这篇文章读下来,感觉就是一个tricks的集大成,作者实验做的可是真的很详细,好多trick我都没有听过,我看网上有人评论说,可以当做目标检测的入门手册了,哈哈,确实,能做如此多的实验,足见作者的功底。总体来说,文章的创新点不是特别多,大多是在试各种tricks,然后找到效果最好的,文章值得好好的读一读。
论文名称:YOLOv4: Optimal Speed and Accuracy of Object Detection
作者:Alexey Bochkovskiy & Chien-Yao Wang 等
论文链接:https://arxiv.org/abs/1903.00621
介绍
本文主要创新点在于干了下面几件事
1、YOLOv4,训练方便,1个1080或者2080就可以训起来了。
2、对比了很多tricks,验证了一些trick的影响,并选取了较好的tricks的组合。
3、优化了一些现存的方法,使其可以高效的训练在单个GPU上。
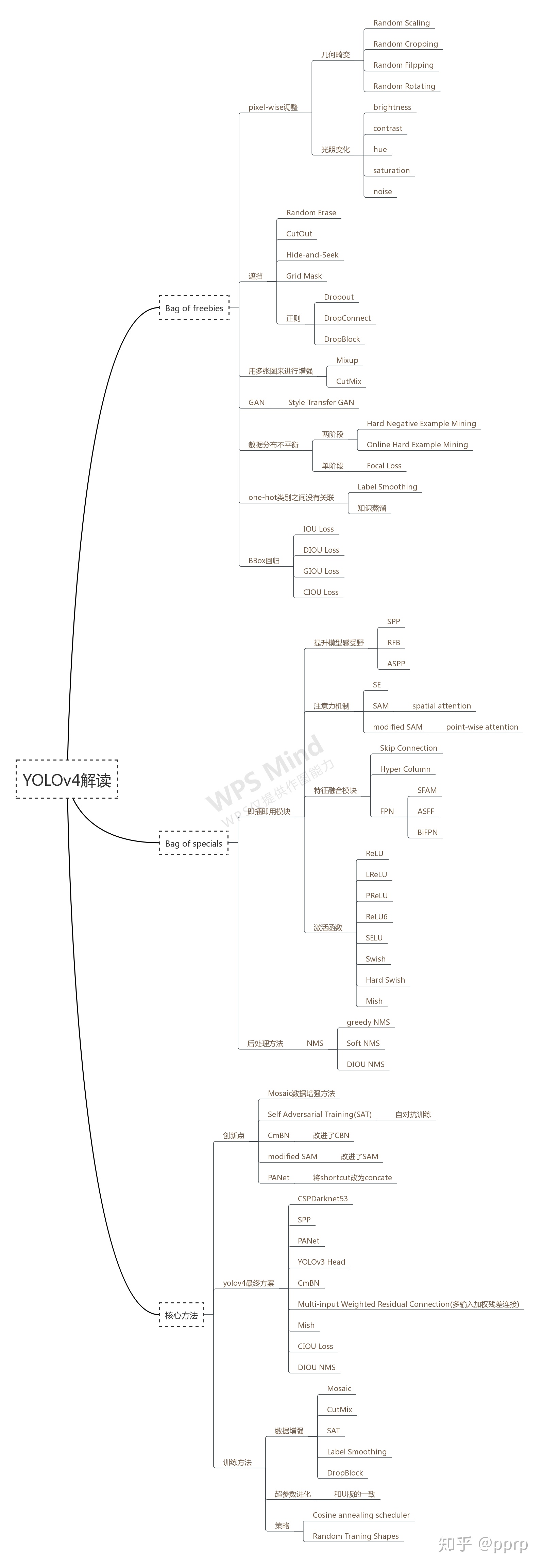
目标检测的网络结构
下图很清晰的描述了目标检测网络的结构,包括backbone,neck,head等。
bag of freebies
什么是bag of freebies呢?就是那些会提高模型效果,但是又不会增加模型部署后latency的方法。
- data augmentation
