又是一篇自监督领域的作品,这篇论文采用了mask的方式,跟bert很类似,设计了encoder,decoder,decoder的作用是重建mask的图像,本文mask的比例很高,在75%,最后重建的效果竟然还可以,很是厉害。这篇文章的模型采用的是vit,finetune后的模型精度非常高,另外作者设计了将mask的patches放到decoder(轻量)中,这样可以有效的减少计算量,提升训练速度。
论文名称:Masked Autoencoders Are Scalable Vision Learners
作者:Kaiming He
论文链接:https://arxiv.org/abs/2111.06377
Github:https://github.com/facebookresearch/mae
Abstract
- autoencoder的模型结构,随机mask掉一部分的patches,然后通过decoder来重建缺失的pixels
- encoder只见没有被mask的patches, 然后输出特征跟mask的patches一起送入decoder进行重建。
- 采用这种方式使得训练更快(3x or more),并且取得了更好的精度
- vit-huge 取得了 87.8%的精度在imagenet-1k
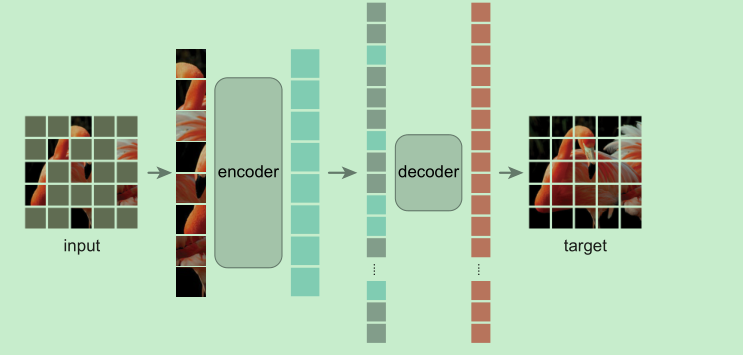
Introduction
将mask方式引入cv,那么cv和nlp最大的不同点是什么呢?
- cv中conv为主,相比nlp中的transformer不善于整合位置信息等,但是现在已经有了cv transformer, 这个问题得以解决.
- 信息密度不同,图像的冗余信息太多了,为了克服这个不同,本文采用的方法是,mask掉大部分的patches,极大的降低信息冗余,让图像自己去理解全局信息。
- decoder的不同,在cv中,decoder需要预测的是像素级别的语义信息,在NLP中,预测的是word级别的语义信息,显然word含有更为丰富的语义信息。
将mask token转移到decoder(本文用了一个轻量的decoder)中进行计算,可以减少大量的计算量。
并且,一个大的mask比例可以取得双赢的效果。比如75%的patches被mask掉
因为减少了计算量,我们就可以训练大容量的模型了,比如vit-huge
Related Work
Approach
- Masking: 随机去mask掉一部分的patches, 并且是mask的大部分,使得通过相邻的patch不是很容易推断出中间内容
- MAE encoder就是vit huge, add position embedding
- MAE decoder: mask token is shared , learned vector, add position embedding, 只在pre-training使用
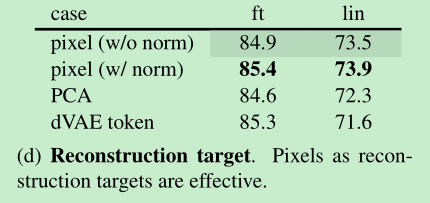
- Reconstruction target: 最后一层输出的channel数就是每个patch的像素的数量,采用的是MSE loss,只在mask的patch上计算loss , 另外作者做实验,如果对patch先进行归一化(减均值除方差),预测归一化的mask,效果会更好。
- Simple implementation : shuffle,然后尾部的x%去掉即可。
ImageNet Exp
- 使用MAE, finetune效果还是不错的:only finetune 50 epoch 就超过了原版
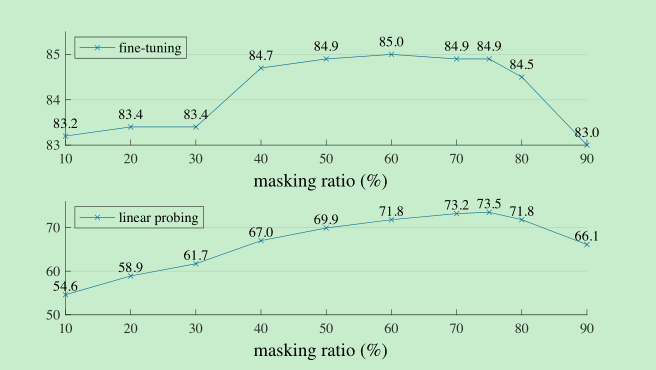
