在进行对比学习的时候,查询字典可以越大越好,可是在增大查询字典的同时,如何保证字典内的key的连续性就比较关键,如果不连续的话,很可能会偏向于相对连续的向量,这对对比学习是不利的,比如query encoder,key encoder 同时反向传播,由于key encoder更新较快,就只能利用mini-batch的字典,而另一种方法将key全部存起来,每次sample一定的量进行学习,虽然字典的量上来了,但是由于每次只能更新sample出来的key,明显不具备连续性,基于此,本文提出的momentum更新方式,由于momentum很大基本上是0.999,这就导致key encoder其实更新的很慢,这个时候维护一个队列比如65536,bs=128的时候,512个batch就完成了一次队列的更新,这就保证了队列里面的数据不会太older,具备一定的连续性。还有一个小点是,contrastive loss的时候,其实是点积计算相似性,然后算cross_entropy(),做了一个k+1维的softmax
论文名称:MoCo v1: Momentum Contrast for Unsupervised Visual Representation Learning
论文名称:MoCo v2:Improved Baselines with Momentum Contrastive Learning
作者:Kaiming He 团队
论文链接:https://arxiv.org/abs/2111.06377 && https://arxiv.org/abs/2003.04297
Github:https://github.com/facebookresearch/moco
Moco V1
Abstract
- 对比学习,可以看做是字典查找,本文通过队列建立了一个动态的字典
Introduction
- 相比较语言任务,视觉任务的更关注于字典的建立,因为原始信号是连续的高维空间,是没有结构的。
- contrastive loss
- 以前的方法,总结来看,就是是建立动态的字典,字典中的key是从数据(image or patch)中采样的,然后用一个encoder来表示。 encoder用来完成字典查找的过程,query encoder应该匹配相同的key,不匹配其他,学习的过程就是最小化contrastive loss的过程。
- 所以,这个字典得大,并且字典在训练过程中要具有连续性的。
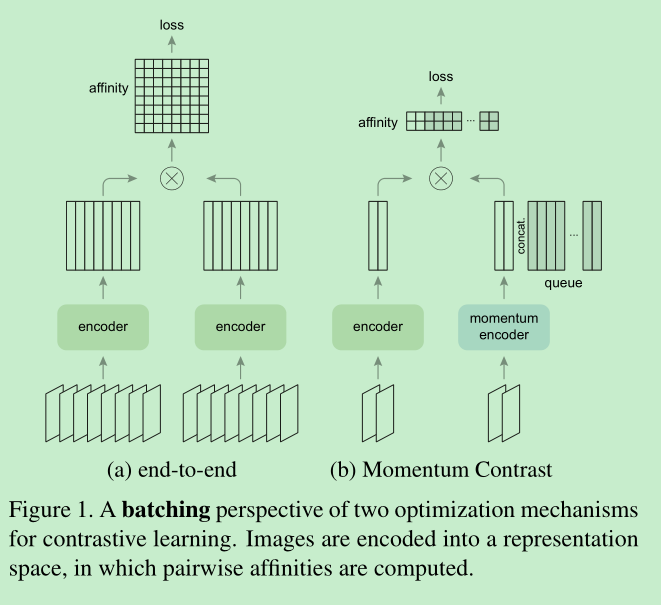
- 本文提出方法如下图
- encoder,默认就是resnet50结构,将最后的fc的num_classes 设置为特征维度(128)即可。
Related Work
- unsupervised self-supervised learning,主要有两个方面,一个是pretext tasks (代理任务),另一个是 loss function
- contrastive loss 计算的是样本间表示的相似性,就是当样本相似的时候,就会比较小,样本对不相似的时候会比较大。adversarial losses 计算的是数据的分布概率,适用于数据的生成。adversarial network 和 nce loss会有一定的联系的。
Method
contrastive learning as dictionary look-up
相似度的度量用点积,所以本文的对正负样本相似度的度量的loss函数如下:t是温度系数。简单点看,就是在k+1维的softmax-based classifier中,把q预测成k+的概率,infoNCE loss :
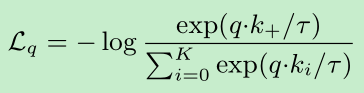
query representation 可以是$q=f_q(x^q)$ 输入的可以是image 也可以是patch 也可以是 patches, 两个encoder可以是相同的,可以是共享的,也可以是不同的。
Momentum contrast
- 我们的假设是,好的表达可以从大的字典中学到,因为其有足够的负样本,同时字典要具备一定的连续性。
- 弄了个队列,来扩大字典的容量,新数据进队列,outdate数据出队列。
- 用队列可以扩大字典量,但是却限制了key encoder的更新,那怎么办?一个简单的解决方式是,直接copy query encoder to key encoder,但实验显示效果不好,可能是key encoder更新太快了,破坏了连续性。
- 本文是怎么干的呢?主要问题还是让key encoder更新的慢一点,所以就采用了动量的方式,每次梯度只更新query encoder,key encoder通过query的更新进行计算,公式如下,并且实验证明,动量越大,效果越好,e.g. m=0.999比m=0.9要好,说明更新的越慢越好。
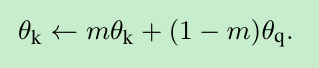
- 该方法的好处,1.可以使用大量的数据,亿级别也不在话下,2.保证了更新的连续性。
Pretext Task
- 实例辨别任务,a query and a key, 如果来自同一张图像,就是一个正例,如果是不同的就是一个反例。
Technical details
- resnet as encoder
- last fc层的输出(128维),经过L2-norm 作为key 和query的特征表示, t=0.07,这里提一下,为啥做L2-norm,我想主要是为了计算后面的相似性,需要做归一化
shuffling BN(小trick)
- 传统的BN效果不是很好。因为模型会欺骗代理任务,找到一个简单的解决方式,而没有去学习更好的相似性
- 因为是采用分布式进行的训练,所以数据会被分配到多块卡上,shuffling bn计算bn只在每块卡上单独计算。同时对于一批数据,对于key encoder,moco先把数据shuffle掉,然后在放到gpu过key encoder,但是query encoder并没有shuffle,这就导致key和query是跟不同的数据做的bn,解决了bn导致的数据内部通信减少了数据分辨信息的问题。
伪代码

