本篇论文是亚马逊MXNet团队的又一力作,目前预训练模型已经在MXNet官网上面公布,从效果上看,网络的精确度提升还是很明显的,实现了较好的speed与accuracy的trade-off。精度提升的点主要在于两方面,一方面resnest使用了前面MXNet团队总结的训练模型的tricks,另一方面设计了split-attention block结构,在并没有改变resnet原始结构的情况下,提高了网络的识别能力。并且ResNeSt可以轻易的移植到其他的使用resnet作为backbone的任务中,比如目标检测、分割、姿态估计等,非常方便。
作者:亚马逊MXNet那帮人
论文链接:https://arxiv.org/abs/2004.08955
开源代码:https://github.com/zhanghang1989/ResNeSt
ResNeSt介绍
ResNeSt可以说是亚马逊在上一篇训练方法总结论文的又一升级版,没有看过那篇文章的小伙伴可以点击链接查看,这篇论文总结了一些训练模型时候提点的trick,还是很实用的。在ResNeSt这篇文章中,作者不仅采用了哪些tricks,而且提出了Split-Attention block方法,可以实现feature-map groups间的attention,提高识别能力的同时还保留了resnet的结构,使得其可以轻易替换任何的以resnet为backbone的模型,而且模型的效率也跟resnet差不多,这就非常的人性化了。
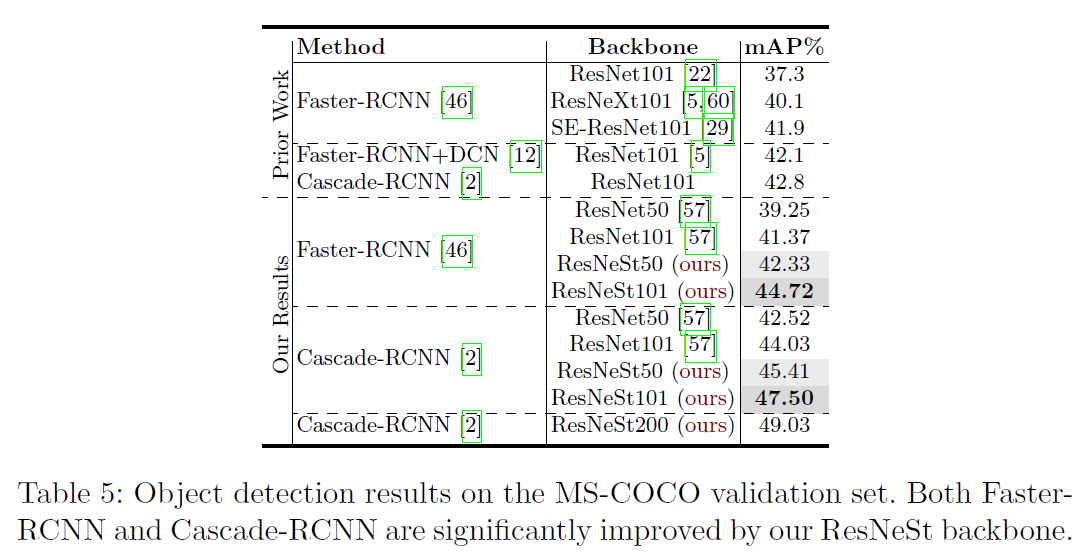
ResNeSt的表现也是out performance的,ResNeSt-50在ImageNet上可以达到81.13%的准确率。将Faster-RCNN的backbone由resnet50替换成resnest50,模型在MS-COCO的map可以从39.3%提升到42.3%,提升3个点,效果明显的,可以一试。
ResNeSt在accuracy与latency的表现可以看下图的分析结果。并且在检测以及分割上都有不错的表现。

ResNeSt创新点
Split-Attention Block
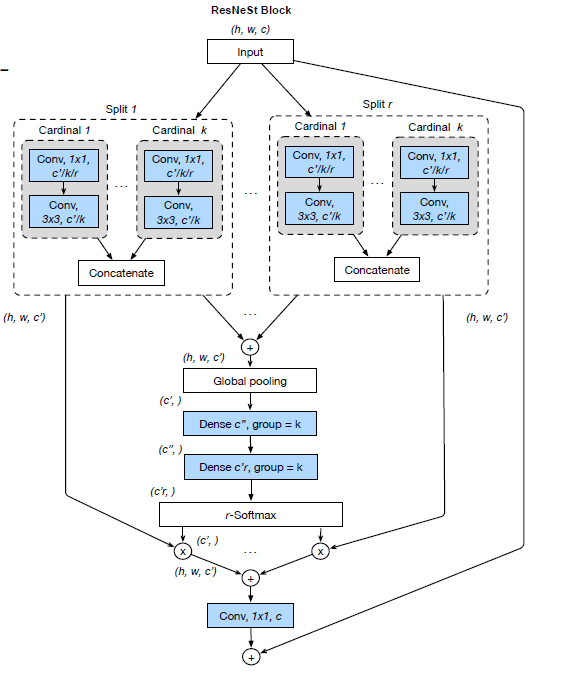
首先介绍一下Split-Attention Block,在介绍Split-Attention Block之前,首先介绍一下Feature-map Group的概念,什么是Feature-map Group呢?这个概念是在ResNeXt中提出的,简单来说就是分组卷积中的那个‘组’的概念,在ResNeXt中,‘组’被称cardinality参数所划分。在ResNeSt中,作者同样引入了cardinality,不仅如此,作者在每个组内,进一步引入了radix参数,在组内实现了二次划分,相当于做了两级分组卷积,所以,在ResNeSt中的最终分组数为Group=Cardinality * Radix,简单记为G=C*R.
