dino最惊艳的地方在于,作者发现,dino+vit的结果对图像的弱监督具有很好的效果,效果很惊艳,也是这个结果吸引了我。另外,本文的思想跟byol比较像,主要创新点在于:1.将vit应用到了self-supervise中,提出了dino. 2.dino没有采用负样本,跟byol一样,dino避免训练坍塌的方式是采用了centering + sharping + momentum,另外还有一个值得提到的点是,dino不仅仅在linear evaluation表现比较好,在knn上表现也是比较好的
论文名称:DINO,Emerging Properties in Self-Supervised Vision Transformers
作者:Facebook AI Research
论文链接:https://arxiv.org/abs/2104.14294
Github:https://github.com/facebookresearch/dino
Abstract
- 自监督的vit包含了明确的语义分割的信息,这在卷积中是没有出现的
- small_vit 的特征在kNN上的表现可以达到78.3%
- momentum encoder, multi-crop training ,vit
- self-distillation with no labels
Introduction
一些卷积或者监督的vit所没有的特性
自监督的vit特征明确包含了场景的输出,特别是物体的边缘,网络的最后block可以得到这些信息
k-NN 效果表现就很好。
kNN表现好室友条件的,必须有特点的组件比如:momentum encoder 和 multi-crop augmentation。
smaller patches 效果会更好。
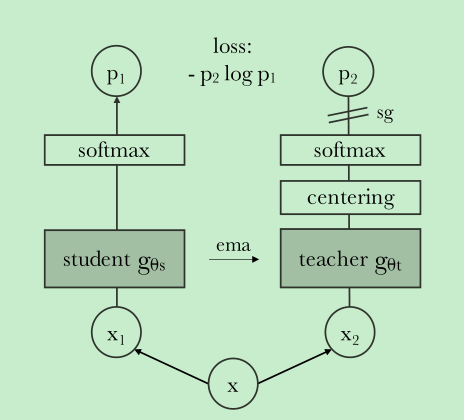
为避免训练崩溃,我们方法只对teacher的输出采用了中心和锐化操作。其他的比如:predictor contrastive loss 对稳定性和表现只有一丢丢丢的作用。
Related work
- 我的蒸馏 teacher是动态变化的
Approach
两个概率的相似度的loss: -alogb, ==本文就是采用的这么简单的loss==
如何做的?