Exp
- bs:256, 8 gpus
- init lr 0.03, 200 epochs
- linear classification protocol, 先unsepervise训练,然后固定参数,训练分类head, ==initial learning rate:30 , weight decay is 0==这个设置有点猛啊。
- 跟以前的方法的对比:可以看到 bank的方法,在效果上不如moco,作者猜想,主要原因在于moco对于连续性的优化
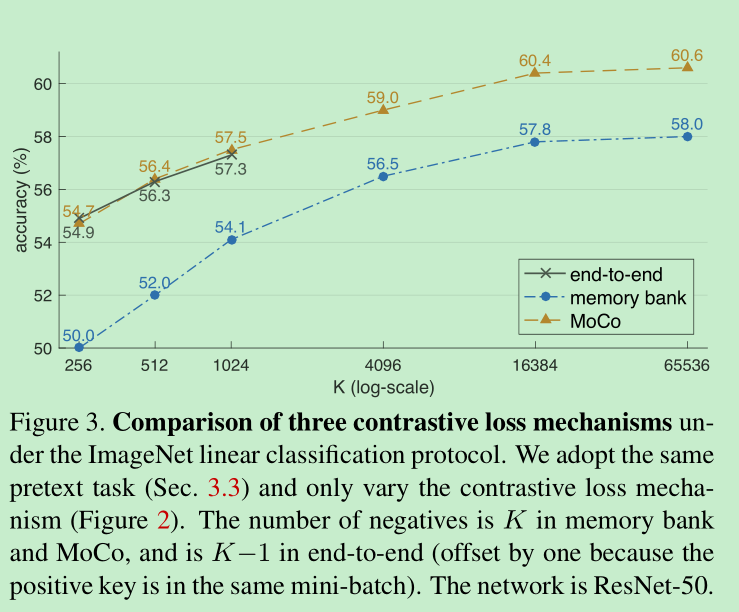
还有一个点是,momentum取多少合适呢?结果如下,可以看到,如果momentum=0,就代表完全更新,结果就是训不起来了震荡的比较厉害,但等于0不就约等于是memory bank了吗?为什么训不起来了呢,是不是参数没调好。。。

在finetune的时候,bn是全同步的,而不是冻住的,并且在新加的层中也加入了BN
moco的迁移性比较好,在多个下游的检测或者分割任务上超过了有监督学习。
MoCo V2
moco v2 主要是借鉴里simclr的augment以及加了非线性头的思想,在moco v1的基础上进行了进一步的优化,在无监督上提了大约7个点,增加训练epochs之后,提高了10个点。
其中调整的augment如下:对colorjitter做了调整,对hue的强度做了调整,同时比例做了调整,增加了高斯blur
1 | if args.aug_plus: |
调整的mlp如下:
1 | if mlp: # hack: brute-force replacement |
moco的优势:相比simclr,不需要大的batch size 也能得到大量的负样本,使得即使没有大量gpu,也能训练。
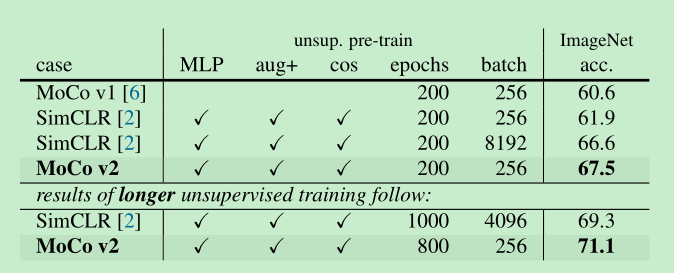
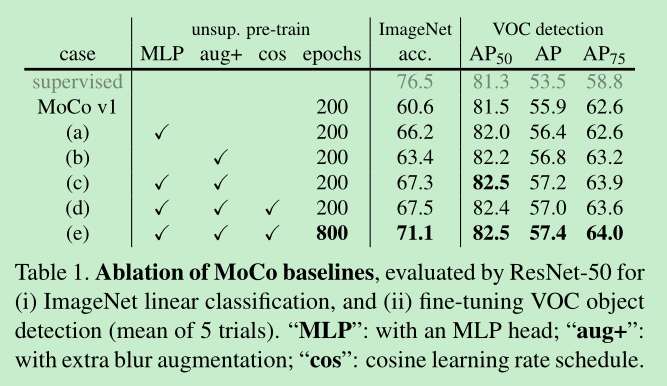
simclr这些设置到底起了多大作用呢?实验看一下
MLP head, 可见,有了mlp的效果提升还是比较大的,当$\tau=0.2$时,提升了大约7%。

augment的效果
- 新的augment 带来了大于2.8%的提升
- detection上看,貌似aug比mlp带来了更大的提升82.2% -> 82%,这说明,这种linear classification的方法得到的精度,对于检测的迁移性,并不一定正相关。
- 跟simclr做对比:可以看出moco v2 在更小的batch上面,取得了更好的效果,acc为linear classifier accuracy