YOLO(You Only Look Once)是CVPR2016的一篇文章,是目标检测领域比较有名的的一篇文章,yolo出名不在于它的精度高,而在于他的速度很快,下面介绍的是yolo的第一版,在yolo之后,又改进出了yolo-v2,yolo-v3,v2,v3的精度相比较于v1就有大大提升了,这个后面再详细介绍。
在介绍yolo之前,首先引入一下目标检测的进展,yolo之前的目标检测一般是如何做的呢?
有两个代表:DPM以及RCNN系列
yolo是怎么做的呢?
yolo直接采用regression(回归)的方法进行坐标框的检测以及分类,使用一个end-to-end的简单网络,直接实现坐标回归与分类,如下图所示
yolo具体是怎么做的呢?
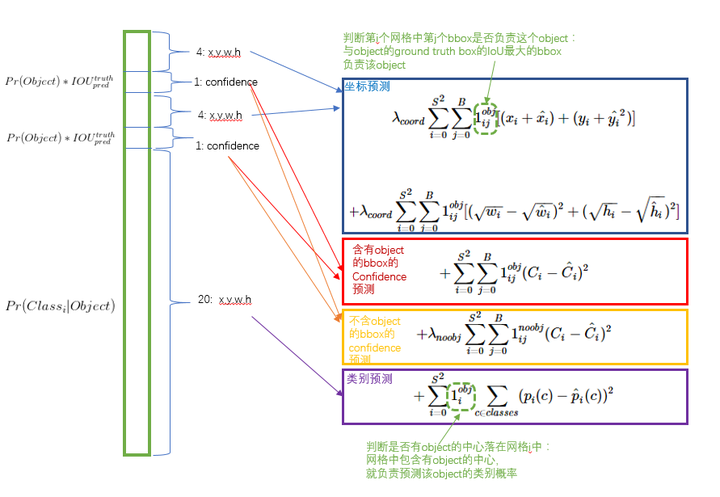
yolo首先将图像分割成S*S个grid(S默认取7),然后对每个gird,预测B个(bounding box + confidence),(B默认为2),confidence定义为$P_r(Object)*IOU_{pred}^{truth}$,如果不存在物体,则confidence为0,否则期望其为IOU,bounding box为:[x,y,w,h]其中(x,y)为object中心点坐标
每个gird另外预测C个类别的概率,作者在VOC上实验,所以C取为20(这里为什么不是类似Fast RCNN的21类,因为是否为背景,作者放到了上面的confidence中),
说这么多,大家可能不清晰,那具体的预测过程是怎么样的呢?下面展示一下
首先通过20个类与每个grid的2个预测bounding box的confidence相乘,得到该bounding box为每个类的概率,对每个grid都做该操作,将得到7*7*2=98个向量,如下图黄色矩形所示,其中,每一列代表每个预测的bounding box为各个类别的概率值,每一行【下面图中么有行,可以看下2张图 】对应每个类别,以下2张图中第一个图为例,第一行便对应于dog的概率,第一列则对应于bounging box1.
然后,通过阈值以及非极大值抑制(这步骤比较简单,详细操作过程可以参考这个ppt链接:yolo操作详细演示PPT ,这里就不详细介绍了),将无用的位置为0。
对每一列,找到最大值,并判断score是否为目标。
说完了预测过程,那么yolo是如何训练的呢
yolo的基础网络灵感来源于GoogLeNet,但是并没有采取其inception的结构,而是简单的使用了1×1的卷积核。base model共有24个卷积层,后面接2个全连接层,如下图所示。
在训练网络的时候,作者首先用ImageNet预训练前20个卷积层,作者训练的结果是top-5 accuracy = 88%
训练好分类网络后,进行检测的训练,由于检测一般需要较大的分辨率,所以作者将输入图像大小修改为448*448
另外yolo并没有使用Relu激活函数,而是使用了leaky rectified linear激活函数,如下:
在损失函数的设计上,作者选择均方误差作为损失函数。
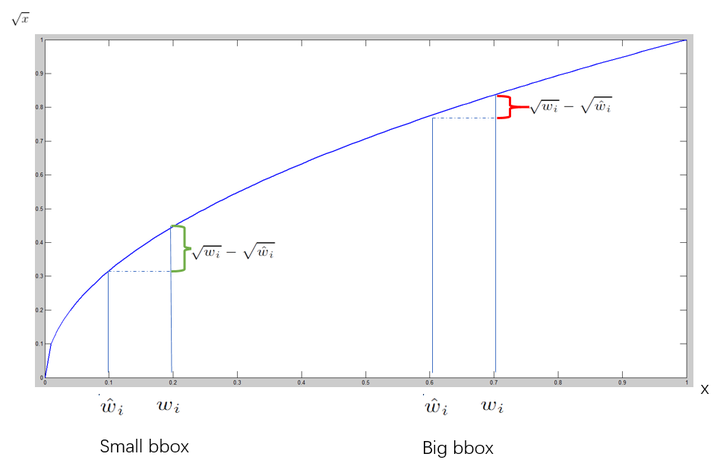
但是,仅仅使用均方误差带来了一些问题,如果分类和定位使用同样权重的loss,结果会不理想,在图像中,很多的grid是不包含物体的,这会将confidence score降为0,同时压制了那些有物体部分的梯度,会导致模型不稳定,所以作者修改了检测与分类的loss的权重,增加了bounding box的权重同时减低了没有物体的confidence权重,作者设置$\lambda_{coord}=5,\lambda_{noobj}=0.5$并且不同大小的box同样会带来loss的影响(比如同样是相差10个像素,如果大矩形的大小为100,小矩形的大小为10,那么对于大矩形只相差了0.1,而小矩形相差了1倍),所以作者采用平方根来削弱这个影响
最后得到损失函数如下:
这个损失函数是不是特别美~~
训练细节:
data : VOC2007以及VOC2012
实验结果
首先秀一张识别精度图,YOLO虽然没有Fast R-CNN的mAP高,但是效果挺好的
另外作者通过实验发现,YOLO的精度不高但是对于background的错检率要高于fast rcnn,如下图所示:
其中
Correct: correct class and IOU > 0.5
Localization:correct class 0.1 < IOU < 0.5
Similar : class is similar ,IOU > 0.1
Other : class is wrong ,IOU > 0.1
background: IOU < 0.1 for any object
进而作者想到了将fast rcnn与yolo相结合以提高精度,实验结果证明,确实有提升
到这基本就介绍完yolo了,总结一下yolo特点:
1.yolo很快,base yolo 45 frames per seconds , fast yolo 可以达到155 frames per seconds, on a Titan X GPU
2.yolo不同于sliding window以及region proposal方法在训练和检测的时候只能看到局部图像,而yolo可以看到全局图像,(这也是导致后面实验中Fast R-CNN的将背景检测错误的概率要高于yolo的原因)两个 全连接层,yolo通过reshape将全连接的结果对应回原图的7*7,使得其可以看到全局的特征
3.yolo具有较强的泛化能力,对于艺术品同样具有较好的检测效果
补充说明
yolo反向传播的时候如何计算梯度呢?
yolo最终的输出,实际是全连接层,reshape的结果只是方便与前面映射回去,所以在计算梯度的时候,对loss进行求导,在全连接层相应位置映射回去便可以了。