- 取2个全局的views和若干个local views,全局views是224x224的,local view是96x96的,全局view过teacher,local view过student。
- 这个loss是怎么算的呢?看下面的代码,简单来说就是循环对所有的结果做对比
- teacher和student的网络结构相同,但是参数不共享
for iq, q in enumerate(teacher_out): for v in range(len(student_out)): if v == iq: # we skip cases where student and teacher operate on the same view continue loss = torch.sum(-q * F.log_softmax(student_out[v], dim=-1), dim=-1) total_loss += loss.mean() n_loss_terms += 1 total_loss /= n_loss_termsema方式更新teacher,momentum在0.996-1
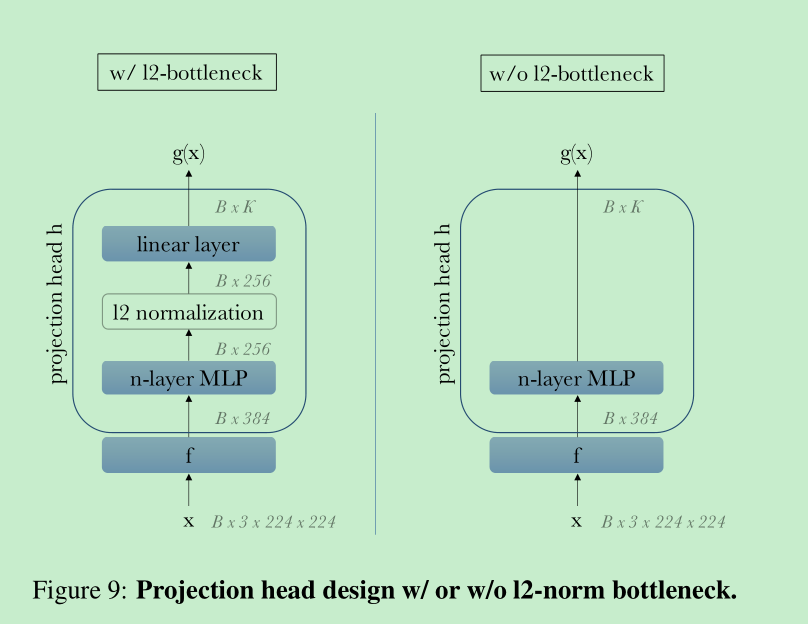
使用了projection head (3MLP + 2048 + l2 norm),但是下游任务还是使用的backbone的输出
center and sharpening
implement details
a. adamw, bs=1024, lr = 0.0005 * bs / 256, cosine, weight_decay also 0.04 -> 4, stu_temperature =0.1, tea_temperature = 0.04 -> 0.07(first 30 epochs)
b. follow BYOL augmentations + multi-crop
网络对超参数挺敏感的
20NN效果表现是比较好的

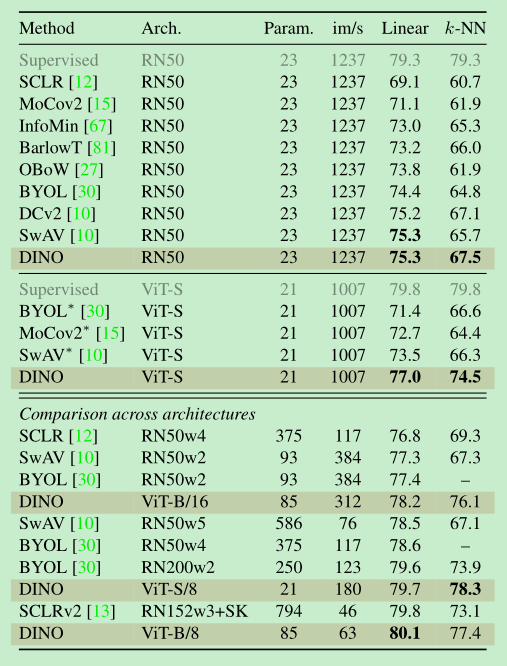
Main Result
如下结论:
dino 在 resnet50和vit上面都是有效的
==vit上面,表现尤为突出,超过了其他的方法,同时knn和linear表现都很好,而且二者比较相近==
