这是一篇比较经典的半监督的论文,利用弱Aug与强Aug对无标签数据进行打标,然后用弱Aug的结果来监督强Aug的结果,来训练模型,思想很简单,值得一提的是,在计算softmax loss的时候,温度是个不要被忽略的参数!!
论文名称:FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
作者:Kihyuk Sohn
论文链接:https://arxiv.org/abs/2001.07685
Github:https://github.com/google-research/fixmatch.
Abstract
- FixMatch first generates pseudo-labels using the model’s predictions ==on weakly-augmented== unlabeled images.
- only retained high-confidence prediction
- use strongly-augmented to pseudo-label images to train model
- 这篇论文很多idea 来源于mixmatch 和 remixmatch ,建议看一下这两篇论文。
Introduction
- 数据难标,特别是专业的数据更难标,比如专业的医学图像。
- FixMatch, produces artificial labels using ==both consistency regularization and pseudo-labeling==.
- Inspired by UDA [54] and ReMixMatch [3], we leverage ==Cutout [14], CTAugment [3], and RandAugment [11]==for strong augmentation
- fewer additional hyperparameters
FixMatch
Background
- consistency regularization: 就是同一张图像的不同变换,输出的结果应该是一致的。
- p-labeling: 打伪标签,保留高阈值。
FixMatch
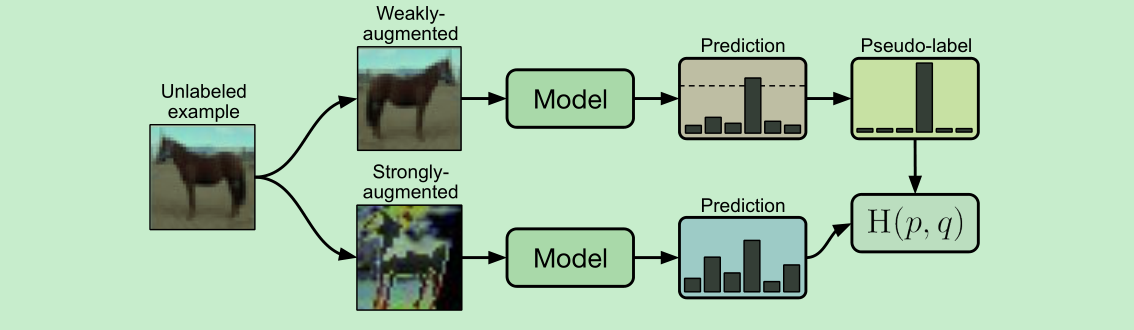
- 包含两个损失,分别是labeled data(==weakly augmented==)的 cross-entropy 以及 unlabeled data cross-entropy
- 关键点: unlabeled data的标签,先通过weakly-augmened得到,然后最后计算loss的时候,是通过strongly-augment得到的。
Augmentation in FixMatch
- weak aug: flip and shift
- strong aug: RandAugmnet + Cutout
- Augmentation anchoring,来自 remixmatch论文,就是先采用简单的数据增强来得到p-label
Additional important factors
- regularization is particularly important, should use simply weight decay regularization.
- SGD is good
- cosine learning rate decay
Related work
- Unsupervised Data Augmentation (UDA) [54] and ReMixMatch [3]. They both use a weakly-augmented
example to generate an artificial label and enforce consistency against strongly-augmented examples
Experiments
- 竞品: Π-Model [43], Mean Teacher [51],Pseudo-Label [25], MixMatch [4], UDA [54], and ReMixMatch [3].
- CTAugment 和RandAugment的效果比较相似
- 结果如下:(Error rates)
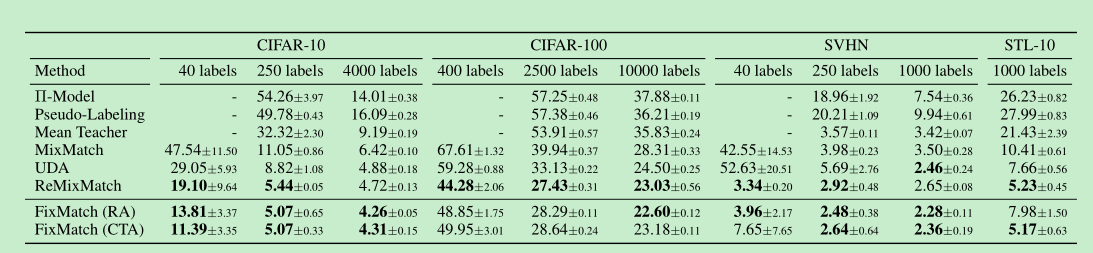
- 在cifar-100上,remixmatch比fixmatch好一些,实验发现是==Distribution Alignment==(这个东西可以看一下remixmatch论文,就是利用有标签的数据类别分布,去对无标签的label进行干预)操作带来的
- 在imagenet上,S4L效果比较好,是因为S4L在训练后,又用p-label retrain了一下,以及supervised finetune
算法流程

Ablation Study
- sharpering and thresholding , sharpening是啥意思呢?就是使用参数T来控制softmax输出的形状,在蒸馏中也有使用,蒸馏中的T是大于1的,使得分布更加平缓,而这里的T是小于1的,使得分布更加的尖锐。
- cutout 和ctaugment都很重要,去了谁都会掉点。
- weakly aug 不能太强,太强了模型不收敛了,如果weakly 没有aug了,容易过拟合。
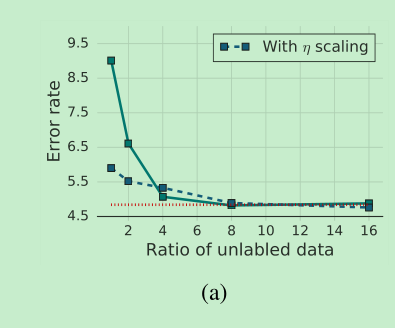
- unlabeled data 和 labeled data的比例,8以上就比较稳定了。
- 训练细节的总结:

总结
- 这篇文章的方法竟然能train起来,还真的想尝试尝试,这篇文章主要将p-label与self-training的方法进行了结合。有哪些值得我们学习的呢?1、利用简单的aug来产生p-label,然后利用更强的aug来计算loss,增加难度。weakly_aug以及strong_aug的一致性检验;hard-label与p-label一起进行训练。sharpering and thresholding这个方法可以借鉴一下。其实就是针对unlabeled的数据利用上,使用了consistent 的方法,做consistent是针对强弱的数据增强方法。总体思想就是:unlabeled主要是学习特征,然后label进行分类提升。
代码阅读
1 | for batch_idx in range(args.eval_step): |