这篇是openai在多模态领域的一大力作,关注度很高,也掀起了大家对自然语言监督视觉训练的一个浪潮,文章中的方法其实比较简单,利用图像文本对,利用对比学习进行训练而已,训练完了之后,利用文本进行检索就可以了,实现了zero-shot,并且效果还很好,就很惊人。并且文章中新建了一个4亿的图像文本对,也起了大作用。前面也有人是这么干的,没有这么好的效果,主要是因为数据量不够。
论文名称:Learning Transferable Visual Models From Natural Language Supervision
作者:OpenAI
论文链接:https://arxiv.org/abs/2103.00020
Github:https://github.com/OpenAI/CLIP
一些基于clip的产物:styleclip、clipdraw、视频检索、how to train really large models on many gpus
Abstract
- 如果可以直接利用language来作为图像的监督信息进行训练,将极大的拓展学习的边界(这样就不会受限于标注的类别)
- 预训练任务: 判断哪个图像跟文本是配对的。
- 400million的数据对。
- zero-shot transfer
Introduction
- 在nlp的任务中,依赖网络搜索的数据,已经可以打败人工标注(crowd-labeled)的数据集。
- 为啥研究文本-图像联合训练的人比较少呢?主要是因为利用文本作为监督信息,取得的zero-shot transfer的效果不是很好,所以更多的人来研究如何使用弱监督来提高模型的效果,比如采用jft-300M的数据集等等。
- 目前方法中 , 从自然文本中学习 与 从弱监督标注数据中学习 有一个关键的不同点是 规模,主要是从文本中学习的数据规模太小了。
- lineaar-probe效果很好。zero-shot 效果很好。
Approoach
- Learning from natural language also has an important advantage over most unsupervised or self-supervised learning approaches in that it doesn’t “just” learn a representation but also connects that representation to language which enables flexible zero-shot transfer.
- 构建WIT数据集 ,含有大约4亿的图像文本对。
- 方法的选择上,高效是很必要的。
- 近期在视觉任务上的表示是说,对比目标比预测目标可以学到更好的特征表示。生成的方法可以得到更好的特征表示,但是往往需要更多的计算。【Generative pretraining from pixels】,基于此呢,作者团队设计的比较高效的方法是将文本当成是一个整体与图像配对,而不去管文本中具体的单词
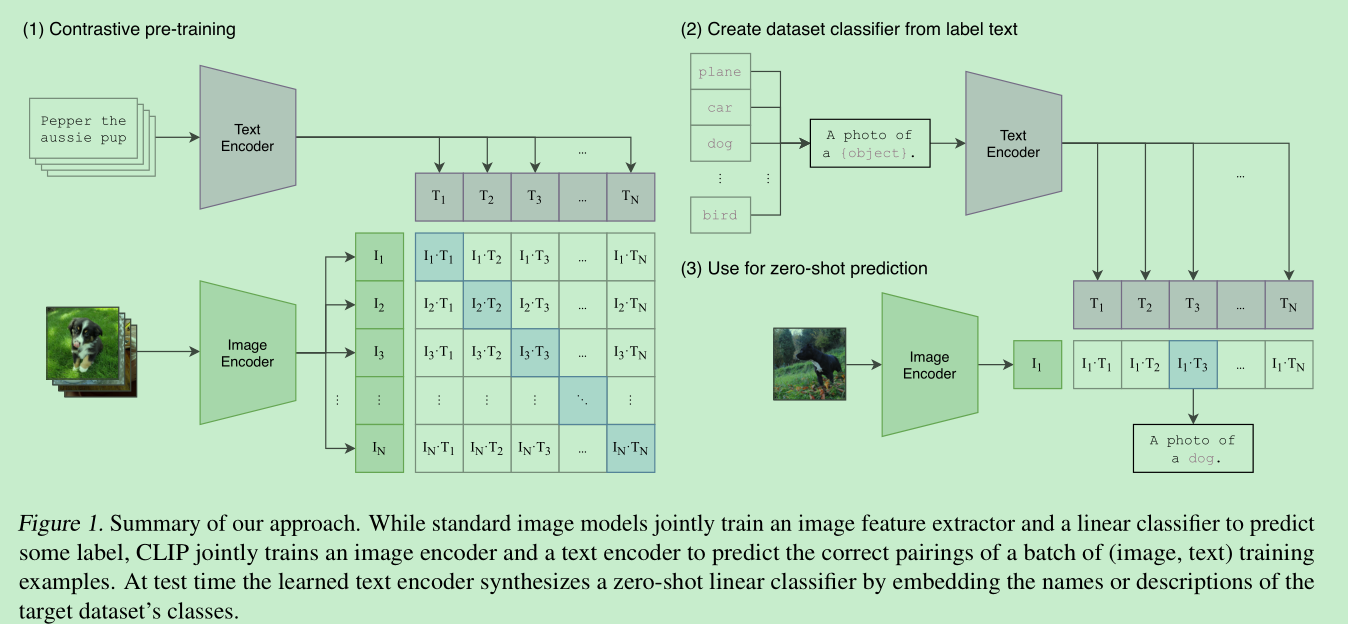
- 具体方法如下图:
- 论文中这么描述:clips learns a multi-modal embedding space by jointly training an image encoder and text encoder to maximize the cosine similarity of the image and text embeddings of the N real pairs in the batch while minimizing the cosine similarity of the embeddings of the N2− N incorrect pairings.
