Cait: Going deeper with Image Transformers
本文是对vision transformer的改进,主要贡献在于layerScale以及class-attention这两点,最近facebook研究transformer的那伙人发了好几篇针对transformer的修改篇,我觉的这篇有点不太实用,没有进行具体的尝试。
author: Facebook AI
Abstract
- 主要探讨模型结构和优化的关系
Introduction
- LayerScale : 有利于加速收敛以及改善精度,当transformer较深的时候。
- class-attention
- 迁移学习效果很不错
Deeper image transformers with LayerScale
- goal: 在将transformer迁移到视觉领域的时候,可以训练的更深,更稳定。
- DeiT训练了12层,但是事实证明不能训练的更深了。
- ==vit和Deit都是pre norm 模型包括swin transformer也是pre norm, 传统的transformer是post-norm 模型。==这倒是个以前没有注意到的点。 这个作者做了实验,在deit上,如果采用post-norm 会发现不收敛。
- Fixup, ReZero, skipInit,这几个方法都是在residual blocks的输出上,加上了一个==可学习的常数==,然后移除了pre-norm。
- 作者在实验中发现,移除norm采用fix那几个方法并不奏效,反而训练很不稳定,但是把norm加回来训练就稳定多了,所以作者就加回来了,还做了改进,由单个scalar变成了一个对角矩阵。
- layerscale的参数都设置的比较小,前18层是0.1 ,然后是10e-5,然后24层是10e-6
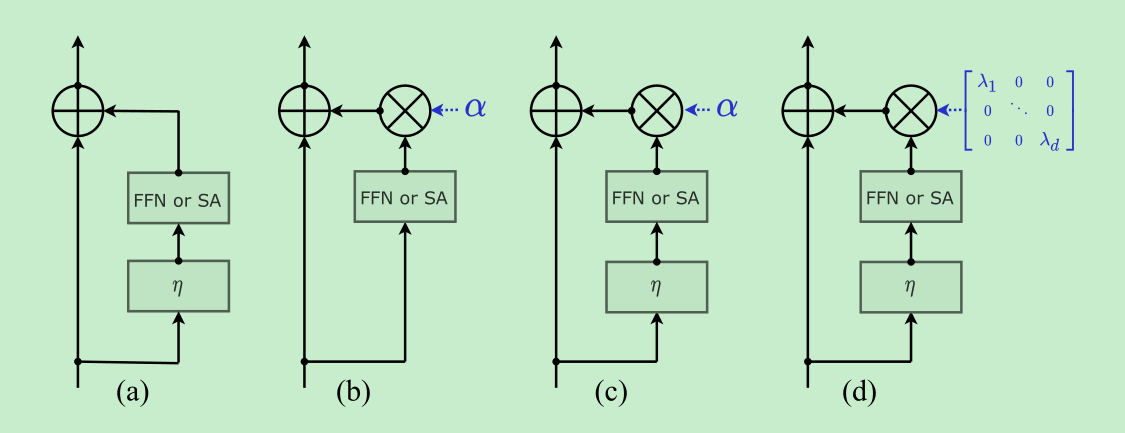
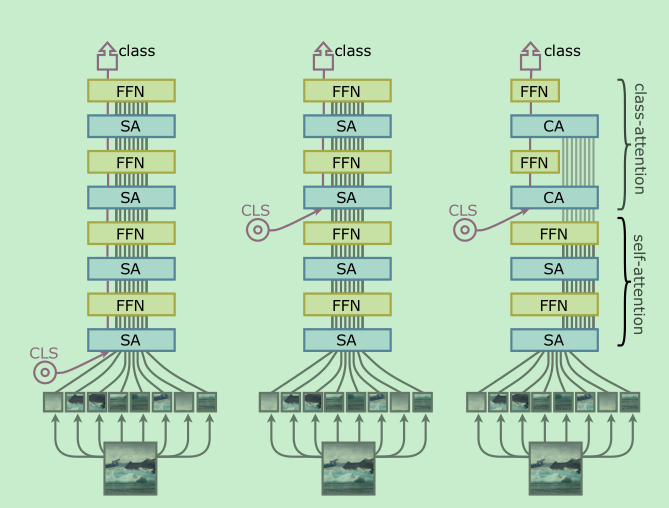
Specializing layers for class atention
