contrastive learning,简单来说就是通过unlabel data,构建相似图像与非相似图像集,然后判断模型的输出向量,相似图像比较接近,非相似图像比较远。本文的主要方法也比较简单,相比较于moco采用的query encoder 和key encoder的动量方法,本文采用相同的encoder,通过大的batch(8192)来构建相似与非相似样本集,通过不同的augment来产生positive pair以及negative pair, 通过positive pair和nagative pair 的相似度来计算contrastive loss,得到一个比较好的特征表达的模型。
论文名称:SimClr v1 v2
作者:Ting Chen, Hinton
论文链接:https://arxiv.org/pdf/2002.05709.pdf & https://arxiv.org/pdf/2006.10029.pdf
Github:https://github.com/google-research/simclr.
SimCLR
Abstract
- data augment 在定义高效的预测任务中扮演着重要的角色,并且这个角色比在监督训练中还要大。
- 在特征表达以及contrastive loss中,建立一个可学习的非线性转换,对于特征表达的学习具有重大意义。
- 对embedding进行normalize以及适当的调整温度系数,利用contrastive celoss 特征表达的学习。
- ==contrastive learning需要更大的batchsize以及更多的训练steps。==
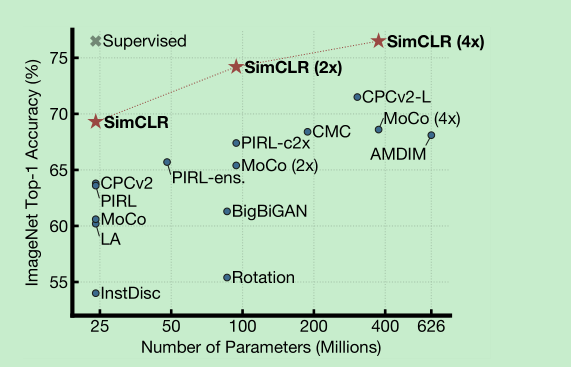
下图是linear classifiers 的效果
Introduction
- 学习高效的特征表达主要有两点,1个是generative(生成),另一个是discriminative(鉴别),生成的方法比如pixel的预测,会比较依赖计算资源。鉴别的方法比较依赖于pretext的设计。最近的 discriminative + contrastive learning的方法取得了不错的效果。
Relation
- handcrafted pretext tasks: 通过定义代理任务,来完成特征的学习,比如预测,相邻patch,拼图,旋转角度,color变换等,但这种方法太依赖与任务的设定。
- contrastive visual representation learning,这个是通过判断是否是positive pair 还是negative pair来进行特征的学习。