forward_detection_layer函数中,delta为梯度,读者可执行对应其计算过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 detection_layer make_detection_layer(int batch, int inputs, int n, int side, int classes, int coords, int rescore) { detection_layer l = {0 }; l.type = DETECTION; l.n = n; l.batch = batch; l.inputs = inputs; l.classes = classes; l.coords = coords; l.rescore = rescore; l.side = side; l.w = side; l.h = side; assert (side*side*((1 + l.coords)*l.n + l.classes) == inputs); l.cost = calloc(1 , sizeof(float )); l.outputs = l.inputs; l.truths = l.side*l.side*(1 +l.coords+l.classes); l.output = calloc(batch*l.outputs, sizeof(float )); l.delta = calloc(batch*l.outputs, sizeof(float )); l.forward = forward_detection_layer; l.backward = backward_detection_layer; l.forward_gpu = forward_detection_layer_gpu; l.backward_gpu = backward_detection_layer_gpu; l.output_gpu = cuda_make_array(l.output, batch*l.outputs); l.delta_gpu = cuda_make_array(l.delta, batch*l.outputs); fprintf(stderr, "Detection Layer\n" ); srand(0 ); return l; } void forward_detection_layer(const detection_layer l, network net) { int locations = l.side*l.side; int i,j; memcpy(l.output, net.input , l.outputs*l.batch*sizeof(float )); //if (l.reorg) reorg(l.output, l.w*l.h, size*l.n, l.batch, 1 ); int b; if (l.softmax){ for (b = 0 ; b < l.batch; ++b){ int index = b*l.inputs; for (i = 0 ; i < locations; ++i) { int offset = i*l.classes; softmax(l.output + index + offset, l.classes, 1 , 1 , l.output + index + offset); } } } if (net.train){ float avg_iou = 0 ; float avg_cat = 0 ; float avg_allcat = 0 ; float avg_obj = 0 ; float avg_anyobj = 0 ; int count = 0 ; *(l.cost) = 0 ; int size = l.inputs * l.batch; memset(l.delta, 0 , size * sizeof(float )); for (b = 0 ; b < l.batch; ++b){ int index = b*l.inputs; for (i = 0 ; i < locations; ++i) { int truth_index = (b*locations + i)*(1 +l.coords+l.classes); int is_obj = net.truth[truth_index]; for (j = 0 ; j < l.n; ++j) { int p_index = index + locations*l.classes + i*l.n + j; l.delta[p_index] = l.noobject_scale*(0 - l.output[p_index]); *(l.cost) += l.noobject_scale*pow (l.output[p_index], 2 ); avg_anyobj += l.output[p_index]; } int best_index = -1 ; float best_iou = 0 ; float best_rmse = 20 ; if (!is_obj){ continue ; } int class_index = index + i*l.classes; for (j = 0 ; j < l.classes; ++j) { l.delta[class_index+j] = l.class_scale * (net.truth[truth_index+1 +j] - l.output[class_index+j]); *(l.cost) += l.class_scale * pow (net.truth[truth_index+1 +j] - l.output[class_index+j], 2 ); if (net.truth[truth_index + 1 + j]) avg_cat += l.output[class_index+j]; avg_allcat += l.output[class_index+j]; } box truth = float_to_box(net.truth + truth_index + 1 + l.classes, 1 ); truth.x /= l.side; truth.y /= l.side; for (j = 0 ; j < l.n; ++j){ int box_index = index + locations*(l.classes + l.n) + (i*l.n + j) * l.coords; box out = float_to_box(l.output + box_index, 1 ); out.x /= l.side; out.y /= l.side; if (l.sqrt){ out.w = out.w*out.w; out.h = out.h*out.h; } float iou = box_iou(out, truth); //iou = 0 ; float rmse = box_rmse(out, truth); if (best_iou > 0 || iou > 0 ){ if (iou > best_iou){ best_iou = iou; best_index = j; } }else { if (rmse < best_rmse){ best_rmse = rmse; best_index = j; } } } if (l.forced){ if (truth.w*truth.h < .1 ){ best_index = 1 ; }else { best_index = 0 ; } } if (l.random && *(net.seen) < 64000 ){ best_index = rand()%l.n; } int box_index = index + locations*(l.classes + l.n) + (i*l.n + best_index) * l.coords; int tbox_index = truth_index + 1 + l.classes; box out = float_to_box(l.output + box_index, 1 ); out.x /= l.side; out.y /= l.side; if (l.sqrt) { out.w = out.w*out.w; out.h = out.h*out.h; } float iou = box_iou(out, truth); //printf("%d," , best_index); int p_index = index + locations*l.classes + i*l.n + best_index; *(l.cost) -= l.noobject_scale * pow (l.output[p_index], 2 ); *(l.cost) += l.object_scale * pow (1 -l.output[p_index], 2 ); avg_obj += l.output[p_index]; l.delta[p_index] = l.object_scale * (1. -l.output[p_index]); if (l.rescore){ l.delta[p_index] = l.object_scale * (iou - l.output[p_index]); } l.delta[box_index+0 ] = l.coord_scale*(net.truth[tbox_index + 0 ] - l.output[box_index + 0 ]); l.delta[box_index+1 ] = l.coord_scale*(net.truth[tbox_index + 1 ] - l.output[box_index + 1 ]); l.delta[box_index+2 ] = l.coord_scale*(net.truth[tbox_index + 2 ] - l.output[box_index + 2 ]); l.delta[box_index+3 ] = l.coord_scale*(net.truth[tbox_index + 3 ] - l.output[box_index + 3 ]); if (l.sqrt){ l.delta[box_index+2 ] = l.coord_scale*(sqrt(net.truth[tbox_index + 2 ]) - l.output[box_index + 2 ]); l.delta[box_index+3 ] = l.coord_scale*(sqrt(net.truth[tbox_index + 3 ]) - l.output[box_index + 3 ]); } *(l.cost) += pow (1 -iou, 2 ); avg_iou += iou; ++count; } } if (0 ){ float *costs = calloc(l.batch*locations*l.n, sizeof(float )); for (b = 0 ; b < l.batch; ++b) { int index = b*l.inputs; for (i = 0 ; i < locations; ++i) { for (j = 0 ; j < l.n; ++j) { int p_index = index + locations*l.classes + i*l.n + j; costs[b*locations*l.n + i*l.n + j] = l.delta[p_index]*l.delta[p_index]; } } } int indexes[100 ]; top_k(costs, l.batch*locations*l.n, 100 , indexes); float cutoff = costs[indexes[99 ]]; for (b = 0 ; b < l.batch; ++b) { int index = b*l.inputs; for (i = 0 ; i < locations; ++i) { for (j = 0 ; j < l.n; ++j) { int p_index = index + locations*l.classes + i*l.n + j; if (l.delta[p_index]*l.delta[p_index] < cutoff) l.delta[p_index] = 0 ; } } } free(costs); } *(l.cost) = pow (mag_array(l.delta, l.outputs * l.batch), 2 ); printf("Detection Avg IOU: %f, Pos Cat: %f, All Cat: %f, Pos Obj: %f, Any Obj: %f, count: %d\n" , avg_iou/count, avg_cat/count, avg_allcat/(count*l.classes), avg_obj/count, avg_anyobj/(l.batch*locations*l.n), count); //if (l.reorg) reorg(l.delta, l.w*l.h, size*l.n, l.batch, 0 ); } }