Masking ratio,发现我们最好的是mask 75%, 而bert是15%,如下图是不同mask ratio的效果,可以发现finetune无论多大的ratio,都是比scratch要好的,并且两个不同的ratio的结果波动还是比较大的。
decoder design:观察下表a可以看到,不同的block深度,对ft影响不大,但是lin影响比较大,为啥呢?主要原因在于重建时候的像素预测与分类任务之间存在的gap,最后的几层更重在重建,而不是识别。

Mask token: 如果在encoder中也加入mask token,模型的表现反而会变差,linear probing掉了14%,这其中主要有一个训练和部署的gap,预训练时候有很多的mask但是在inference的时候却没有了,所以对encoder去掉所有的mask,只看到真实的patch是有效的,也是因为此,导致的模型训练速度很快,因为75的patches的计算量没有了。
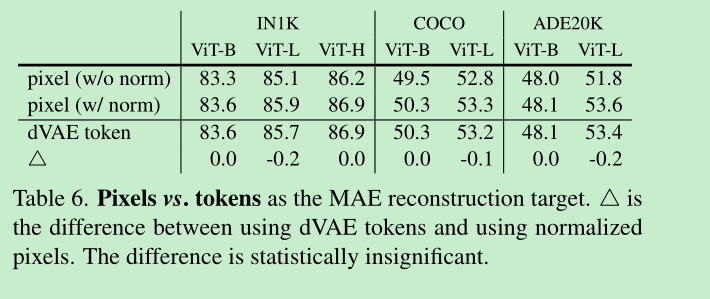
Reconstruction target: 基于像素的图像重建效果就比较好了(带normalize的效果会更好), PCA的方法和dVAE的方法没干过pixel norm,dVAE是怎么做的呢?我理解应该是先通过encoder提取token, 然后利用本文的encoder,decoder来重建这个token,不知道对不对, ==这里留下个问题,这个PCA是怎么做的?先对patch提取PCA, 然后decoder重建的向量跟PCA算loss?==
Data augmentation: 仅仅使用rand crop效果是比较好的,加了color jitter反而效果变差了,这跟contastive方法还是有比较大的差别的
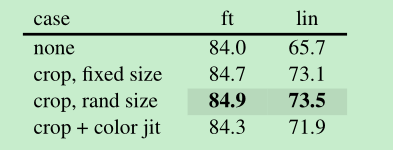
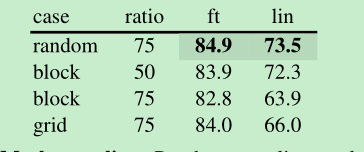
mask sampling stategy: 随机的比较好
Training schedule:
800 epoch pre-training
acc增长相对平稳
linear probing acc 即使到了1600epoch也还没有饱和,这跟moco v3不同,v3在300就饱和了
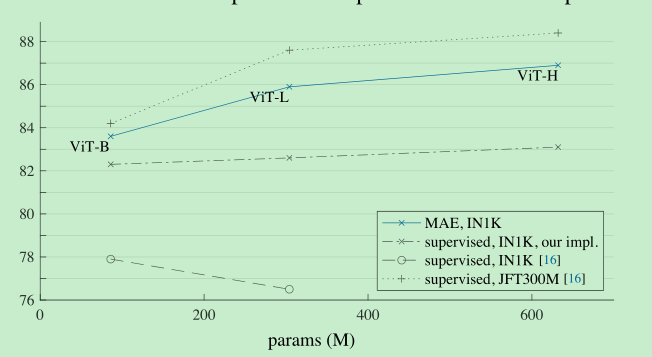
Comparisons with Previous Result
- 优势明显,而且我们训的快,即使是1600epoch 也比别人训的快
- 并且,增大模型,我们得到了稳定的精度提升
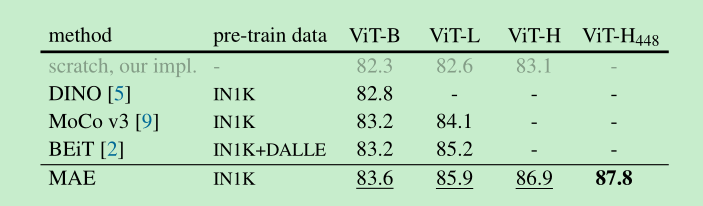
- 与有监督方法相比,如下,模型越大,提升的点越多。
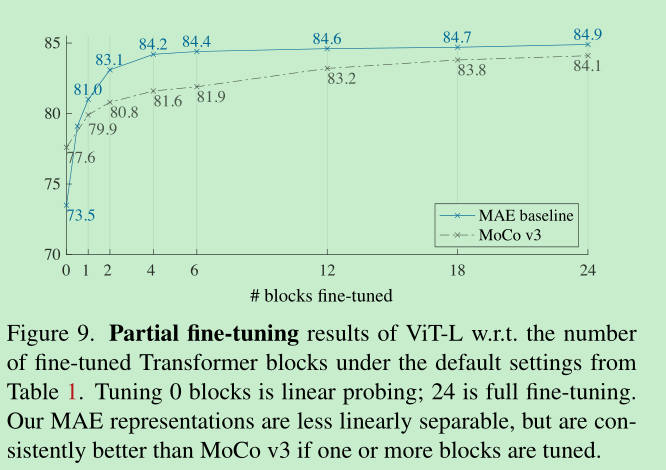
Partial Finetuning
- linear probing, 缺少了追求强大但是非线性的特征,这在深度学习是很重要的。
- 作为权衡,提出了partial fine-tuning策略, 只finetune最后一些层的参数。
- 下表是patital finetuning的结果对比,可以发现稍微增加一些finetune的层,效果就很显著。这说明了MAE提取的特征表示是线性不可分离的,是比较强的非线性特征。
Transfer Learning
- 这里发现 使用dvae的效果跟pixel差不多,增加了dvae反而增加了复杂度,所以还是不用的好。
附录

- MAE也加入了一个冗余的cls token,但是有没有这个cls token,都是可以正常工作的。
- 在训练linear classifier的时候,加上normalize一般是有用的
- vit的代码直接训练是没有训出来的,后来这里做了一些修改训出来了精度更高了。