本文的提出,主要借鉴于Network slimming以及rethinking the value of pruning network这两篇文章,文章的观点在于,我是不是有必要在预训练模型上面剪枝,是否可以在随机初始化的模型上面直接剪枝,本文经过证明,得出的结论是可以的,并且剪枝后的模型效果并不比在预训练模型上面剪枝的效果差。
论文名称:Pruning From Scratch
作者: Yulong Wang 等
论文链接: https://arxiv.org/abs/1909.12579
github :https://github.com/zheng-ningxin/Pruning-from-scratch (没找到官方的,找了个非官方的)
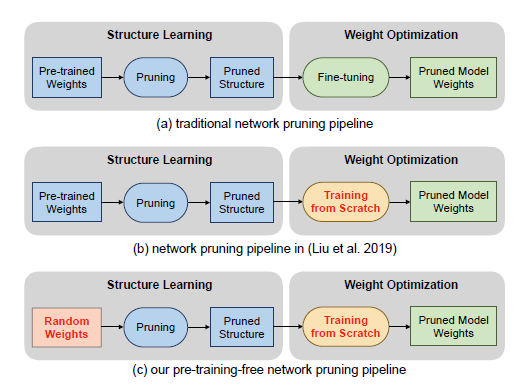
传统的剪枝套路如上图(a),一般是在预训练模型上面剪枝,然后剪完之后利用finetune将精度训练上去。上图(b)所示的方法是rethinking the value of pruning network的方法,即剪完之后不一定非得利用原来的参数进行finetune,可以重头开始训练,也会得到相近甚至更好的结果。图(c)就是本文证明的方法了,在剪枝之前,也可以不使用训练好的模型,而是在随机初始化的模型上面直接进行剪枝。
作者为什么会有这个出发点呢?原因在于作者发现,从预训练的模型进行剪枝的模型,剪枝结果趋于同质化,比较难发现更好的结构,这其实限制了剪枝的效果。基于此,作者尝试在没有训练过的模型进行剪枝。
预训练的参数对剪枝结果的影响
为了验证预训练的参数对剪枝结果的影响,作者进行了实验,下面这张图是作者分别进行的随机初始化以及预训练模型的剪枝结果的相关系数,可以发现,采用预训练模型后,剪枝的模型很相似,没有明显差别,而随机初始化的模型,显然不同的随机,结果差别大一些。
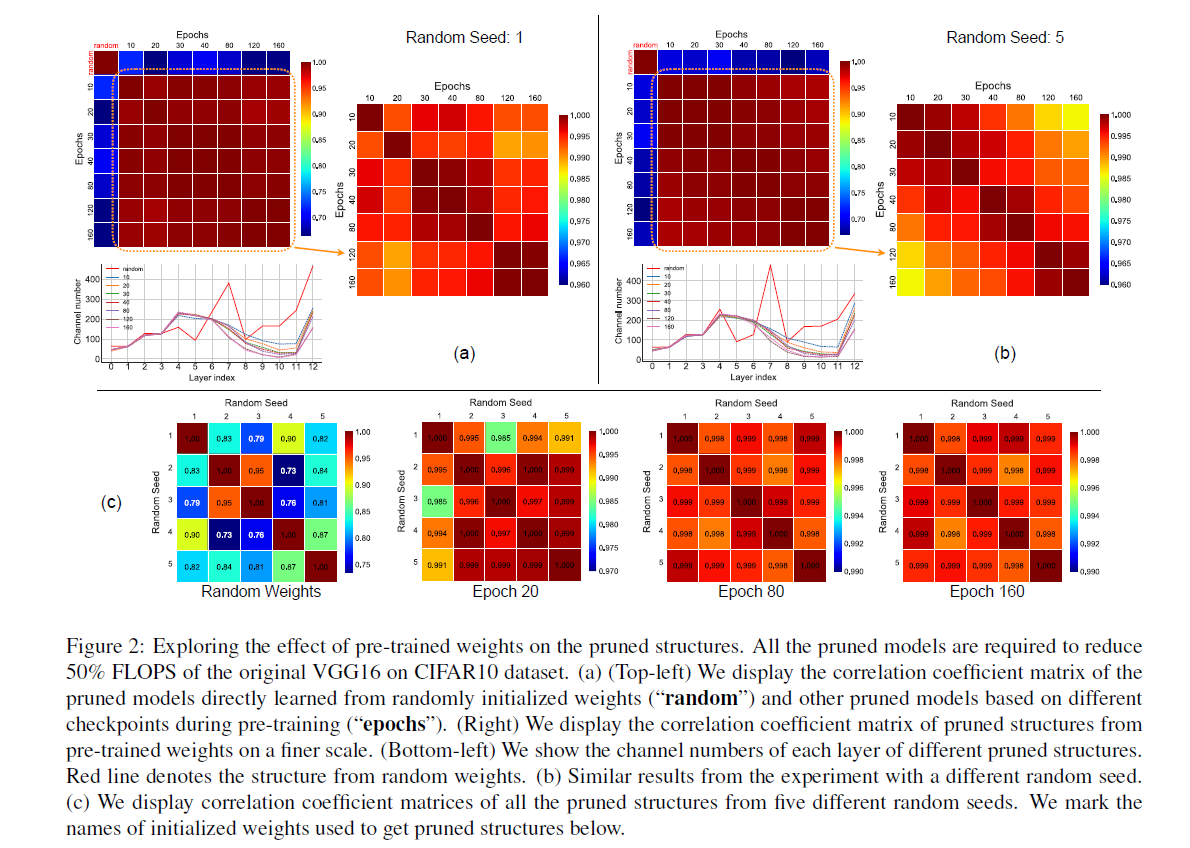
于是作者得出结论:
(1)随机初始化的剪枝结果,跟不随机初始化的剪枝结果的差别还是很大的。
(2)随机初始化的剪枝结果,回存在更大的差异化。
(3)训练10个epoch之后的模型,剪枝结果就具备一定的相似性了。
所以,预训练之后,实际上是在减少剪枝空间,限制了剪枝的潜在表现。换言之,随机初始化,其实更有利于发现更多更大的剪枝空间。
随机初始化对于剪枝结果的影响?
