Albert: A Lite BERT
Abstract
- use a self-supervise loss to focus on modeling inter-sentence coherence
- https://github.com/google-research/ALBERT.
Introduction
- It has become common practice to pre-train large models and distill them down to smaller ones
- ==Albert two parameter reduction techniques:== (1) factorized embedding parameterization, 通过将vocabularyembedding matrix进行分解,分解成2个小的matrix,这使得可以使用更大的hidden size (2) cross-layer parameter sharing,这使得模型不会随着网络的加深而参数量增加
- albert 可以减少bert 18倍的参数量,提升1.7倍的训练速度
- self-supervised loss for sentence-order perdiction: defined on textual segments rather than sentences
Albert
- 跟bert设置 一致: 使用gelu;feed-forward/filter: 4H; attention heads: H/64
- wordpiece: bert等都有用到,就是根据词根进行提取token,比如loved,loving等,lov + ed + ing
- embedding的映射,默认是到hidden size维度的,这样会存在一个较大的矩阵,albert采用的方法是,对齐进行分解,先映射到E维然后再映射到H维度,计算量从$V*`H -> VE+EH,H >> E$
- parameter sharing; 实验发现,这样使得不同层之间的参数更稳定
- NSP loss被发现并不是很可靠,猜测可能是这个任务太简单了,所以本文采用了行的SOP(sentence-order prediction) loss,简单来说就是将连续的句子前后顺序倒过来,作为负样本进行预测。
- tokenized using SentencePiece as in XLNet。
- n-gram mask; 不只是mask词,还mask短语。
Exp
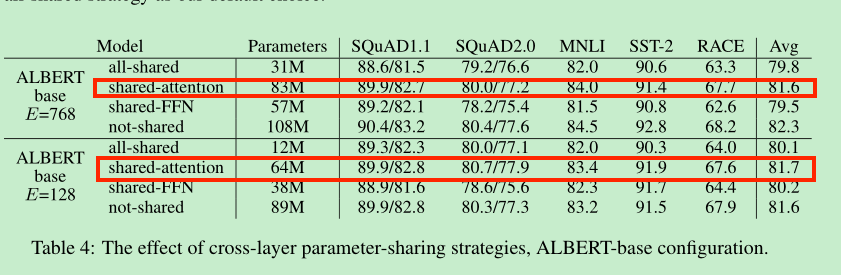
embedding size: E , 128效果较好。
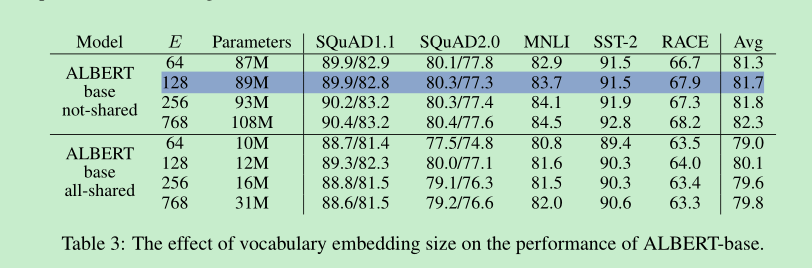
cross layer parameter sharing。
事实证明,share attention的效果是最好的,但是相差也没有很大,所以albert默认是参数全部共享的。