BYOL使用了Teacher-Student架构进行自监督训练(其中Teacher Network是Student Network的历史版本的EMA),在没有任何负样本约束的情况下达到了不错的效果。本篇文章最大的创新点在于,没有使用对比学习常用的负样本,只是使用了正样本对来进行训练,关键点在于其增加的predictor,加了这个,相当于给了projection的输出结果一个缓冲,predictor是不会把参数传递给target网络的,所以这就相当于不再需要target网络的输出与online网络的输出是完全一致的,predictor还能做一轮映射,这个在减少坍塌上应该也起到了一定的作用(虽然在论文中的实验结果显示,有负样本参加训练的时候去掉predictor没掉几个点,但是只采用正样本的时候影响应该是比较大的,这个论文中没看到证明)
论文名称:BYOL(bootstrap your own latent)
GitHub : https://github.com/deepmind/deepmind-research/tree/master/byol
Abstract
- BYOL 利用2个神经网络,分别称为online和target,相互作用相互学习。
- 用online网络来预测target网络的输出,两个网络的输入是不同的augment。
- target网络的更是采用了slow-moving average的方法(momentum方法),利用online的参数来进行更新。
- BYOL不需要负样本对。
- linear evaluation上,resnet50上的表现,BYOL取得了74.3%的成绩。
Introduction
- 目前主流的图像的特征表示学习上,表现比较好的是对比学习的方法,这种方法比较依赖于样本对的选取,比如:大的batch size, memory bank ,或者是难例挖掘策略等,并且也比较依赖于图像augment的选择。
- BYOL没有采用负样本,取得了sota的水平。并且对augment更加的鲁棒
- 解决collapsed问题比较关键,比如所有图像都输出相同的vector,本文采用了两个方法,1. 在online网络上增加了预测头,2. 对于target网络的更新,使用了一个slow-moving average的方法; 这里鼓励online的投影可以encode越来越多的信息,同时避免网络崩溃。
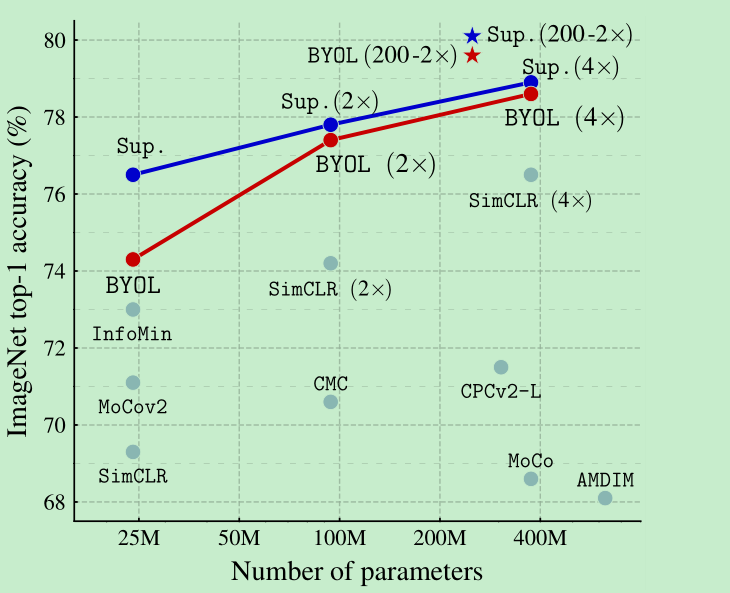
- byol效果不错,如下图,但是当只使用random crop 作为augment的时候,byol效果没有simclr效果好。
Related work
- 对比学习的方法一般使用大量的负样本,那么问题来了,使用负样本对是必须的吗?
- DeepClaster [17],用前面版本的representation作为后面representation的target,这个需要比较耗时的聚类的阶段以及预防措施避免崩溃。
- PBL是一个跟我们相似的工作。
- 在半监督中,一般unsupervised loss会组合一个classification loss来使得训练稳定,在作者后面的实验中,去掉了classification loss后出现了训练的崩溃,作为对比,byol这里加了一个预测层来避免collapse.