- random erase、cutout: 随机选取一个矩形,置为0
- hide-and-seek、grid mask: 选取多个举行区域,并置为0
- DropOut、DropConnect、dropBlock
dropblock很简单,就是随机的drop一块信息,因为采用dropout,虽然随机关闭了部分的神经元,但是其旁边的神经元依然可以传递信息,所以dropblock关闭一块区域,阻断信息的传播。
- MixUP
- CutMix
- style transfer GAN
下图示例了一部分augment方法

- problem of semantic distribution bias, data imbalance between different classes
- hard example mining
- focal loss
- label smoothing
- bbox regression
- IOU loss
- GIOU loss
$GIOU = IOU -\frac {A_c - U} {A_c}$
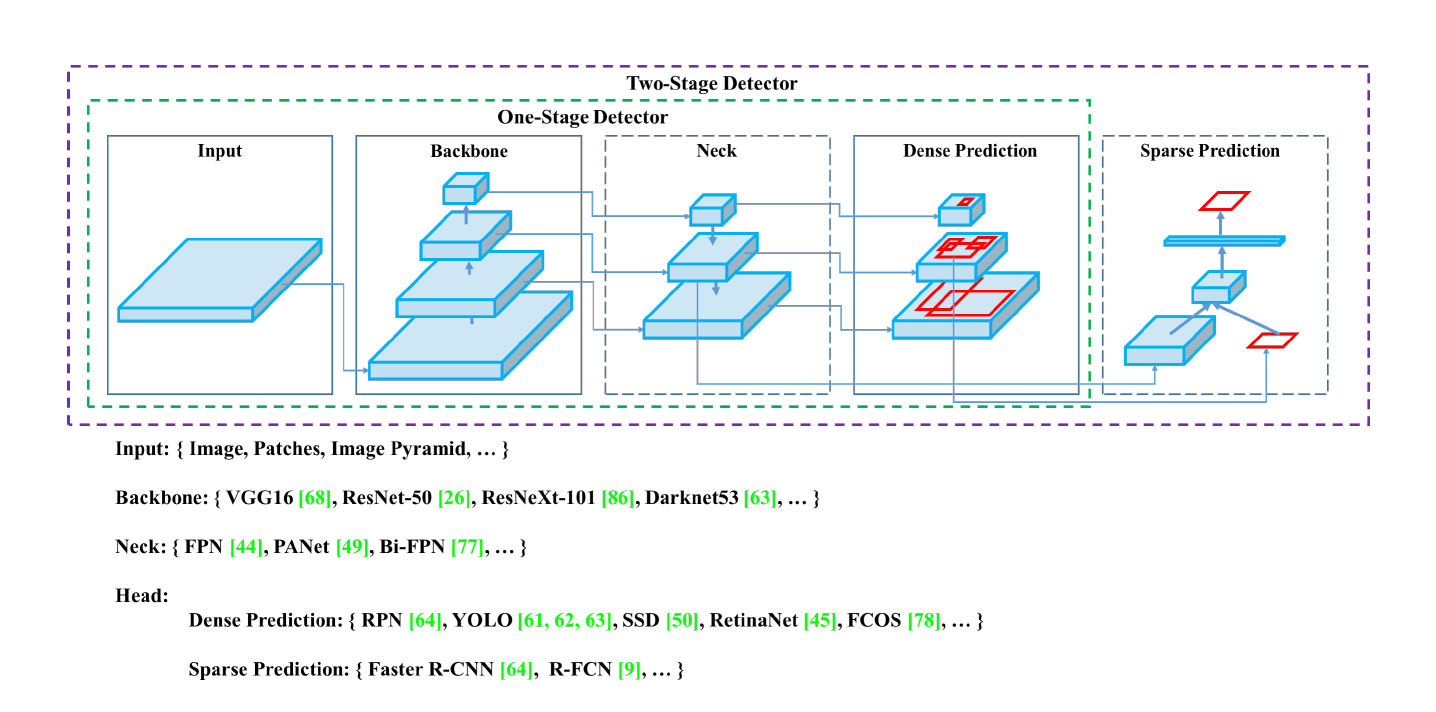
- DIOU loss
- CIOU loss
bag of specials
- 增加感受野
- SPP,
- ASPP,
- RFB
- attention
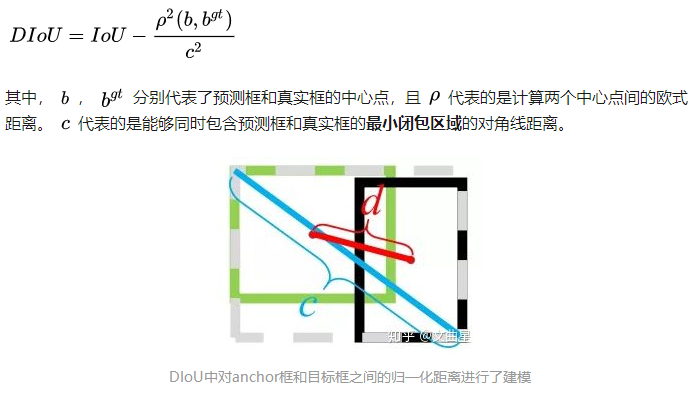