Method
contrastive learning framework
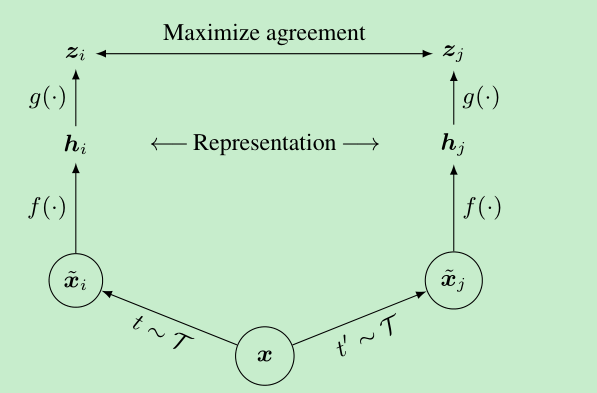
- 随机的augment来产生positive pairs
- 网络结构比较随意,这里采用的是resnet,average pooling layer的输出作为特征表达
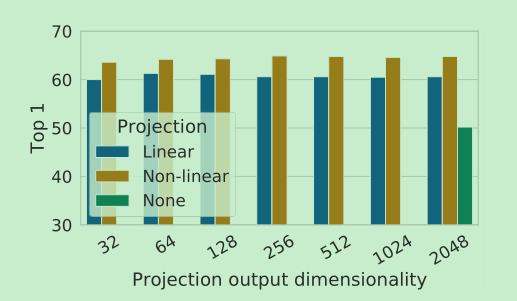
- 在上面的输出上,加上了一个projection head(2层MLP,中间ReLU),实验发现,这样做更有利于contrastive loss的计算
- 对于batch_size=N,经过aug,我们会得到2N的数据,其中正样本1对,其余的2(N-1)的数据,均作为负样本。
- $sim(u,v) = u^Tv/||u||*||v||$, 这不就是数学上向量的内积的夹角嘛,在代码中,相当于点积后做了归一化操作,==就是cosine similarity,余弦相似度==, ==这里跟moco也是一样的,只不过moco的归一化操作L2 norm在网络中完成了==
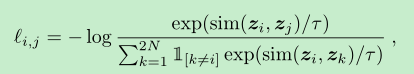
- 最终的loss是计算的所有的positive pairs,both (i,j) and (j, i)
- 伪代码如下:

Training with Large Batch Size
- simclr并没有使用memory bank,而是使用的大的batch size,将训练batch从256调整到8192,8192可以带来16382的负样本。
- 由于batch size 太大了,使用sgd训练可能会不稳定,所以本文使用的是==LARS optimizer==,==这个是什么优化器?没用过==
- 128个TPU cores
Global BN
- 意思就是如果采用分布式计算的情况下,各个卡分别计算自己的数据,这会导致局部信息优化预测的精度,但是并不会带来特征表达的提升。==啥意思没整明白,是不是说自己训自己的,对自己有益,但是对全局无益==
- 所以,simclr是对全局进行的bn,或者像moco那种采用shuffle计算bn也行,就是麻烦了一点。
Default settng
- resnet50
- 2-layer MLP projection head -> 128-dim
- optimize: LARS, lr:4.8,weight decay: 1e-6