- 跟moco一样,byol也是使用的momentum更新技术。
Method
contrastive的方法中,通过判断不同的augment来进行discriminate图像,需要大量的负样本,这个判别任务具备一定的挑战性,来避免训练崩溃的问题。
那么这些负样本是一定要采用的吗?也就是文章的灵感来源。
如果固定住初始化的网络来产生target,这样可以避免训练崩溃的问题,但是这样无法得到好的特征表示,但是这样做已经比初始化固定的特征表示效果要好了。
那么我们是不是,阶段性的替换掉初始化固定的那个网络就可以得到越来越好的结果了呢?
Description of BYOL
- 结构如下图:
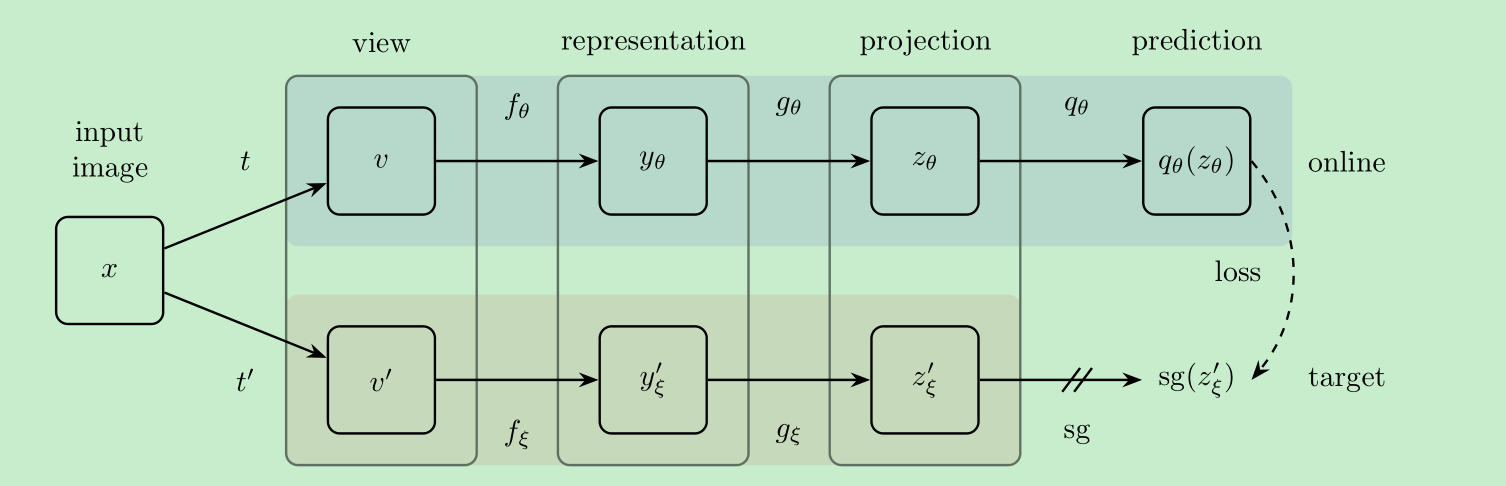
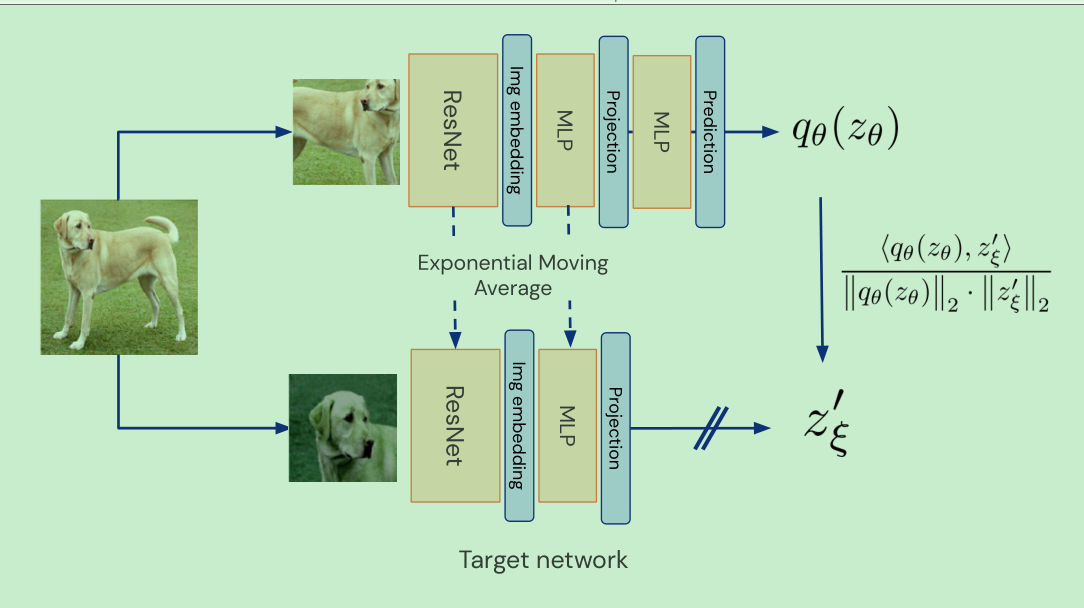
teacher是由online 更新来的
online会多一个predict layer , target没有这个layer,使得两个网络为非对称网络
loss采用的是简单的平方差loss,下面那个公式带hat的loss将 输入网络的v 和 v’互换后送入网络,计算的loss
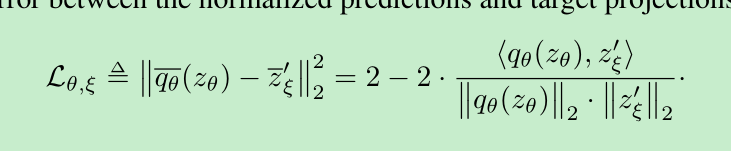