在每个Group内,特征图依次通过1x1和3x3的网络。
如下图所示,可以看到ResNeSt中的Cardinality以及Radix参数。看图可以发现在分组之后,Cardinality组内是通过Split Attention进行特征融合的,那么这个Split-Attention是怎么做的呢?
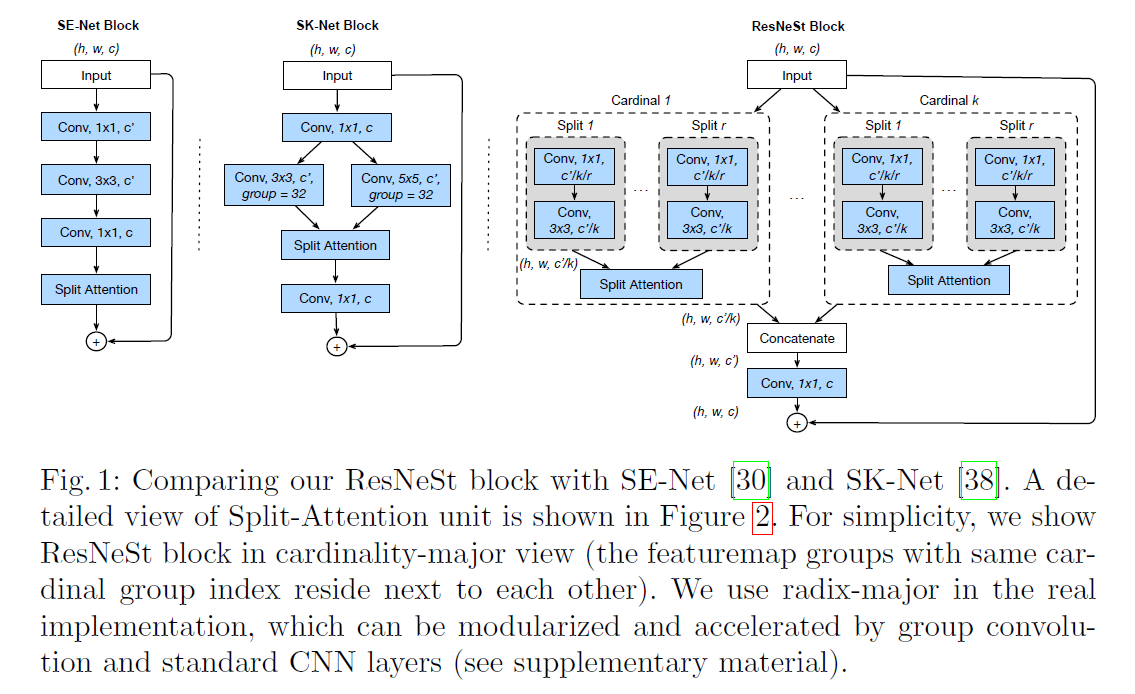
接下来介绍一下本篇文章的重点:
- Split-Attention。
- cardinality组内的attention
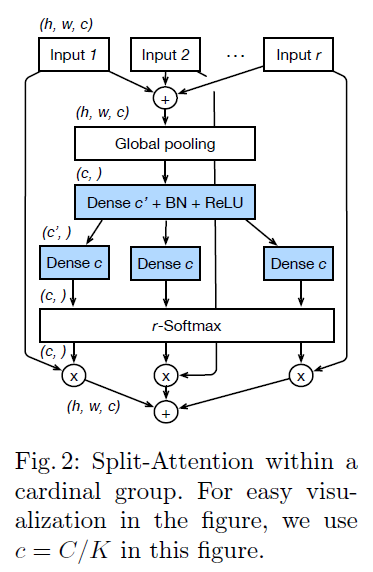
这个可以参考上面的流程图,首先对每组的输出进行element-wise summation,用以融合不同特征图的特征。然后通过Global pooling得到全局统计信息,进而通过一层全连接层+bn+relu,然后再通过一层全连接层得到加softmax,计算出各个组的attention值,然后对原来的输入进行加权,得到输出结果后进一步求和得到最终的输出结果。
总体来看,跟senet有点像,只不过多了一些分组求和的操作,如果将radix=1,那么就跟senet基本一致了。另外senet是使用sigmoid计算激活值,而resnest使用的是softmax来计算激活值,更增加了channel之间的联系,这里会有不同。
看代码就很清晰了。
1 | def forward(self, x): |
- cardinality组间的concat
在每个Cardinality组内做好attention之后,通过concat将特征图进行合并。
同样的的,跟resnet一样,每个block会有一个identity map。