Data Augmentation for Contrastive Repressentation Learning
- 实验发现,如果是两个组合的话,random crop + color distortion 效果比较好
- 并且实验发现,使用auto augment没有random crop + color distortion的效果好
- 并且对color distortion进行研究发现,随着强度的增强,模型效果会变好,但是supervise model,会变坏。
- ==总而言之,unserpervise learning 比 supervise learning 需要更强的augment==
Architectures
- Unsupervised contrastive learning benefits (more) from bigger models
- nonlinear的头还是比较有用的,提升比较大,==kaiming的moco就是没有采用nonlinear,而是采用的linear==。
- NT-Xent损失函数,下面的XT-Xent 的loss就是对上面的loss ,log提取后的结果。

作者对比了在loss中,L2 norm, 和温度的对比效果,实验发现,没有了norm之后 contrastive acc很高,但是特征表达不是特别好,比较低。同时合适的温度也有较为明显的影响。(这里就是dot product和cosine similarity的区别,说明进行归一化还是很有必要的)
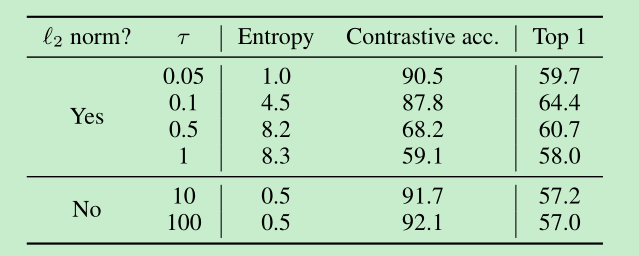
==larger batch is better==, longer training is better,(作者的部分对比实验是训练了1000epoch)
Comparison with Sota
- Linear evaluation:
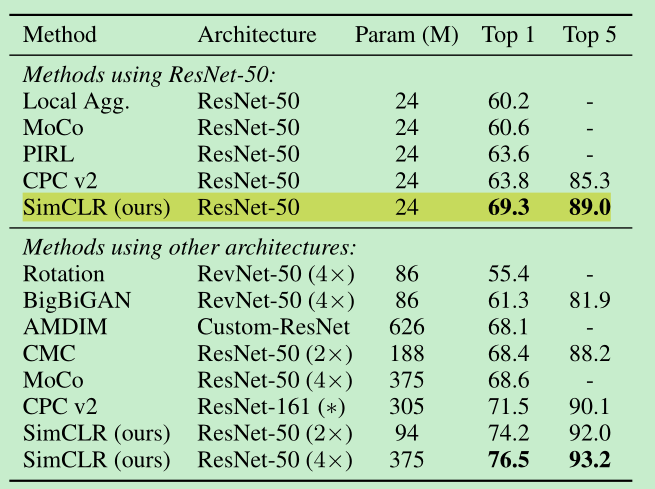
- transfer learning:(可见基本上是有点效果的,相比supervised)
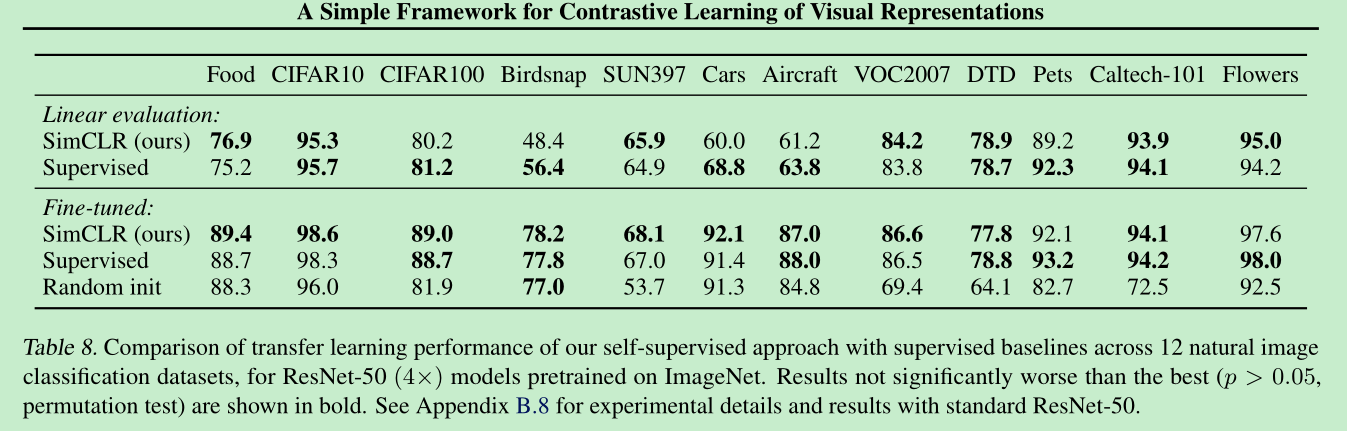
附录
randomresizecrop() 通用设置,crop size 0.08-1, aspect 3/4 - 4/3, horizontal flip
color_distortion代码如下,

发现针对LARS optimizer , square root learning rate scaling 效果比单纯的scaling效果要好。