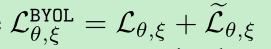
- 最终在下游任务中,我们只会使用$f_{\theta}$
Intuitions on BYOL‘s behavior
- BYOL训练没有崩溃的主要原因在于,BYOL的target网络参数的更新不是通过梯度计算的
Implementation details
- augmentations as in simCLR
- projection 的结构跟simclr也是一样的,并且predict layer也采用更projection相同的结构。默认情况下,projection和predictor的layer数量是2,如下代码:
- LARS optimizer, cosine decay, base lr = 0.2 , weight decay = 1.5e-6
- momentum的变化是动态进行的 最开始是0.996,然后越来越大,直到1.
1 | class MLP(nn.Module): |
Exp
Linear evaluation on ImageNet: res50达到了74.3%, res200(x2) 达到了79.6%
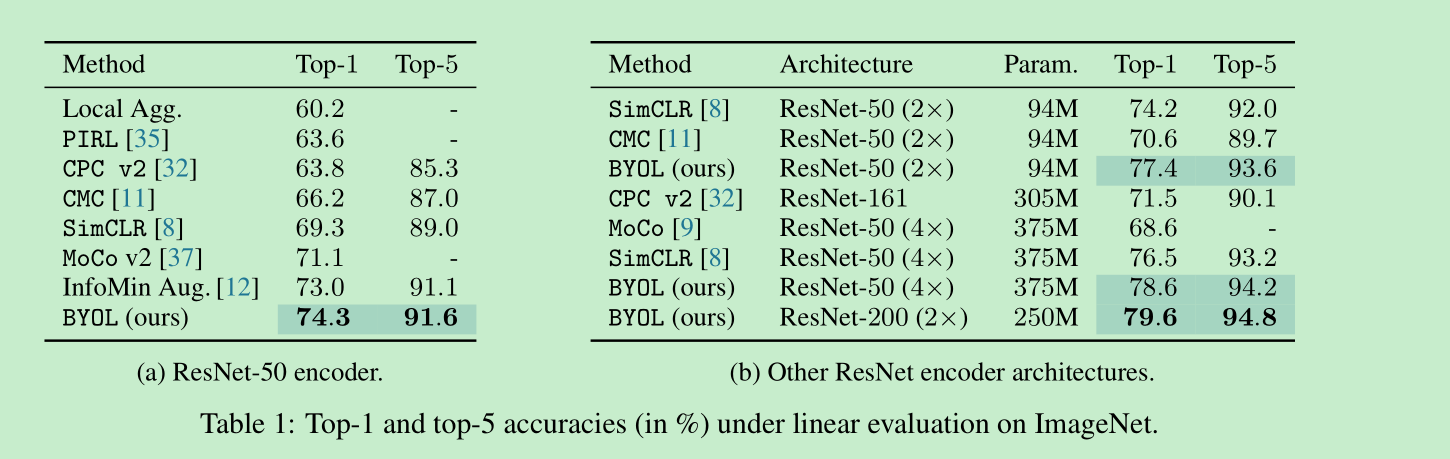