下面实验可以发现,rand的效果跟pre-trained的效果差不多:
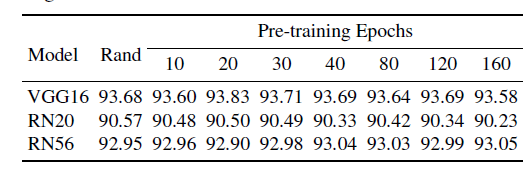
所以,剪枝完全可以从random开始嘛。
剪枝细节
剪枝的关键在于如何找到重要性较弱的节点,network slimming是一个比较著名的方法,作者本篇也参考这个方法,通过lamda来控制channel的稀疏性,将不重要的channel干掉。
训练的时候,在学习channel重要性的时候,网络的weights不需要更新。
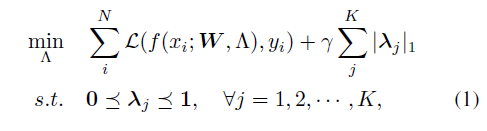
作者采用类似与network slimming的方法,但是没有采用原始的L1正则,因为其稀疏化不受控制,效果不是特别的好。
作者修改成了如下:
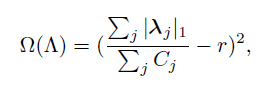
r 是目标稀疏系数, Cj是每个layer的channel数量。
接下来的问题是,在训练好的稀疏矩阵之后,剪枝阈值怎么定?这里作者采用了个二分法来定阈值,找到需求的目标裁剪比例
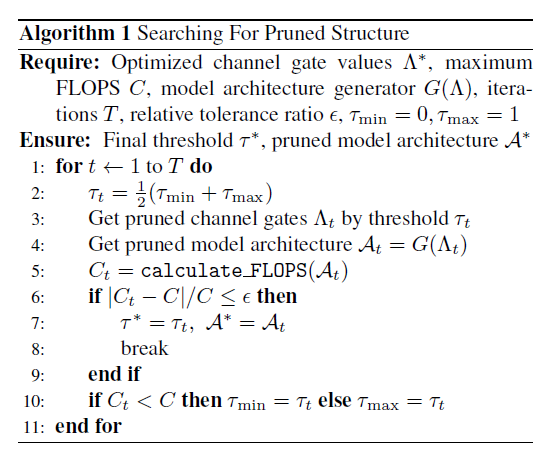