实验显示,bs=8192的时候 , 似乎 饱和了,继续增大到32k,并没有显著改善效果了
finetune 参数
bs:4096, lr:0.8, momentum:0.9,
1%数据 finetune 60 epochs, 10%数据再finetune 30 epoch
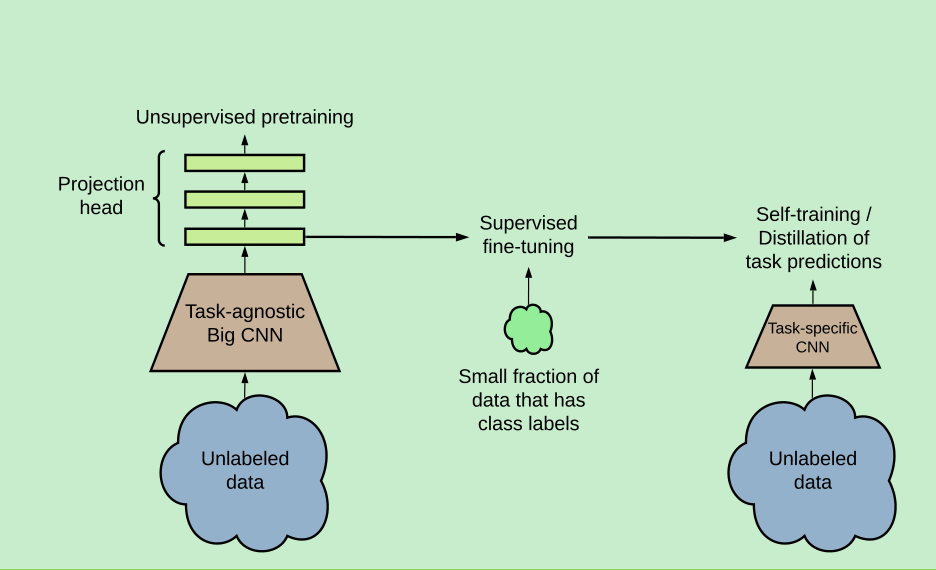
simclr - V2
V2主要想表达的不只是提出了一个对比学习的self-supervised learning的算法,更重要的是想表达一个pretraining + finetune的范式,只不过当只有少量数据的时候,小模型的表现也不是特别好,虽然已经有了提升,但是跟全量finetune有个比较大的gap,但是大模型表现很好(这里大模型也可以再来一轮的自监督),所以这里作者又引入了蒸馏的思想,来实现这个范式,我猜这就是作者的实验过程。
跟有监督相比,如果只是替换了预训练模型为自监督的预训练模型,那么finetune后的效果的提升可能是模型越大越明显一些,相对于resnet50提升特别的大,resnet152x2+sk提升的很明显,但是预训练模型的优势在于,如果只使用10%的数据进行finetune,在大模型上可以达到跟有监督相同的精度效果,resnet50还是要差点,这个时候,如果加上蒸馏,teacher可以选择个大模型(也是finetune+semi得到的),这样resnet50的精度也能上来了,成功的实现了少量数据,小模型,达到大数据finetune的近乎相同效果,如果是大模型甚至可能会超过finetune的效果。
大量无标签自监督加上finetune,虽然这个预训练是任务无关的,但是对于半监督有很好的效果。==关键在于需要使用大的宽的网络来进行预训练和finetune==
并且标签的数据越少,这个大模型的自监督的收益越大
fine-tuning后,可以使用unlabel data + 蒸馏等进一步缩小模型
总结起来就是三步:
- 自监督预训练一个大的resnet模型
- 在小规模数据集进行finetune
- unlabeled data上进行蒸馏
1% label data在imagenet上,resnet50 可以达到73.9%的效果。
10% label data 在imagenet上,resnet50可以达到77.5%的效果。
根据作者的经验,越少的数据,越需要大模型,大的自监督模型更加的数据高效,在小数据上finetune的时候明显会更好,即使他们更容易过拟合