- channel-wise atention (SENet)
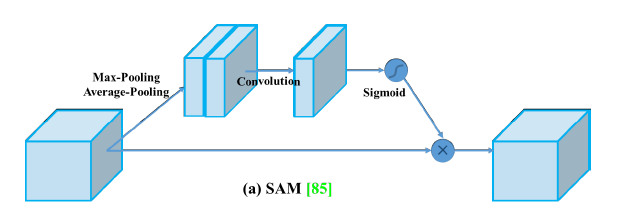
- point-wise attention :SAM(Spatial Attention Module)
SAM介绍:作者表示不仅在channel层面在spatial层面上也需要网络能明白feature map中哪些部分应该有更高的响应。具体怎么做的呢?如下图,首先,还是使用average pooling和max pooling对输入feature map进行压缩操作,只不过这里的压缩变成了通道层面上的压缩,对输入特征分别在通道维度上做了mean和max操作。最后得到了两个二维的feature,将其按通道维度拼接在一起得到一个通道数为2的feature map,之后使用一个包含单个卷积核的隐藏层对其进行卷积操作,要保证最后得到的feature在spatial维度上与输入的feature map一致,最后通过sigmoid对原来的特征图进行加权。
- activation function
- ReLU
- LReLU
- PReLU
- ReLU6 : quantization network
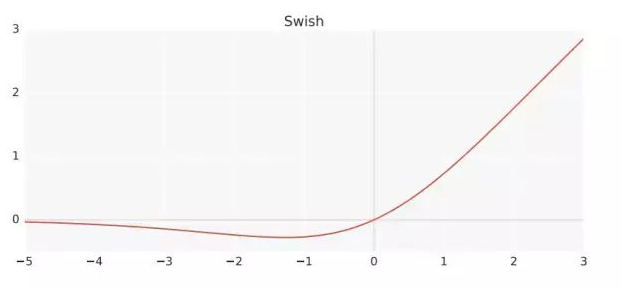
- Swish
$x*sigmoid(x)$
- hard-Swish : quantization network