可以做channel expansion,增加channel数量,这样就可以增大搜索空间,没准就得到了更好的结果
训练的时候:
- adam
- 其他都比较常规
下表说明,还是挺有优势的。
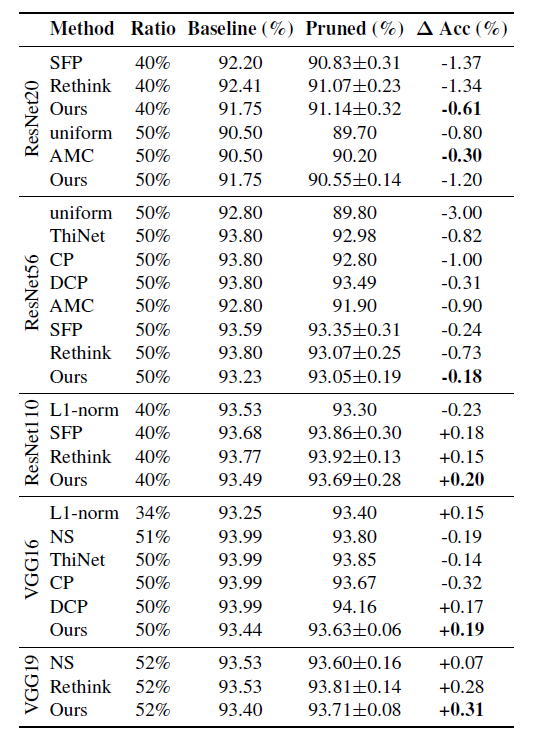
下表说明,比大乐透理论的结果要好。
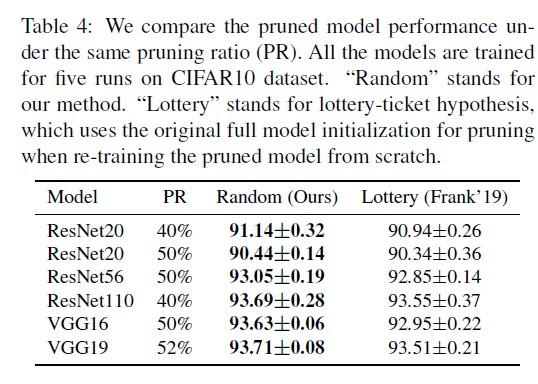
分解实验:
1、channel的扩增的影响
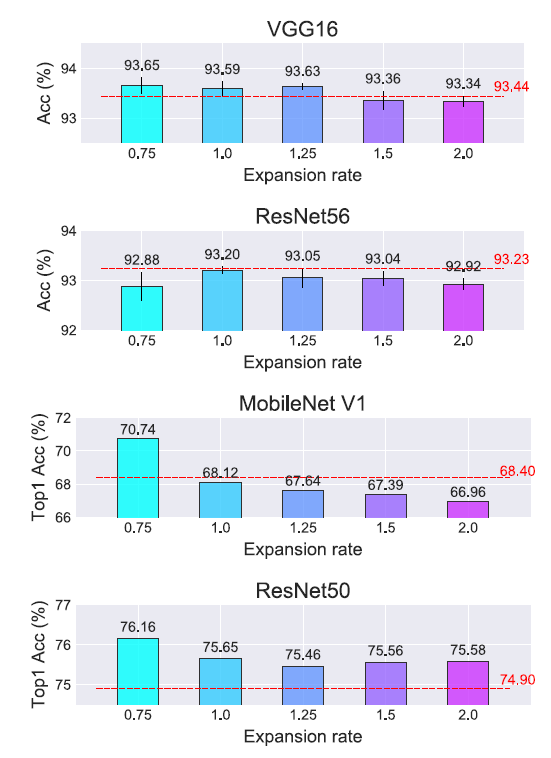
实验说明也不是扩张的越大越好,太大了反而效果变差了。但是缩小channel也不一定会得到不好的结果,可能也不错。
2、剪枝比例的影响:
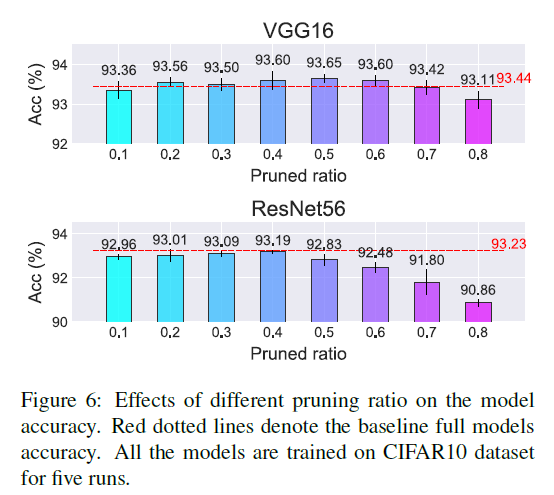
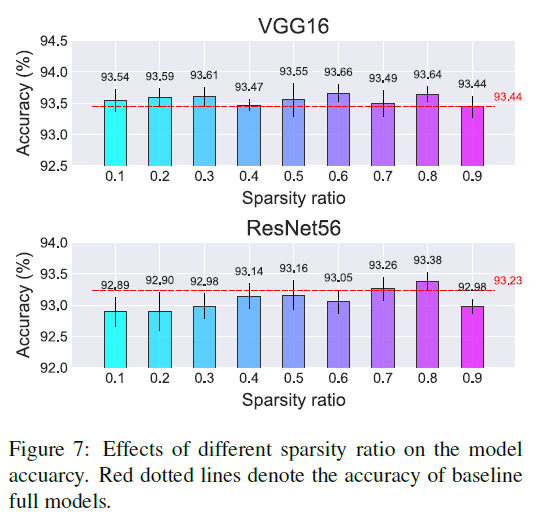
3、sparsity ratio的影响, 影响不大,不是特别的敏感。
关键代码
1 | def regularzation_update(model, args): |