另外,虽然看起来分组进行attention好像挺复杂的,但是其实,它完全可以通过分组卷积,以及分组全连接以及softmax来实现,计算效率不会因为分支多而受到影响。
其他tricks
其他的一些tricks设计,可以参考开头提到的那篇亚马逊mxnet团队的训练技巧的总结文章,都应用到了resnest上面,包括label smoothing, mixup,v1d结构等。
另外还有一个auto augmentation,就是通过自动搜索的方法,去检索最合适的24个augment,然后训练的时候随机的选择augment
实验结果
首先跟其他的resnet网络变种相比,resnest的精度还是很具有竞争力的。
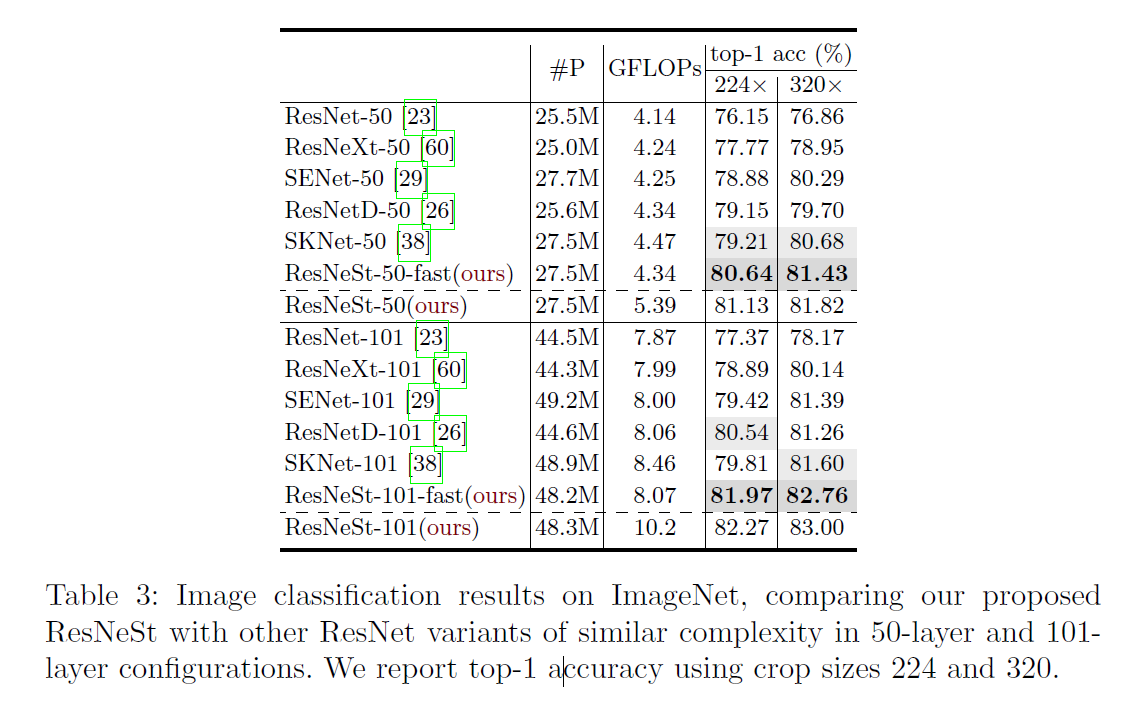
跟目前stage of art网络对比结果如下:可见resnest在速度精度也都表现的很出色。
其中的resnest-fast网络就是将计算attention中的下采样放到3x3之前,减少计算量,gluoncv中提供的预训练模型都是放在之前的
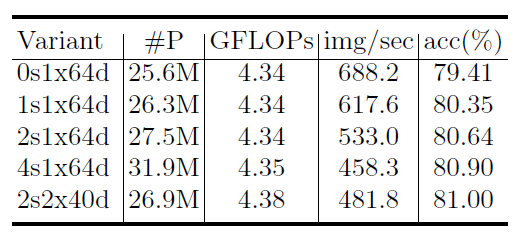
- radix与cardinality的对比
对比结果如下:其中s代表radix,x代表cardinality,d代表网络的width, 0s代表的就是标准的residual block,经过对比2s1x64d,是一个比较好的速度与精度平衡的选择。

- 在检测网络的表现
附录
实际上在实现的过程中,是采用下图所示的网络结构实现的,更有利于使用模块化的处理方式以及GPU加速。为啥这种方法更有利于模块化呢?看图可以看出来,其实它只进行了一次split-attention,而cardinality-major方法(论文中介绍的)进行了多次的split-attention,自然并行化要差一些。