迁移性如何呢?,应该说基本都超过了simclr,在多个任务上甚至超过了supervised
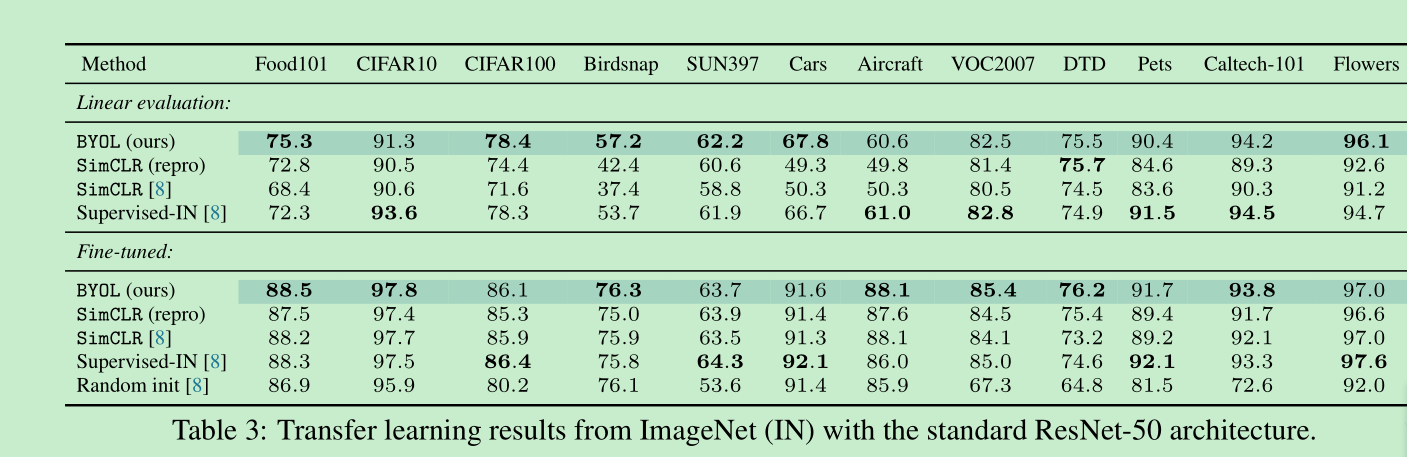
实验证明在voc也是有效的,这里不贴图了。
Building intuitions with ablations
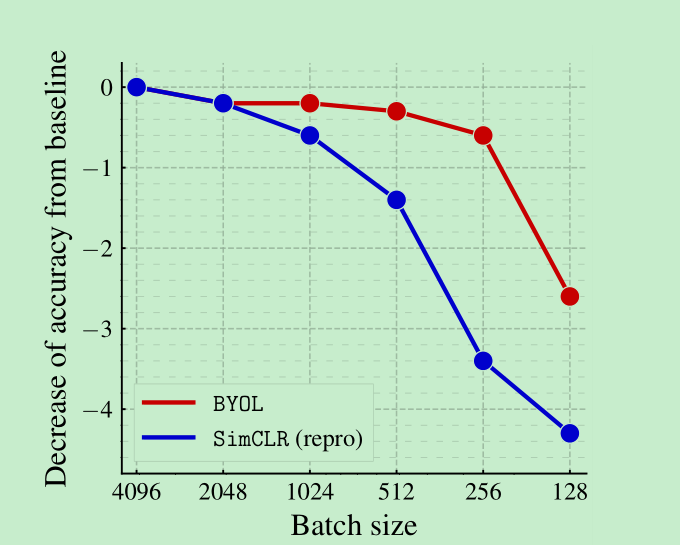
Batch Size的影响:simclr由于负样本的数量减少快速的下降,byol并没有,在256->128这里才快速的下降,这里作者解释下降的原因是bn layer,因为只有这个是跟bs有关的。
augment的探索,这里作者说,说相同的图像的不同crop会共享图像的颜色直方图,这样就简单化了,使得网络不care其他信息了,所以simclr在这个基础上又加上了color jitter来进行调整。
相比较于simclr,byol对于augment就会更加的鲁棒,因为online和target的网络不是同时更新的,所以会迫使online学到更多的信息,实验事实也证明,确实byol对augment更加的鲁棒
动量参数的探索:0不行,1也不行,0.99以上比较好

==探索一下target network以及predict layer的作用==