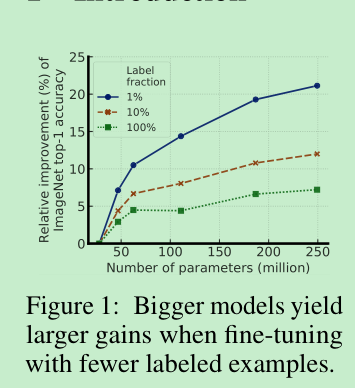
进一步说明了非线性投影头(projection head)的重要性,不仅对改善特征表示有帮助,对半监督也很有效果
simclr v2的变化:
- 训练更大的模型,resnet-152, 3x channel, + SK
- deeper projection head(3-layer) , 并且在finetune的时候 不全丢了,留1个layer。这个操作在linear evaluation和finetune都涨点了。
- 采用moco的memory bank方式,得到更多的负样本,带来了大约1%的linear提升。
蒸馏loss: , P代表softmax
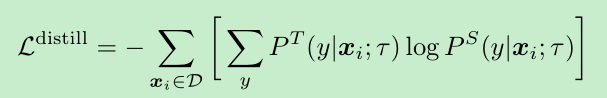
如果label的数据比较多 也可以把label的loss加上
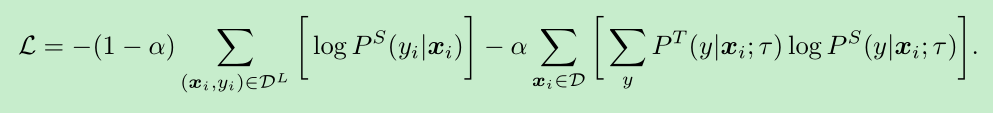
参数细节可以看论文 Settings and Implementation Details,设置还是比较常规的。值得一提的是,在finetune和distilation的时候,并没有采用过多的augment,只是采用了random crop 和 horizontal flips,==这个感觉有点少,不知作者是何意?是这样效果比较好?论文中貌似没提==
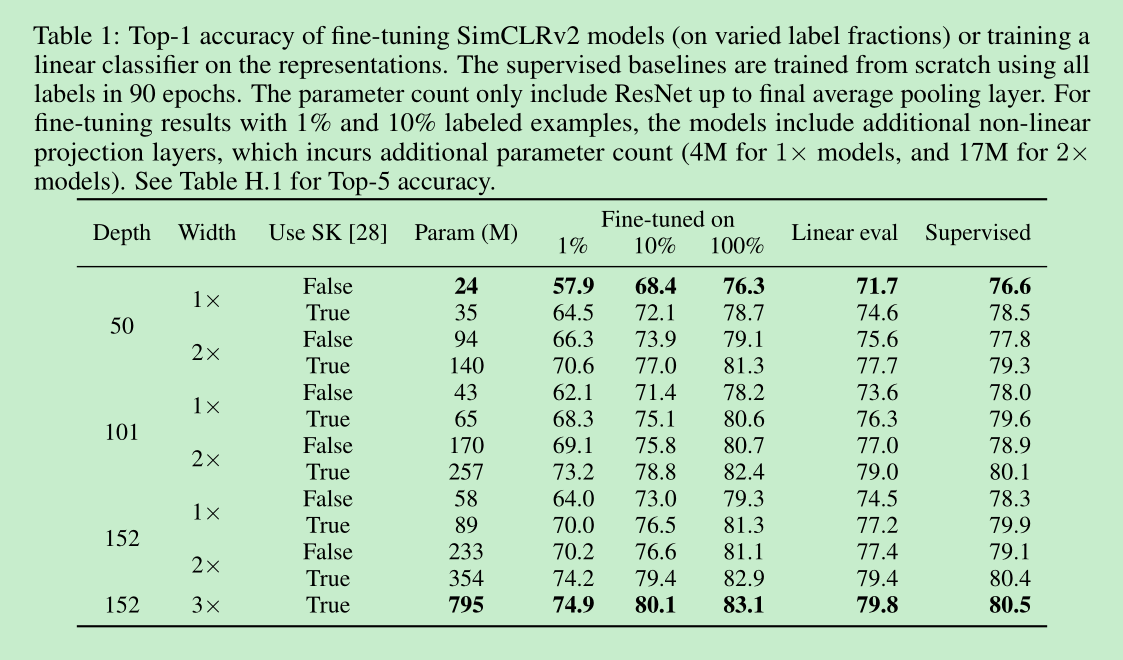
从下面这个表可以看出,自监督后,使用100%数据finetune是要比supervised直接训练的效果要好的。并且随着网络结构变得复杂,finetune后的表现是会变好的,虽然可能从resnet50->resnet101->resnet152 的变化可能并不是特别大,57%->62%->64%,但是当进一步加大152的时候,就飙到了75%,相比57%就比较明显了。并且可以看出,在监督学习领域,这个方法的提升可能不大(4%),但是对自监督明显就大了(9%),并且这个模型增大也不是一直涨,可以看到resnet152 sk x2 和 x3,相差就不是特别大了。这里的supervise应用了很多的augment
值得一提的是,当使用更大的resnet的时候,更深的projection head的作用就相对小一些了
大的teacher还可以采用自蒸馏的方式,提升自己的效果
linear evaluation 和finetune是正相关的,即会同时升高
==目前来看,自监督训练的模型更不容易过拟合呀, 换大模型之后提升更为平稳==