swin transformer是对vision transformer的改进版,主要思想在于在vision transformer的基础上,引入了卷积的归纳偏置,设计了分层的结构,针对特征图,只在windows窗口内进行self-attention的计算,取得了速度与效果的平衡,vision transformer需要比较大的数据来进行模型的训练才能取得比较好的效果,swin transformer在imagenet-1k上面,也能取得很好的效果。
Title: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Author : Liu Ze, Hu Han
微软亚洲研究院
Abstract
- 视觉相比NLP的不同点: 图像中的实例变化尺度比较大,并且图像的分辨率很高。==这也是本文主要解决的两个创新点,问题一解决方式是分层操作, 问题二解决的方式是window内进行self-attention计算。==
- shifted window scheme,通过限制了不重叠的窗口+跨窗口的交互, 极大的提高了效率。
- 对图像的不同大小的尺寸适应性比较好,(不像vit,尺寸固定),可以适应不同的视觉任务。
- image classification : 86.4%
Introduction
不同点总结:
文字具有固定的尺度的,但是图像中的对象的尺度变换很大。
图像的分辨率很高,比如图像分割,需要在像素级别进行密集预测,这会带来self-attetion计算复杂度的平方增长。
swin transformer 分层就是最开始是小尺寸的patch,然后合并相邻的patch使得patch的尺寸变大。
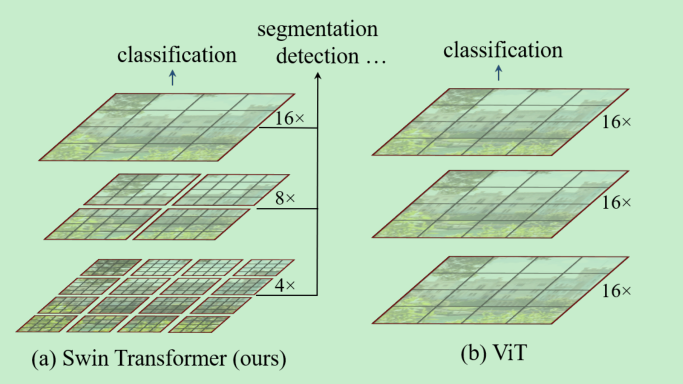
self-attention是在windows中计算的,一个window中包含的patch的数量是固定的。
swin transformer的一个最大的创新点是 shift window,
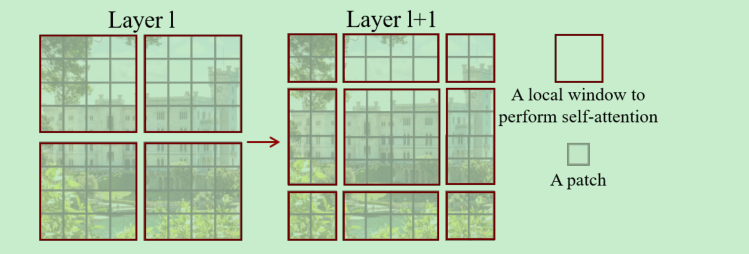
Relation
- 近期的工作中,有一些是将self-attention应用到局部窗口(slide window)中,对每个像素进行计算attention==[32,49,77]这个是怎么做的可以了解一下==;虽然他们取得了加好的acc/flops 的trade off, 但是由于其频繁的内存访问,导致其延时还是比较高的。==本文使用shift windows,取得更高的效率==
- vit不错,但是vit不适用于密集视觉任务,以及对尺寸不友好。
- ==The number of patches in each window is fixed==, and thus the complexity becomes linearto image size.
Method
- all arch:
- 提取每个patch的大小为4x4,这样,每个patch的dim就是4x4x3=48, 然后通过一个linear映射到embedding dim
- 以224为例子,每张图像提取56x56个patch
- hierarchical representation: 通过patch merging layer, 将2x2的相邻patch进行concat合并,然后通过linear 映射将4C的维度降到2C
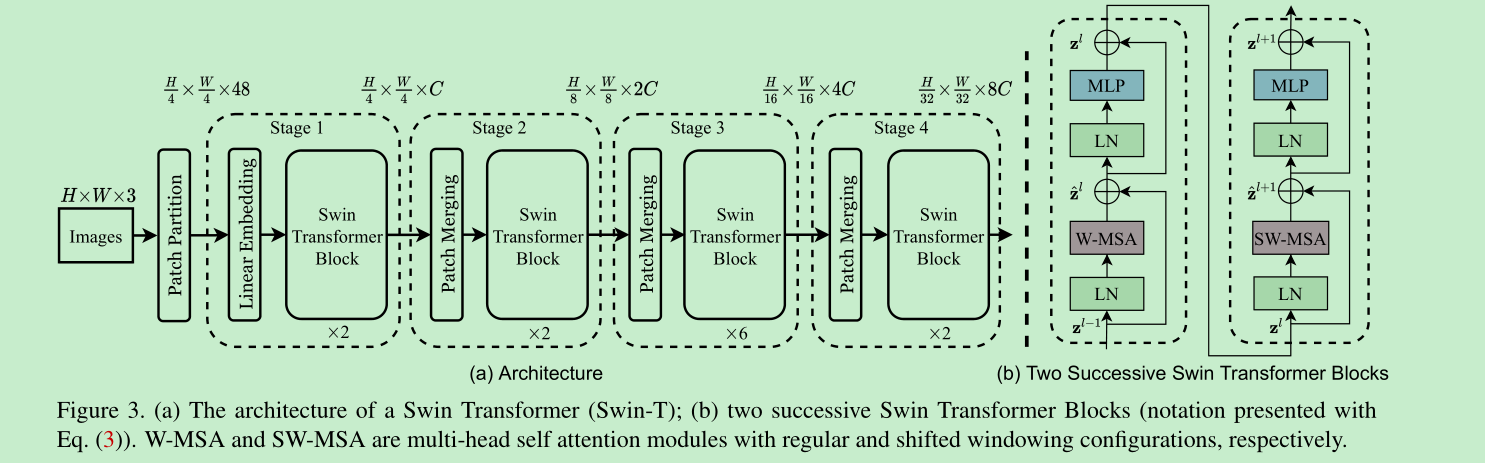
- multi-head-att的不同,主要是swin引入了shift window的思想,其他基本都是相同的。
shifted window based self-attention
- 如果不使用窗口,使用全局的attention,对于密集型的预测,计算量会比较大。如下公式是使用window后的计算结果对比,不使用window,跟hw是平方关系,使用window后跟hw是线性关系。
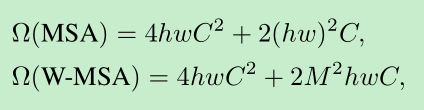
- swin选择在windows中计算self-attention 每个windows包含多个patches.
