这篇论文表现比较好,论文的创新点还是比较多的。blip不仅可以实现文本-图像的匹配,同时还可以根据图像生成文本,以及根据图像进行问答等。作者在预训练的时候,一方面采用了像clip中那样的图像-文本对比学习,同时增加了一个encoder,进行multi-task任务用来预训练ITM以及LM,这些任务是共享encoder的参数的。ITM任务就比较简单,就是设计个分类头,进行二分类的判断。LM采用的是自回归的方式进行生成的。
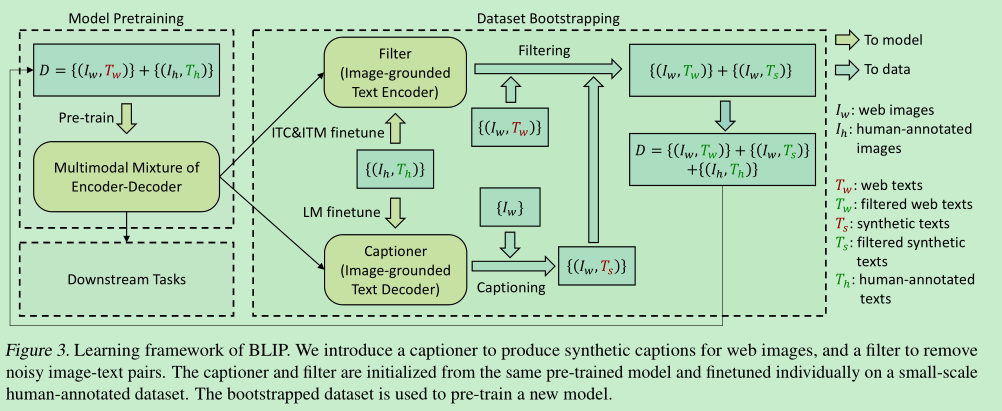
另外,作者发现,网络采集的图像-文本对,由于没有标注,很多是错误的,所以作者又在预训练好的模型上finetune了一个清洗过滤模型,生成新的图像-文本信息。取得了更好的效果。
在预训练结束后,可以根据各自的任务,在预训练模型上进行finetune,实现不一样的功能。
论文名称:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
作者:Junnan Li
论文链接:https://arxiv.org/abs/2201.12086
Github:https://github.com/salesforce/BLIP
作者先导文章:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
Abstract
- 现在的预训练方法,要么是理解的任务要么是生成的任务。
- 效果的提升 比较依赖 数据集的规模,但是现在建立的数据集 基本都是 noisy的。
- blip可以灵活的适用于 理解任务以及生成任务。
- blip 使用 一个captioner 生成 合成的caption,同时使用一个filter进行noisy caption的过滤。
- image-text retrieval + 2.7%; image captioning +2.8% in CIDEr ; VQA + 1.6% in VQA score
Introduction
blip适用于多种下游任务
blip的创新点:
- multimodal mixture of encoder-decoder
- pretraining联合训练三个任务:image-text contrastive learning , image-text matching ,image-conditioned language modeling
- captioning and filtering
Method
ITC
- contrastive learning
ITM
- 二分类问题
- 采用了难例挖掘来选择样本
Language Modeling
- 自回归方法生成句子
ITM和language modeling是共享参数的,除了sa layer,因为除了da基本都是相同的,而共享参数,更有利于multi-task,提高训练效率。
CapFilt
caption和filter都是用预训练好的模型进行初始化,然后finetune在coco数据集
caption: 是一个decoder,给图像用来合成 “描述”
filter:是一个encoder,finetuned with ITC和ITM,用来判断句子和图像是不是匹配的。
利用caption和filter,组合成一个新的数据集,然后再重新pretrained一个新的模型。
Exp and Dis
two 16-GPUs
image encoder: vit, text encoder: bert-base
pretrained : batch-size:2000+, 20epoch
pretrained on 224x224, finetuning on 384x384
训练数据量 14M
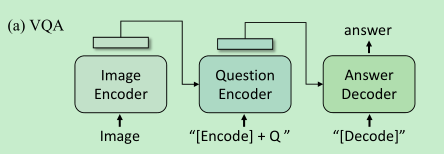
VQA: 当成生成式任务来做,采用如下方式进行finetune