moco v3主要是在self-supervised中引入了vit,意图打通transformer在cv中的pretraining + finetune的范式,这篇文章应该算是一篇抛砖引玉的文章,文章框架依然采用的是instance-discrimination的范式,只不过对moco进行了进一步的修改,比如:增加了prediction head , 去掉了queue等。同时,作者团队发现了在训练vit的时候,会出现不稳定的现象,这个现象在训练BiT-ResNet的时候也会被观察到,就是会出现小波动,很不容易察觉的小波动,作者采用固定patch projection层来进行解决,虽然一定程度上解决了,但是依然没有完全解决。最后作者对比了moco v3 以及其他的一些self-supervise算法的效果,moco v3还是不错的,同时作者表明 moco v3相比于imagenet预训练的模型,更不容易过拟合,同时会有更好的效果,但是当预训练的数据很大的时候,比如 3b,那么moco v3也不一定有优势了。
论文名称:An Empirical Study of Training Self-Supervised Vision Transformers
作者:Xinlei Chen, Saining Xie Kaiming He
论文链接:https://arxiv.org/abs/2104.02057
Github:https://github.com/facebookresearch/moco-v3
论文多次提到的一篇文章: BYOL . In NeurIPS, 2020
Abstract
- vit in self-supervised learning
- 本篇paper 介绍一些将vit应用在self-supervised领域的的一些探索
- 我们发现,不稳定是降低accuracy的主要问题,并且它可能会被好的结果锁隐藏,我们揭示了,这些结果是部分的失败,当训练更稳定后,结果可以得到进一步改善。
- 我们将vit应用到moco v3中,以及一些其他的self-supervised框架,来进行多角度的分析
- 我们讨论了目前一些有用的东西,以及一些挑战。
Introduction
- 探索一些基础的组成部分: bs, lr, optimizer
- 我们发现训练vit的稳定性很重要,不稳定对vit会有一定的影响,但是这种影响也不是灾难性的,一般会掉点1-3%,而且这种掉点不易发现,一般需要与一个更稳定的对比才能发现不同。
- 根据经验,我们冻结了patch projection layer in ViT,这个trick减轻了不稳定性,并且持续的提高了acc.
- vit-large,我们自监督的预训练模型,可以比finetune的预训练模型,在tranfer learning上有很好的表现。
- 我们发现,去掉position embedding之后,vit只有小幅的下降,同时也说明了vit的position没有被有效的利用。
Related Work
- contrastive learning 一般是采用siamese network, 近期,一系列的房子表明,Siamese 结构比负样本更重要。这些方法的成功,说明,最重要的是通过匹配正样本的samples来学习特征的差异性。