- 所以模型 从头开训的
- 在特征表示与contrastive loss之间 并没有使用非线性映射。
- 只使用了random crop resize这个初始化,其他都没有使用。
- resnet50, replace global average pooling to attention pooling mechanism【QKV】
- text: transformer, max sequence length is 76
- train 5 resnet and 3 vit
- train 32 epochs
- adam , cosine schedule
- minibatch size : 32768
- mixed-precision

Exp
zero shot transfer
- image encoder and text encoder 计算特征
- 特征计算cosine 相似度
- softmax 找最大
- text的特征可以复用,提一遍就可以了。
PROMPT ENGINEERING AND ENSEMBLING
- 作者使用 模板 :A photo of a {label} 来进行匹配,主要解决预训练就是用的句子的的原因。这带来了大约1.3%的提升。
- 另外加上提示信息会更有用,比如: a photo of a {label}, a type of pet
- 另外可以加上 引号:“”,
- a satellite photo of a {label}
- 组合多个提示词,进行召回。
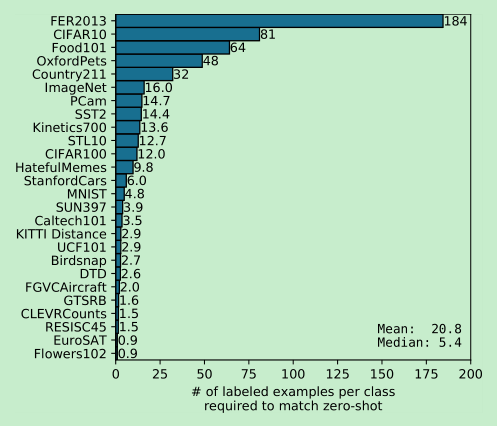
在一些较难的任务上,研究zero-shot是比较好的吗?(zero-shot跟few-shot是对立的),比如肿瘤细胞的图像分类,zero-shot合适吗?
zero-shot的效果很好,超过了resnet的16-shot,而 clip的few-shot,平均需要4-shot来达到zero-shot的能力。
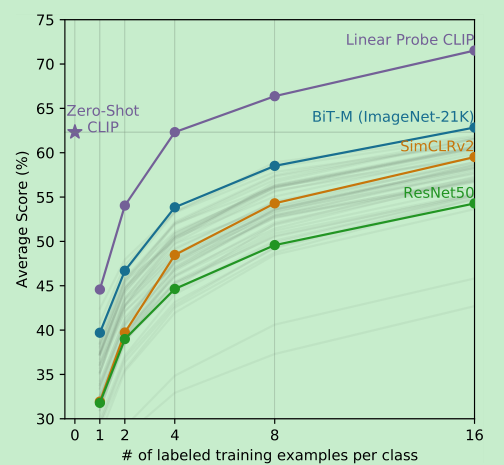
利用few-shot 训练 linear-probe 来达到zero-shot的能力,各个数据集需要的数据量:imagenet大约是16-shot
在few-shot的实验中,我们做的是linear classifier,由于固定住了网络参数,而且本身网络的分类层也是线性的,再加一个线性分类层相当于扩大了原来的边界( because CLIP’s zero-shot classifier is also a linear classifier, the performance of the fully supervised classifiers roughly sets an upper bound for what zero-shot transfer can achieve. )
往往,越大的网络,zero-shot的表现会更好。
==linear-prob的超参数比较少,也比较好调节。方便训练多个任务进行对比==
在linear-probe实验中,clip在大部分的任务上都超过了最好的label监督的网络,并且,确实对比学习为代表的self-supervised 的方法要表现的更好一些。在比如cifar10这种数据上表现不太好,可能是网络训练时候这种样本太少了的缘故。
为什么imagenet上表现很好,但是换到其他的任务上表现就没那么好了呢?研究表明,深度学习的可以通过训练数据来找到数据间的模式和相关性,来帮助他们提高内在表现。但是这些相关性和模型不一定是对的,所以在换到其他分布数据的时候可能会带来性能的下降
clip 具有更高效的鲁棒性与泛化能力
由于在预训练使用了更大的数据集以及文本作为监督信息,其具有更好的鲁棒性,无论是zero-shot还是fine-tuned.
大的数据集也有一个不好的点,就是数据集很大,评估数据都在数据集中出现过了,评估就不准确了
Limitation
- zero-shot 目前还做不到sota,扩大规模可以稳定的提升模型效果,但是我们估计需要1000x的规模才能达到sota的效果。
- 细粒度分类效果不太行
- 抽象任务不太行
- 不能动态生成图像的caption, 【后续可以考虑使用contastive and generative objective 方法组合】
- 数据依赖严重,数据利用率的低效性。
- 利用现有的supervised dataset来对比zero shot的效果不好,并不是真正的zero-shot,因为可以利用validation set进行调节。
- 利用linear classifier 进行few-shot并没有体现很大的优势,人类在one-shot会有很大的提升,但是clip却没有。这里需要进一步的探索增强。
- zero-shot => one-shot learning 是可以探索的方向。