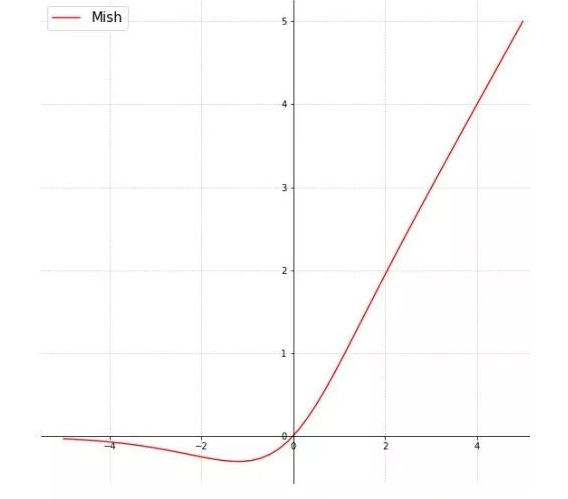
- Mish
$mish=x*tanh(ln(1+e^x))$
4. nms
- soft nms
- DIoU NMS
方法分析
相比较分类,检测模型应该需要哪些:
1、更大的输入尺寸,充分保证小尺寸图像的检测能力。
2、更大的感受野more layers
3、更多的参数
最优化的分类模型,不一定适用于检测模型中。
YOLO v4
- backbone : CSPDarknet53
- neck : PANet path-aggregation neck
- head : anchor based head , as YOLOv3
- no cross-gpu batch normalization
- DropBlock
- Mosaic
- Self-Adversarial Training(SAT)
- modified SAM, PAN and Cross mini-Batch Normalization(CmBN)
backbone如下

Mosaic
就是拼图,好处就是减小了目标的尺寸,同时变相增大了batchsize

- Self-Adversarial Training(SAT)
这个有点意思,简单的说就是对一张图像,首先利用网络的参数给原图像增加噪声,类似与攻击,增加其识别难度,然后在对其进行识别,以提高网络的识别能力,有意思。