MoCo v3
- infoNCE
- 去掉了queue,使用大batch size来生成正负样本:4096
- 依然使用了momentum update “key_encoder”
- a projection head + an extra prediction head(这个新加的head带来了提升,来自BYOL论文)
Stability of Self-supervised ViT Training
Basic Factors
batch size
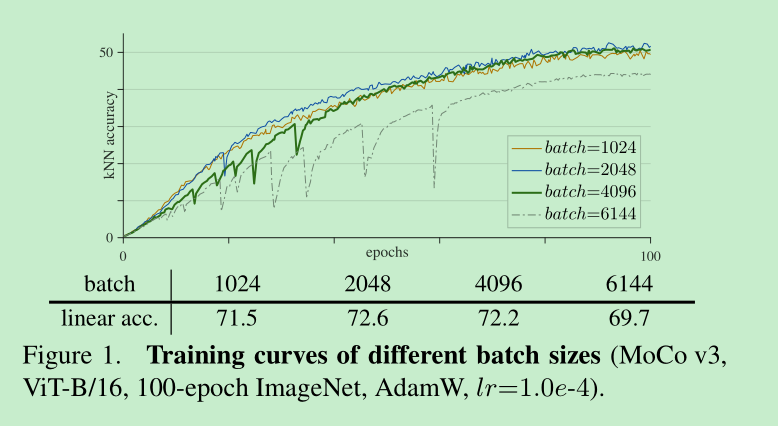
batch size的实验中发现,在batch size = 1024或者2048的时候,训练比较稳定,并且在稳步的提升,但是当继续扩大到4096之后,会发现,出现了严重的波动,并且指标没有再进一步提升了,如下:这里波动取的是 kNN acc,没有使用训练的acc,因为波动不容易觉察。
lr
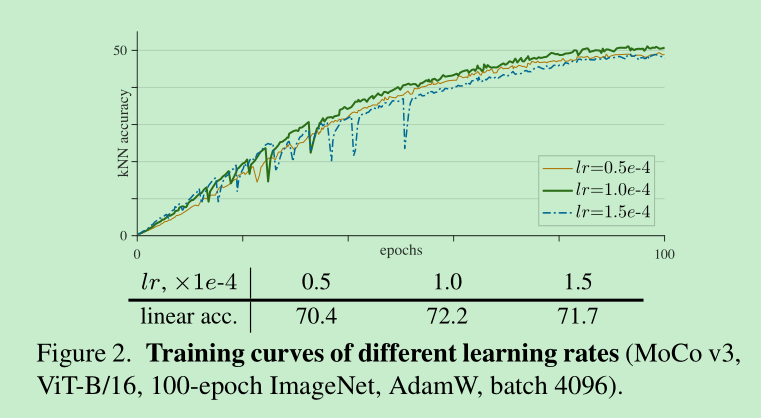
这里,所有的lr遵循一个公示: lr = base_lr * batch/256
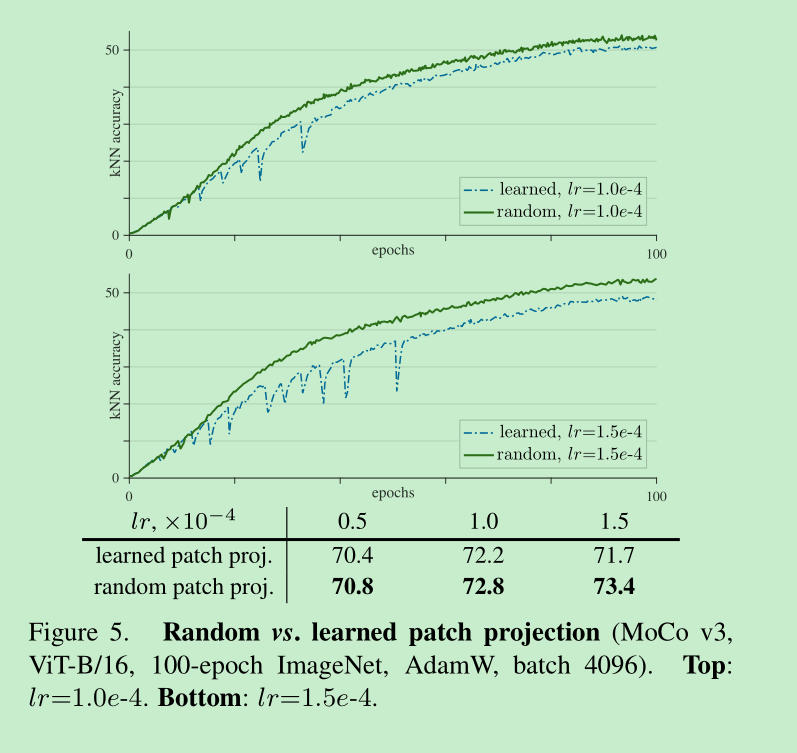
这里可以看出,当lr比较小的时候(0.5e-4),训练是比较稳定的,但是容易欠拟合,linear acc只有70.4,当增大lr的时候,比如当lr=1e-4,出现了波动,当时拟合的比价好 ,linear acc = 72.2%,继续增加就有变差了。
optimizer
vit默认使用adamw, 最近也有一些self-supervised 算法,使用LARS optimizer 来适应大的batch size,我们使用了LAMB optimizer(一种针对adamw适配LARS的优化器)
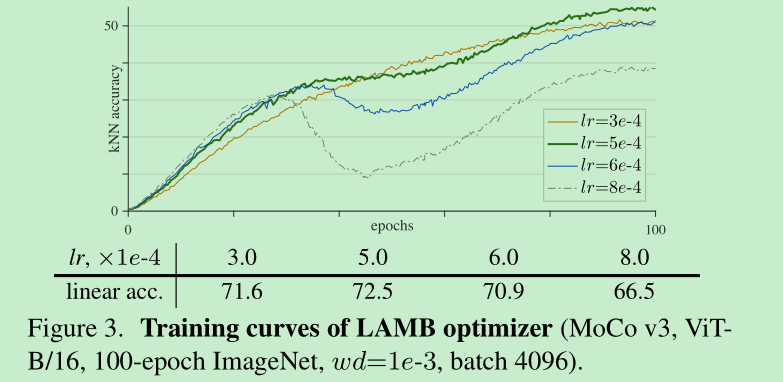
可以发现,上面的曲线平滑了很多,但是都出现了中心塌陷问题,作者猜想,虽然LAMB可以避免梯度突然的变化,但是不可靠的梯度带来的负面影响是累积的。
而且使用LAMB优化器,对lr比较敏感,所以后面实验,作者都不用了。
A Trick for Improving Stability
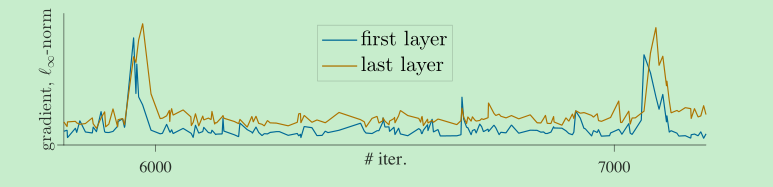
首先,把每个层的梯度值放出来,会发现,first layer的波动会比last layer要早一些, 基于此,作者认为,不稳定首先发生在浅层,于是他们将第一层(即patch 映射层)的参数冻住,不进行更新,只采用最开始的随机值,结果发现,不稳定竟然消失了,如下图5,并且结果还变好了一些,很牛逼,而且增加lr,提升变得更多了,同时作者试了其他的框架,发现其他的框架通过这个方法也变好了
总结: 这个发现就很奇妙,说明patch的映射层是没有用的,固定随机的映射也是可以的,深度学习就是这么的奇妙。。。并且作者也说,这个方法缓解了这个问题,但是当lr变得更大的时候,依然会有这个问题,所以还需要后面进一步的探索根本的解决方式。
Implementation Details
- AdamW
- bs:4096
- learning rate warmup
