这篇文章更偏向于网络设计,主要在于将conv与atten相结合,各取其有点,conv更擅长进行归纳总结,atten具有更大的容量,所以将二者进行结合,可以去得进一步提点的效果,然后为了减少计算量,采用了前面是conv,后面是atten的结构,同时,实验了结构里面每个stage有多少的block效果最好等等,代码没有开源,具体的实现细节还需要等开源再看。
https://arxiv.org/pdf/2106.04803v2.pdf
Google Brain
Zihang Dai
没开源
Abstract
- 虽然transformers倾向于更大的模型容量,但是由于其缺乏正确的归纳偏差(right inductive bias),可能会比conv弱一些。==这里后来我的理解就是泛化性比较弱,所以需要大量的图像嘛==。
- depthwise conv + self-attention
- vertical stacking conv and attention
- imagenet : 86%, if use jft-3b : 99.88%
Introduction
- vit的better performance 很大程度上是依赖于大量的数据的JFT-300,如果没有大量数据,vit效果不行的。
- 说缺乏certain desireable inductive biases, 需要大量的数据进行补偿,==归纳偏差是说对图像的特征进行归纳吗?没太理解?==, 后来在wikipedia找到了答案:https://en.wikipedia.org/wiki/Inductive_bias,简单说就是归纳能力,泛化能力。
- 卷积具有较强的归纳能力,可以快速收敛;atten具有较好的模型能力,适应较大的数据量,那将二者进行结合不就既有了generalization又有了model capacity.
Model
Merging Convolution and Self-Attention
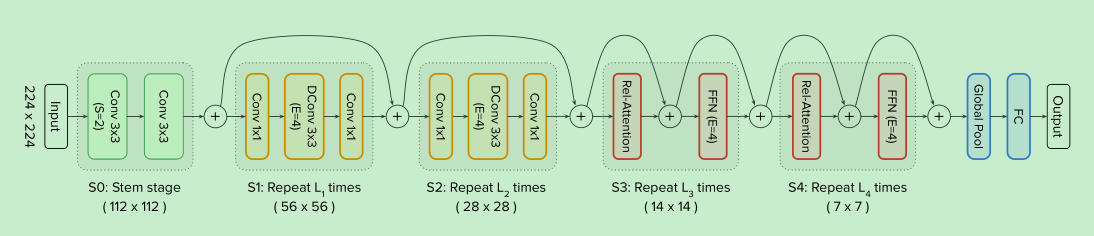
选择mobilnet里面的depth wise conv作为conv block; 因为mobilenet和transformer的ffn都是先提高4倍维度,然后又降回ori
conv和self attention,一样都是针对一块区域进行处理, conv是针对fix size进行处理比如3x3, self attention是针对全图进行处理。
对比分析:
conv的kernel是一个独立的超参数,而self attention是根据输入决定的,所以self attention更适合处理复杂的空间位置关系,这个属性比较适合处理high-level的信息,但是也比较容易过拟合。
==对于给定的position pair(i, j), conv weight 更关注与i 和 j 的偏移信息,而不是i和j的值。这个属性通常被称为等价翻译,更使用于提高泛化性。而由于vit使用了绝对的位置信息,破坏了这个属性,所以其效果变差。==这个可以好好分析分析,不是特别的理解。
感受野问题,self attention 具有大的感受野(但是大的感受野,往往带来的是较大的计算量。)
基于上面的分析,很自然的想法就是如下的结合:$w_{i-1}$是一个常数(==咋算的后面附录A.1详述==)
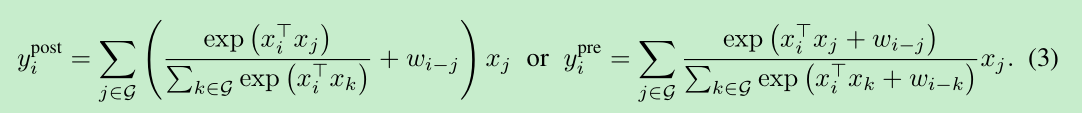
Vertical Layout Design
如果按照上面的结构进行设计,由于attention是对全图进行计算,那么计算量会比较大,有啥方法可以尝试减少计算量呢?
- 先降维,然后再使用attention操作。(==作者的主要尝试与探索==)
- 限制感受野,像卷积那样,使用小的感受野。(==发现其实没有用,增加了访存次数,反而更慢了==)
- softmax attention 替换成近似的linear attention, 减少计算量。(==试了,没有啥效果==)
那么具体应该怎么设计呢?作者进行了实验
- 作者进行了5个模式的设计,分别为:VIT,CCCC,CCCT,CCTT,CTTT, C代表conv, T代表transformer, C在T的前头。
- 结论: 泛化性: CCCC ~~ CCCT > CCTT > CTTT >> VIT
- 结论: 模型容量: CCTT~~ CTTT > VIT > CCCT > CCCC
- 实验结果说明,CCTT和CCCT表现差不多,最终作者进行了实验,根据迁移能力进行选择,最终CCTT胜出。
Experiments
- 作者在imagenet-1k, imagenet-21k, JFT上进行实验。 we first pre-train our models on each of the three datasets at resolution 224 for 300, 90 and 14 epochs respectively. Then, we finetune the pre-trained models on ImageNet-1K at the desired resolutions for 30 epochs and obtain the corresponding evaluation accuracy.
- RandAugment and MixUp + stochastic depth , label smoothing and weight decay,==又有了这个stochastic depth==
- Specifically, we have an interesting observation that if a certain type of augmentation is entirely disabled during pre-training, simply turning it on during fine-tuning would most likely harm the performance rather than improving==这个观察很神奇?why?==
- 实验效果,论文中表示,效果挺好的。
Ablation Studies
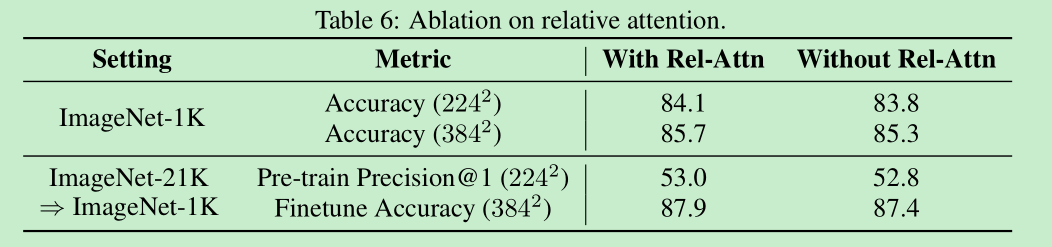
- 加入attention的作用
model Details
补充
A.1, 公式(3)的实现,那个w是如何实现的呢?我也是初略的看了,不知道对不对,作者设了一个(2H-1)x (2W-1)的参数,然后计算的时候直接进行索引。