dino在取patch=8的时候,表现会更好
跨结构相比,可见vit版dino可以用更少的参数取得更好的效果。
在图像检索方面,dino的表现也是很好的
[cls]不同的head的attention map打印出来,可以发现不同的head会get到不同的信息,如下图:并且,可以发现的是,dino 得到的分割信息会比supervised方法得到的更准确。


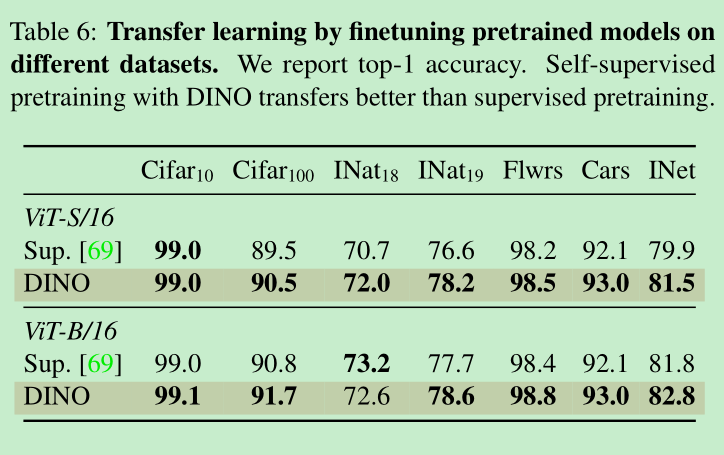
- transfer learning的效果更好:
Ablation Study
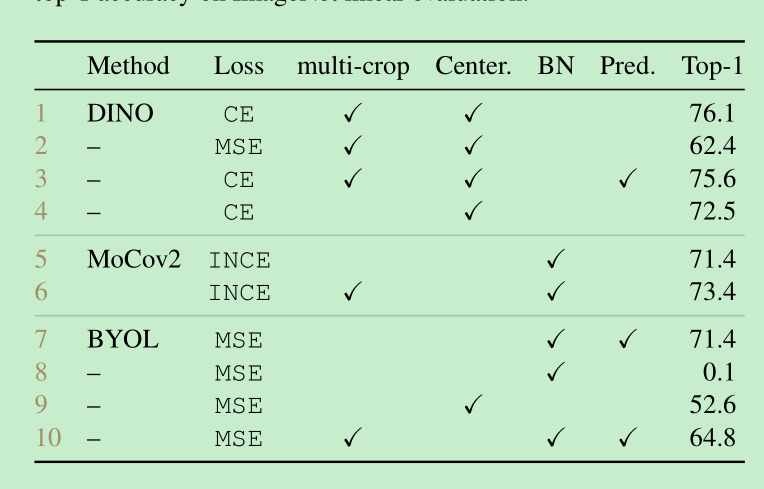
- 各个组件的作用,可以看到momentum比较重要,ce比较重要,mc 比较重要
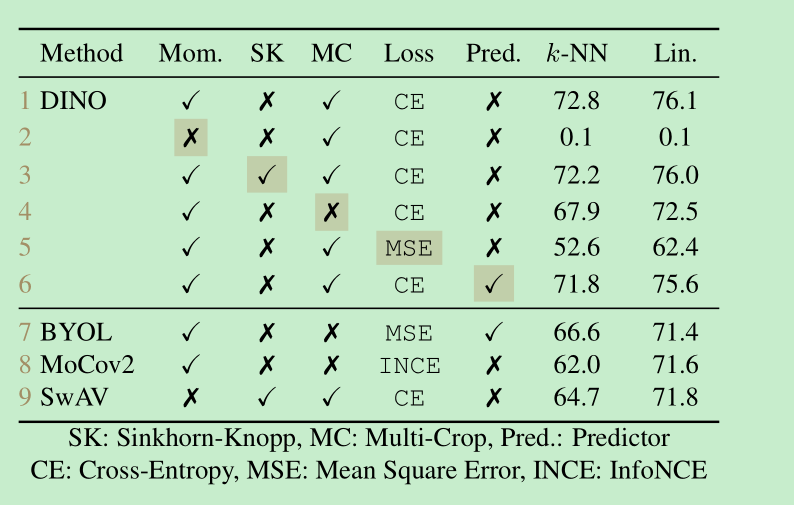
降低patch的大小,可以有效的提高表现,但是带来的后果就是,模型的速度会降低的比较明显,比如8x8到5x5 ,速度会从180->44,降低为原来的1/4
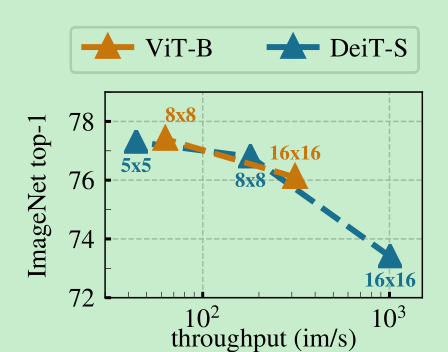
不同的teacher更新策略,如果每个epoch更新一下,效果还可以,每个iter更新一下,不收敛,momentum方法,效果最好。下图(b)
下图(a)想表达的是,在训练的过程中,teacher的效果一直是要优于student的效果的。这在其他的框架中都没有发现,epoch更新的时候也没有这个效果,作者解释,这可能是由于采用了类似于Polyak-Ruppert average导致的,简单理解就是做模型的ensemble来提升效果。teacher一直比student好自然可以蒸馏出更好的student.
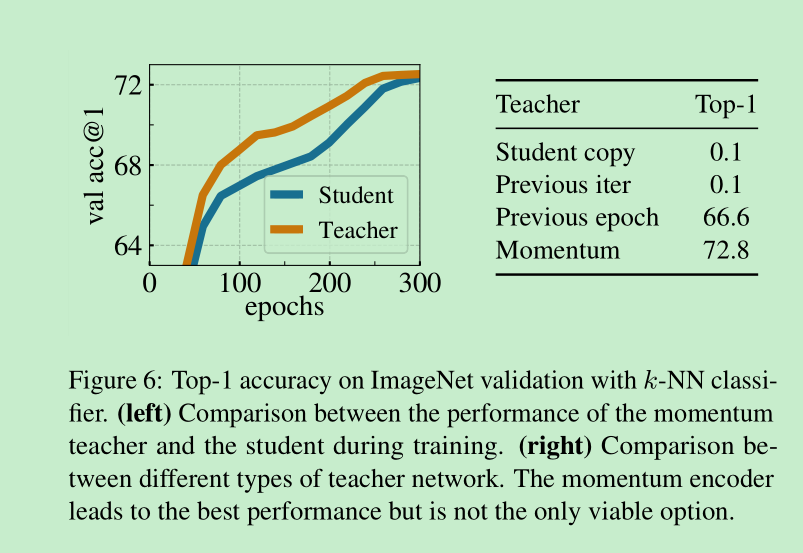
collapse的研究:
batchsize 对于网络的影响不大,bs=128相比bs=1024只有小幅的下降。
byol,moco-v2,的对比分析:
head的转变:MLP中使用的是GeLU, vit没有bn, MLP输出为256,l2norm后,接linear layer,输出是K=65536, ==这里输出的K=65536我觉得应该挺重要的==,待后面探索一下。