- Cross mini-Batch Normalization
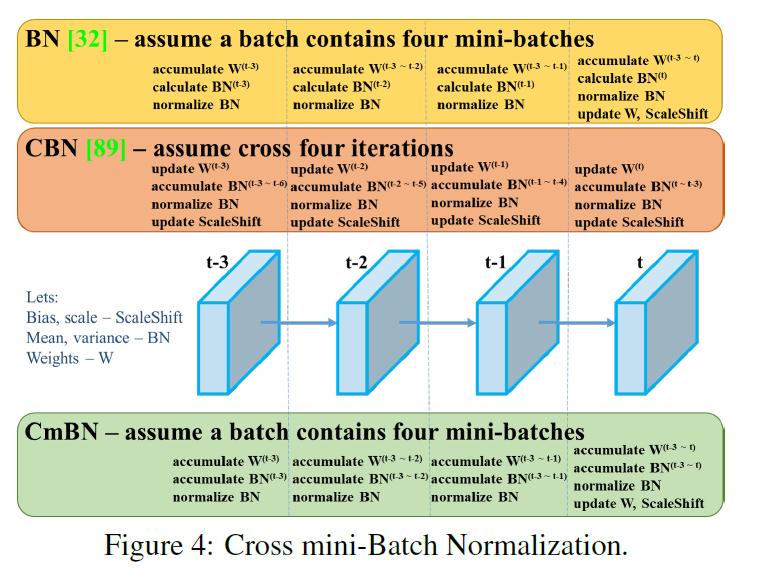
原始的BN层是在每个mini-batch中计算BN
CBN的提出是因为当模型较大的时候,单张卡的batch较小,影响模型效果,所以CBN不仅仅利用当前的mini-batch,还利用上几个iter的mini-batch,使得batch变得大一些。
CmBN类似于BN的升级版,只在mini-batch内部累加BN
- SAM的修改
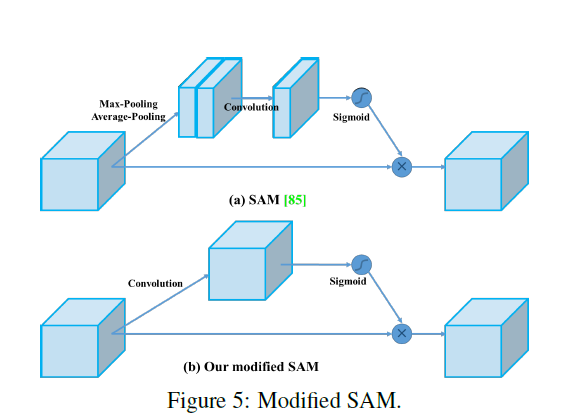
如图所示,将pooling 修改成了卷积,修改后就变成了point-wise的attention。
- PAN的修改

PANet原始结构: 自顶向下 自下上顶
实验部分
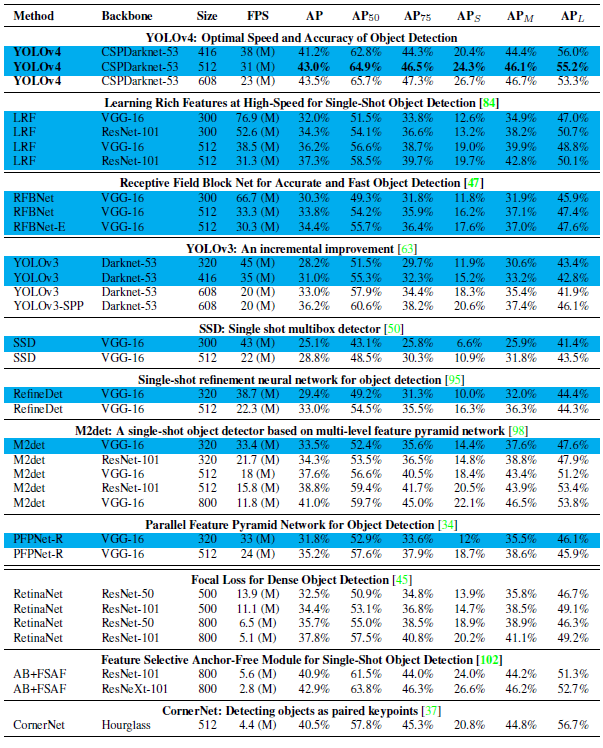
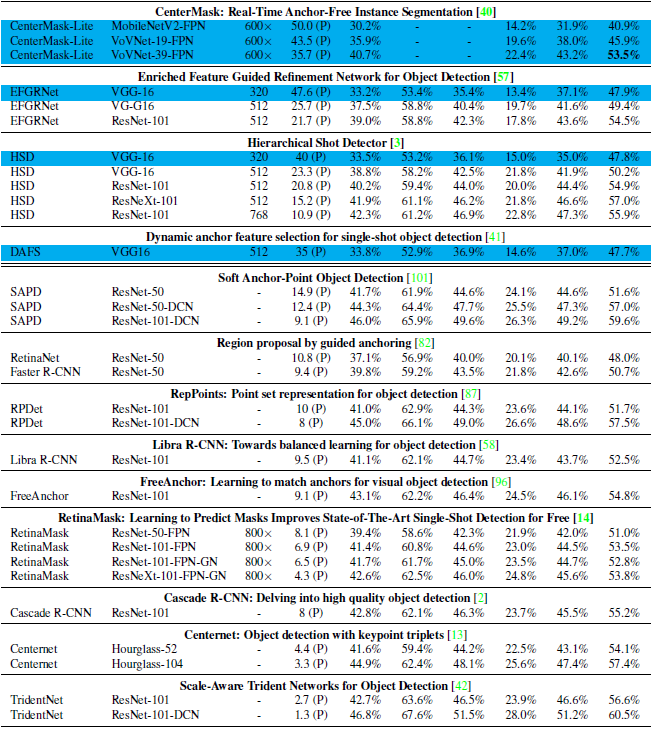
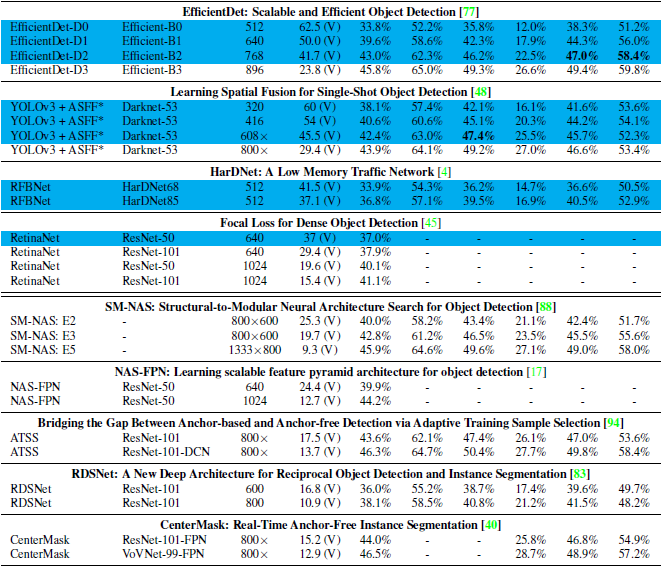
作者的实验做的是真的很全,对比的很充分,感兴趣的同学可以自行阅读一下,这里不介绍了,总之就是各种trick的对比。
最后放一下,不同网络的对比结果。
总结
下面是网上网友总结的YOLO-V4的tricks,很全,大家可以按图查询,查缺补漏。