- This design aims at circumventing one of the problems of the ViT architecture: the learned weights are asked to optimize two contradictory(矛盾) objectives:(1) guiding the self-attention between patches while (2) summarizing the information useful to the linear classifier.==很重要的一句话,说出来作者的idea来源==
- 改变了cls的位置,不是在一开始就插入,使得最开始的layer可完全在patch中计算self-attention。
- self-attention 跟vit差不多,不过没有了[cls]。
- class-attention 将patch embedding合成到cls中进行分类。
class-attention是怎么做的呢?主要就是下面这个公式,理解这个公式就可以里,其中 Q是只有xclass的,z是[xclass, xpatch]
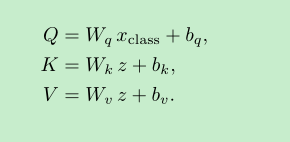
这里说一下计算$Q*K^T$本来是len_q * dim 和 len_k * dim ,这里的len_q 就变成了1, 最后得到的attention也变成了 1 x dim
Experiments
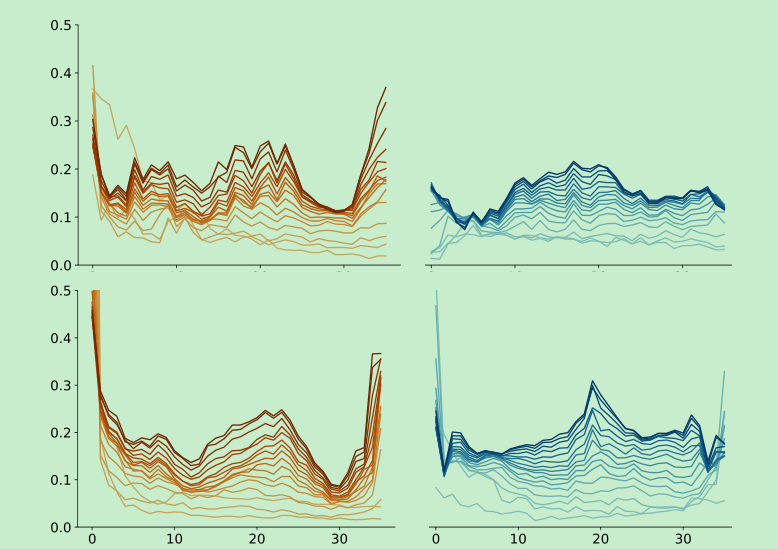
vit训到18层就训不下去了,24层反而效果变得比较差了,特别是只有imagenet数据的时候。
加了layerscale可以使得训练的更稳定,layer间的差别更小,下图 右边。
AdamW + cosine + 5 warmup + weight decay 0.05
引入了Deit的蒸馏策略,采用”hard distillation”
Deti -> Cait的优化进程:
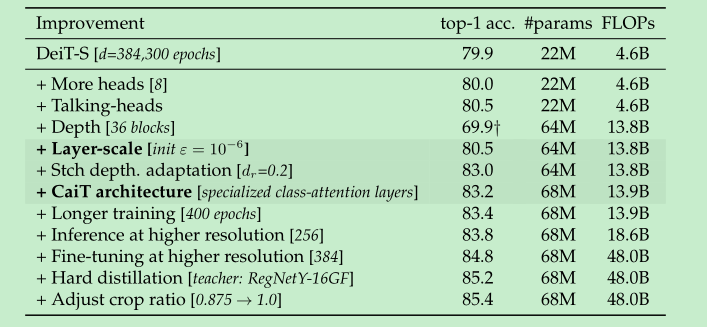
- conv时候采用center-crop(256x256中间抠出来224x224),但是wightman发现其实不crop对于transformer更加的友好,上面的表格中调整crop ratio的比例后,也涨了一点点。