本文是一篇实践为主的文章,做了很多的对比实验,读起来比较容易让人理解。作者的实验其实也比较简单,就是先在labeled 数据上训练一个teacher,然后引入大量的unlabeled data,然后使用labeled和unlabeled数据一起训练一个更大的student model,训练的时候加上一些augment和dropout等增加难度(这个很重要,是精髓),然后再用student当teacher进一步迭代,使得模型的效果越来越好。
论文名称:Self-Training With Noisy Student Improves ImageNet Classification.
作者:Xie, Qizhe
论文链接:https://arxiv.org/pdf/1911.04252v4.pdf
Github:https://github.com/google-research/noisystudent
Abstract
- 最好的模型使用了 3.5B weakly labeled Instagram images
- self-training and distillation
- 首先利用标注数据训练一个teacher,然后打伪标签,然后利用标注和未标注数据训练一个更大的student,然后student再作为teacher,反复这个过程。
- 在训练student的过程中,通过增加randaugment等,增加其泛化性,==这个很重要==。
Introduction
- noisy student 工作的两个主要因素: 1、student 更大; 2、student 更难。(加了很多noisy data, randaug, dropout, stochastic depth)
- teacher打标,可以是softlabel 也可以是hard label, ==softlabel 更好==
Noisy Student Training
- 算法流程如下:

主要点是使用 Data augmentation 以及 Dropout + Stochastic depth等
filtering and balancing, filtering就是将置信度低的图像去掉, balancing就是平衡不同类别的数据。作者在论文中举例,利用teacher打标后,每个类别挑选130k的图像,多的卡阈值,不够的使用复制粘贴的方法。
==resolution discrepancy==; 先在小分辨率图像上面训练350个epoch,然后使用大分辨率图像finetune 1.5epoch,不使用augment 同时 fix 浅层layer。
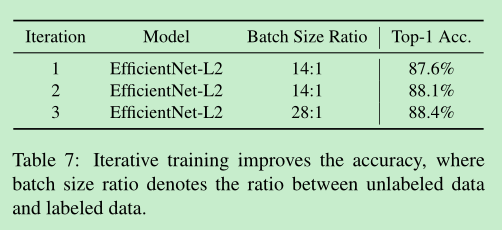
iterative training: 作者迭代了3次, efficientnet-b7 -> efficientnet-l2 -> efficientnet-l2
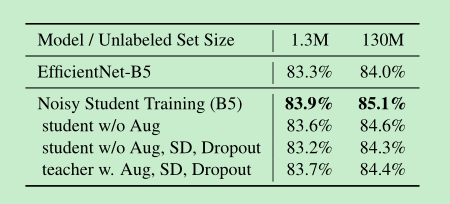
==实验证明,即使不使用iterative training;只是noisy train 也是会有效果的==
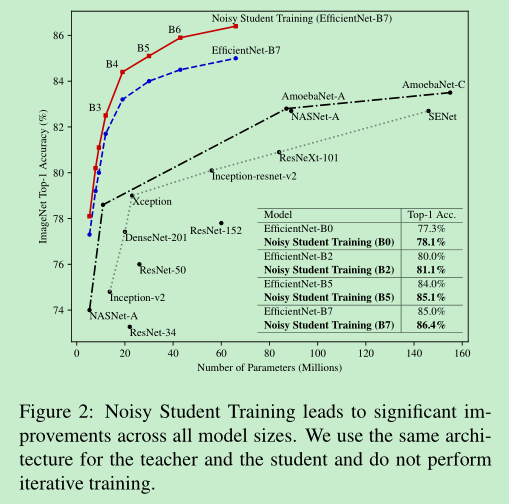
实验证明,==加了noisy training方法后,模型会更加的鲁棒。==
实验证明,即使使用了==FGSM==这样的攻击技术,依然具有较好的鲁棒性。
Ablation Study
- ==noisy的加入对于student效果的提升很重要==,作者把noisy全部去掉后,就没有啥提升了。
- 训练teacher的时候,加入noisy,并没有带来效果的提升。
- 多轮迭代的效果:其中3,把unlabeled batch 和labeled batch 的比例加大了。
==一些经验性实验结论==
- using a large teacher model with better performance leads to better results
- using a large amount of unlabeled data leads to better performance
- Hard Pseudo-Label vs. Soft Pseudo-Label on Out-of-domain Data.
- using a large student model is important to enable the student to learn a more powerful model.
- unlabeled data balanced
- joint training leads to a better solution that fits both types of data
- Using a larger ratio between unlabeled batch size and labeled batch size, leads to substantially better performance for a large model
- we train our model from scratch to ensure the best performance. 如果用teacher初始化student可以节省部分的训练时间,但是效果没有scratch那么好。
总结
- 本文是一篇实践为主的文章,做了很多的对比实验,读起来比较容易让人理解。作者的实验其实也比较简单,就是先在labeled 数据上训练一个teacher,然后引入大量的unlabeled data,然后使用labeled和unlabeled数据一起训练一个更大的student model,训练的时候加上一些augment和dropout等增加难度(这个很重要,是精髓),然后再用student当teacher进一步迭代,使得模型的效果越来越好。
反思
- 仔细想一下,使用labeled data直接训练一个更大的model已经可以取得更好的效果了,这里进而增加了unlabeled data, 如果unlabeled data的数据选择的是得分比较高的那部分,其实分类结果是可信的,然后使用了更为强大的augment,那么其实是在变相的增加训练数据,那结果变好貌似也是必然的。所以真正发挥作用的是什么?我觉得就是数据+augment吧。