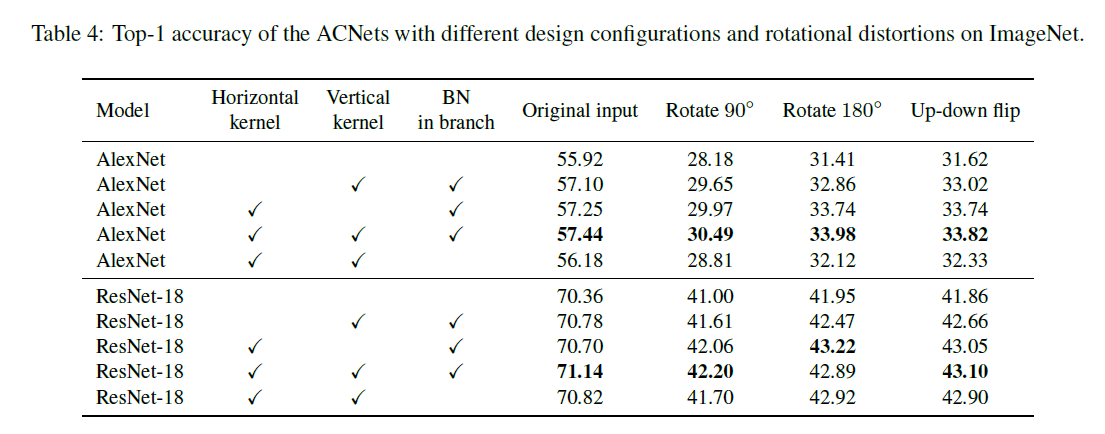
另外作者进行实验证明了卷积核的骨架的作用性,下面的实验中,作者在训练好的模型中,分别将卷积核的骨架随机置为0,角点随机置为0以及全部随机置为0,sparsity ratio代表将多少的比例设置为0。可以发现,骨架的影响是最大的,下降幅度非常快,而角点相对来说要慢一点。
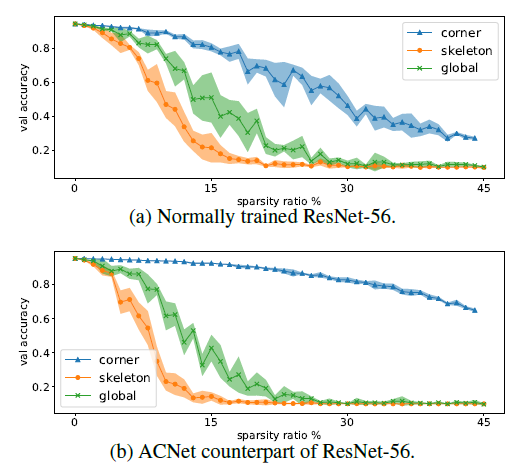
最后作者探究了kernel内值的重要性,采用的方法就是,利用所有数值的绝对值来当做当前kernel值的重要性,然后对所有的kernel首先进行归一化(layerwise),然后对经过归一化的kernel取均值得到最终的重要性,最终作者得到的结果如下:

可以看到,正常的kernel分布相对较平均,中间最大达到了0.9以上,其他的基本在0.8以上,但是ACNet使得骨架部分的权重明显增加,这也可以说明ACNet对于骨架部分的增强,使得模型效果的提升(上个实验已经证明了骨架的重要性)
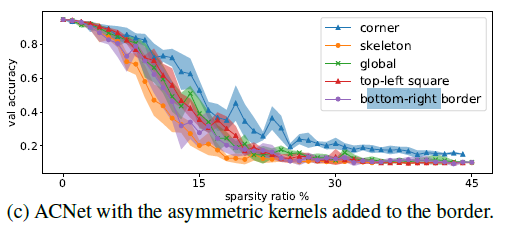
那如果ACNet不是在kernel骨架中间相加,而是在kernel的右下角相加呢?如上图figure 6(c)所示,实验证明,这样对于边界是具有一定的增强作用的,但是在CIFAR上面的表现没有在中间相加的效果好,并且同样采用上面将一部分kernel置为0的方法,结果如下图,右下角的影响变得很大,当然还是没有骨架大,进一步侧面说明的骨架的重要性。
总结
本文虽然方法都比较简单,但是关键在于想法很不错,利用增强骨架的能力提高模型的效果,同时在部署阶段,使用参数融合,减少计算量,还不影响速度,值得学习借鉴。