AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
这是一个比较有代表性的,将transformer引入cv的一个例子,其也没有特别的想法,主要创新点就是通过对图像进行patch的提取,进而构建了类似NLP的任务,然后将bert代码搬过来,进行图像的分类。
Author: Alexey Dosovitskiy
Google Brain
Abstract
- a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks
- When ==pre-trained on large amounts of data== and ==transferred to multiple mid-sized or small image recognition benchmarks== (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring sub-stantially fewer computational resources to train.(abstract这里强调了大量的数据,说明大量的数据对于transformer是很必要的)
Introduction
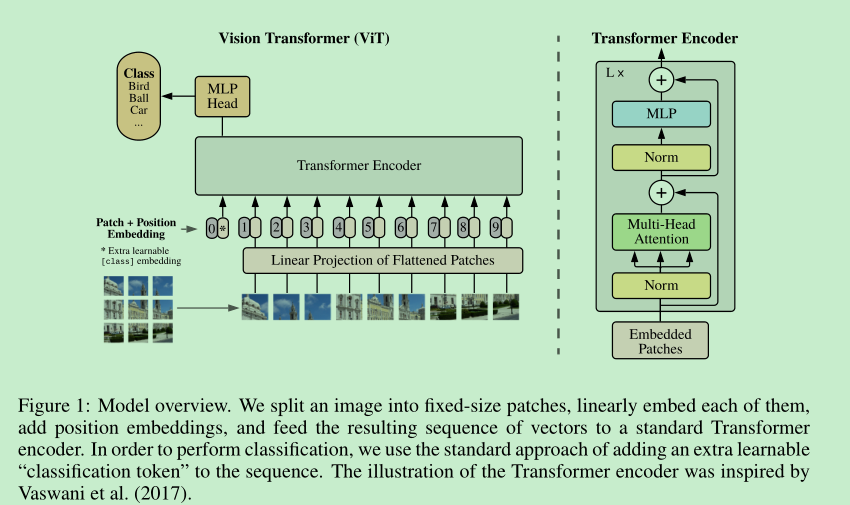
- we ==split an image into patches== and provide the sequence of linear embeddings of these patches as an input to a Transformer.
- Image patches are treated the same way as ==tokens (words)== in an NLP application.
- 同样的结论,self-Atten在中小规模数据表现略差,主要原因是self-atten的归纳能力不如cnn那么好,CoAtNet估计就是借鉴的这里,大规模数据可以解决这个问题。
Method
- NLP是2维,图像是3维,那么如何将图像像NLP迁移呢,vit通过patch进行对齐,对 H W C的图像,先取N个patch,尺寸就变成 N*(P*P*C),然后将(P*P*C),利用fc映射到一定的dim,就变成了 N * Dim,就变成了二维矩阵,就可以直接使用NLP的transformer进行训练了。想法真的挺简单的。
- 引入了[cls]token,==文中说这个是 learnable embedding,这个是咋实现的?看过代码后知道了,其实就是nn.Parameter,构造了一个可学习的参数插入到每张图像patch前面==
- 引入了postion embedding, 使用的是一维的embedding,(作者实验发现,二维并没有明显的效果), learnable
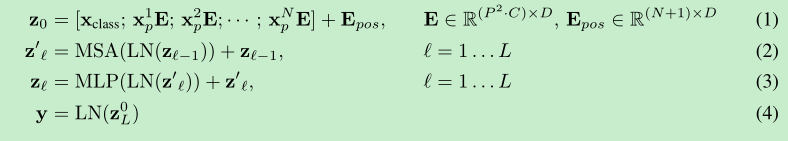
- hybrid : 除了选择原始的图像进行patch的提取,也可以在cnn得到的feature map上面提取patch,特别的,patch的大小就是1x1(后面的实验部分作者就是用的1x1)
- finetune问题,通常训练好pre-trained model后,通常在higher resolution上会有更好的效果,可是这里会遇到一个问题,当提高resolution之后,如果依然采用原来的patch的大小,那么seq的长度就会增加,之前训练的pos embedding就失效了,这里作者采用了一个2D插值方法,利用原有的位置进行插值,得到新的位置embedding.
Experiments
- train setting: batch_size:4096; adam $\beta_1=0.1,\beta_2=0.999$, dropout applied after ever dense layer
- 这里设计了3款vit,分别是 base ,large,huge, 可以看到 Huge的优势还是有一些的。
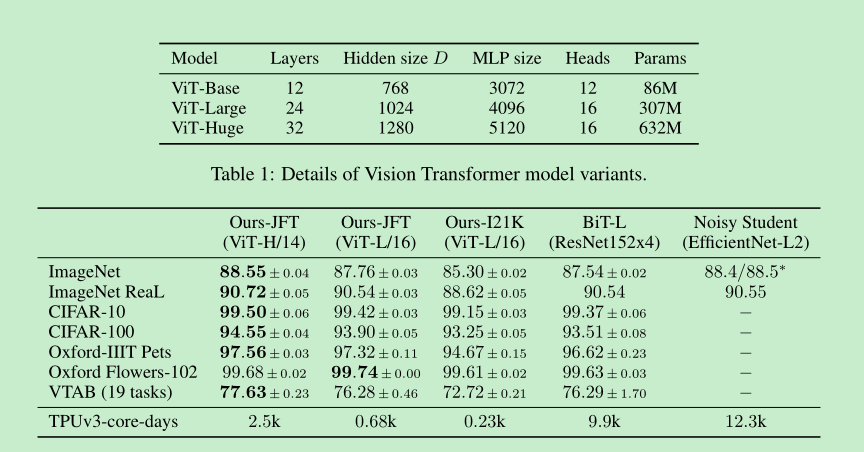
- ==那么多大的数据量是需要的呢?==做了个实验,实验都是先pretrained,再在imagenet上面finetune,在imagenet小数据集上面相比conv,transformer不行,随着数据量的增加,transformer的爆发力逐渐发挥出来。
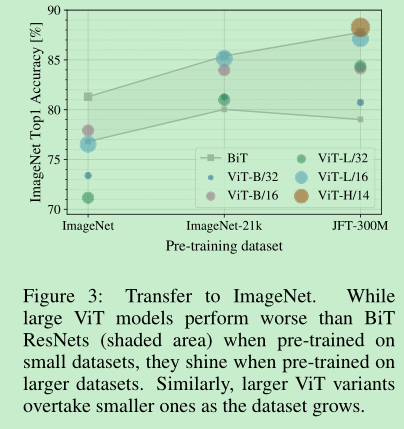
- This result reinforces the intuition that the==convolutional inductive bias==== is useful for smaller datasets, but for larger ones, learning the ==relevant patterns== is sufficient,even beneficial.
- Scaling study,对于小模型,采用hybrid方式, 实验证明是有优势的,模型大了几乎就相近了。
- self-supervision: 作者同样做了类似bert的mask的无监督实验,结果显示,在JFT数据做无监督后,会比imagenet上的pretrain高两个点,但是比在JFT有监督训练还是低了几个点。
- Adam相比SGD要好一些,但是也没有好那么多。
关键代码:
1 | self.to_patch_embedding = nn.Sequential( |
总结
这是一个比较有代表性的,将transformer引入cv的一个例子,其也没有特别的想法,主要创新点就是通过对图像进行patch的提取,进而构建了类似NLP的任务,然后将bert代码搬过来,进行图像的分类。