- 但是在window中计算attention也存在一个问题,就是缺乏window间的交互,所以作者提出了如下的shift window方法。
- 但是上面的方法依然存在问题,在window shift之后,window的数量会增加,因为出现了不满足窗口大小的的windows. 这里作者提出了cyclic-shifting 方法。如下图,函数就是==torch.roll实现==,这样在计算atten的时候,将移动的地方mask掉就可以了,不影响计算量。 ==shift是交替进行的,这里如果我没有理解错,就是shift windows内patch数量的一半,win内patch的数量默认为7,这样随着层数加深的merge操作,shift的越来越多,可以理解为感受野越来越大==
- 在代码中,这种交互在不同的block中是交替进行的。
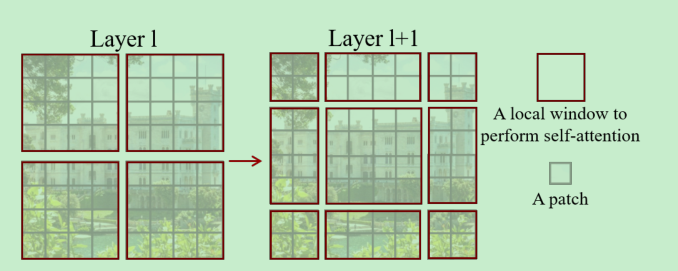
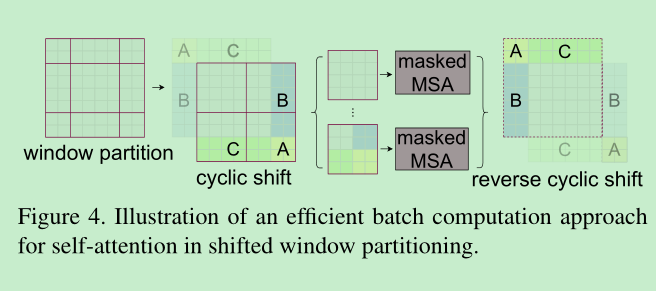
- 本文也是因为使用了分层操作,使得一些密集操作可以实现,为啥可以实现呢?因为通过分层合并,patch的数量有效的减少了,计算量也就有效的减少了。
exp
- train 参数: lr 0.001, adamw, cosine decay, 300 epoch, bs 1024, weight decay 0.05
- finetune 参数: 10e-5, 30 epoch, weight decay 10e-8
- 大量的augment的应用
附录:
swin-transformer, 维度运算总结
输入图像: (1,3,224,224)
merge维度,4x4大小的patch:(1,56,56,96),先不考虑batch 就是 (56,56,96)
提取窗口,7x7个patch组成一个窗口, (64,7,7,96),合并窗口维度后 =》 (64,49,96) ### 如果输入的batchsize不是1,改为2,这里就变成了 (128,49,96)
计算QKV就是一个linear, self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
Q, K, V : (64,3,49,32) , 如何来的呢? QKV一起的:reshape(B, N,3, num_head, C//num_head).permute(2, 0, 3, 1, 4), 然后QKV[0], QKV[1], QKV[2]
atte.shape = (64, 3, 49, 49)
经过attention运算,输出的维度为: (64 49,96)
经过一个fc进行维度的调整,输出: (64,49,96)
shift用 torch.roll实现

https://zhuanlan.zhihu.com/p/367111046
==================================下面是nlp中transformer的维度分析
输入: [batch, len, dim ]
Q, K, V [batch, head, len, dim/head ]
attn : [batch , head, len, len]
经过attention输出, [batch , len, dim]
经过fc进行维度调整后依然是, [batch, len, dim]
总结; 其实总结后会发现,这两个其实是一样的套路。