加了target network是有用的,对simclr加了target network后也涨点了,但是loss的参数需要做相应调整,比如温度会调整为0.3,而不是0.1,这说明moco的方法,不仅仅在增加负样本方面有作用,在byol中并没有采用负样本,也有一定的作用。补充材料里进一步说明:使用target network,一个作用是在预测target的时候,没有使用梯度回传,第二个是可以稳定训练。那这两个到底哪个影响比较大,作者进一步对比table 19 显示,可以看simclr加不加sg,效果相差不大,说明主要产生作用的其实是训练的稳定性。
simclr 加 predictor layer是没有作用的。
下面的$\beta$参数代表是否使用负样本。
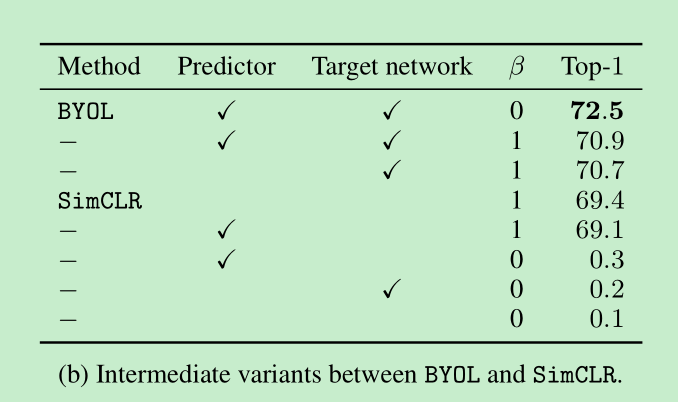
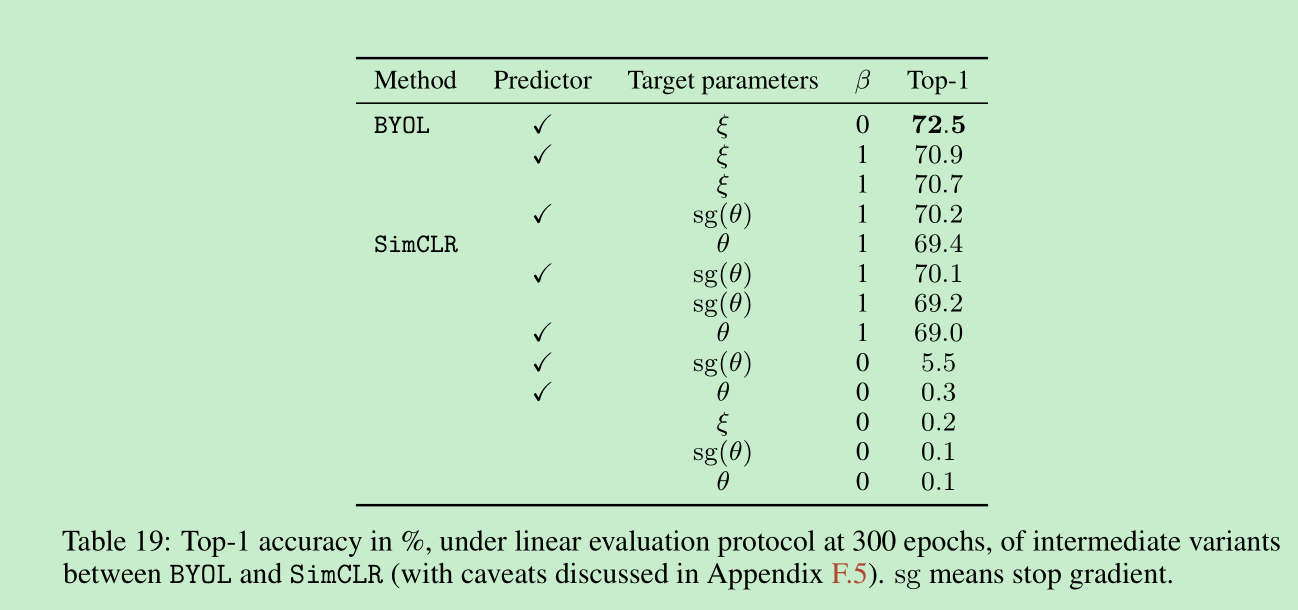
- predictor是防止训练崩溃的关键
- predictor和target network缺一不可,但如果采用最优的predictor可以去掉target network,那么如何得到最优的predictor,可以提高predictor的学习率。。。