- MLPs 4096-d with ReLU, output MLPs are 256-d without ReLU , have BN
- Loss: loss中加入了一个$2\tau$的参数,这个参数可以使得训练在lr和wd固定的情况下对温度不那么敏感,默认情况下$\tau=0.2$,==这个是为啥,没想清楚==
- vit: 标注的vit模型,position encoding : ==use sine-cosine variant in 2-D==, add cls-token
- Linear probing: We use the SGD optimizer, with a batch size of 4096, wd of 0, and sweep lr for each case.
Exp
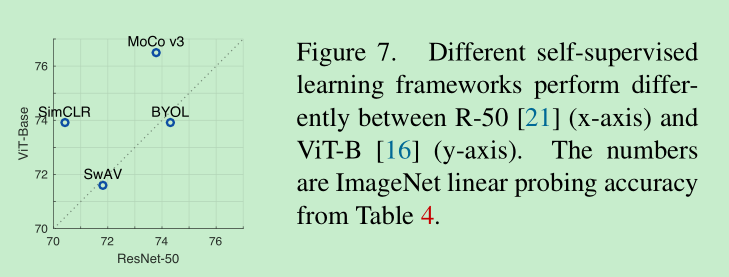
不同的自监督方法对于 resnet50 和 vit的效果的对比:可以看到,moco v3 和 simclr 对于vit是友好的,swav 和 BYOL vit和resnet相差不大。
Position Embedding:
没有position embedding,才掉点了1.6%,说明position embedding的作用没有那么大嘛,换句话说,从一堆patch中模型就能学到类别,说明具有很好的排列不变性。但是也说明其没有很好的利用位置信息

class token:
这里测试的是cls token的重要性,vit最后接的是norm 然后 + head ; 下面结论可以发现,如果是没有了cls token ,而是输出的norm直接接pooling进行分类,下降很明显; 如果同时把LN也remove了,接近76.3%,这里说明了cls不是必须的,同时说明了,layernorm可能会带来不一样的结果。
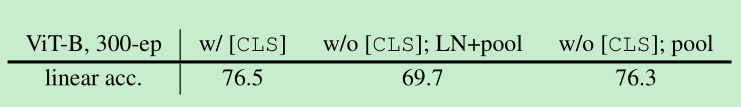
BN in MLP head:
vit中是没有BN的,所有的BN都在MLP head中,作用如何呢?下面结果说明了,没有bn也可以很好的工作,有何合适的bn可以起到锦上添花的作用。

Prediction head:
prediction head 是在BYOL论文中提到的,这里对比了有何没有的效果

momentum encoder:
m= 0.99效果最好,如果m=0 就是simclr了,moco v3没有再用queue了。说明即使不用queue了,采用momentum也是有一定效果的。
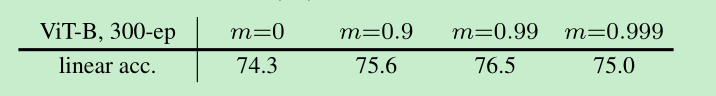
- patch越小一般 效果会越好, sequence 的长度会增加。
- 在迁移学习上的表现,imagenet采用moco v3预训练的vit,会比直接有监督预训练的迁移效果好,更不容易过拟合
- 如果预训练vit的数据足够多,效果是会超过我们的moco v3的预训练在迁移学习上的表现的
附录:
- random resized cropping, horizontal flipping, colorjittering [45], grayscale conversion [45], blurring [10], andsolarization [18].