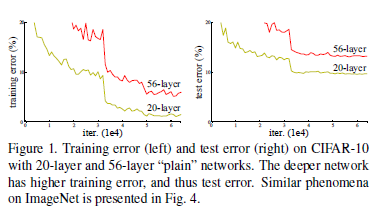
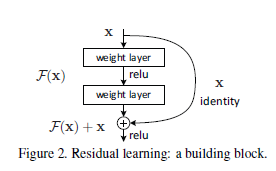
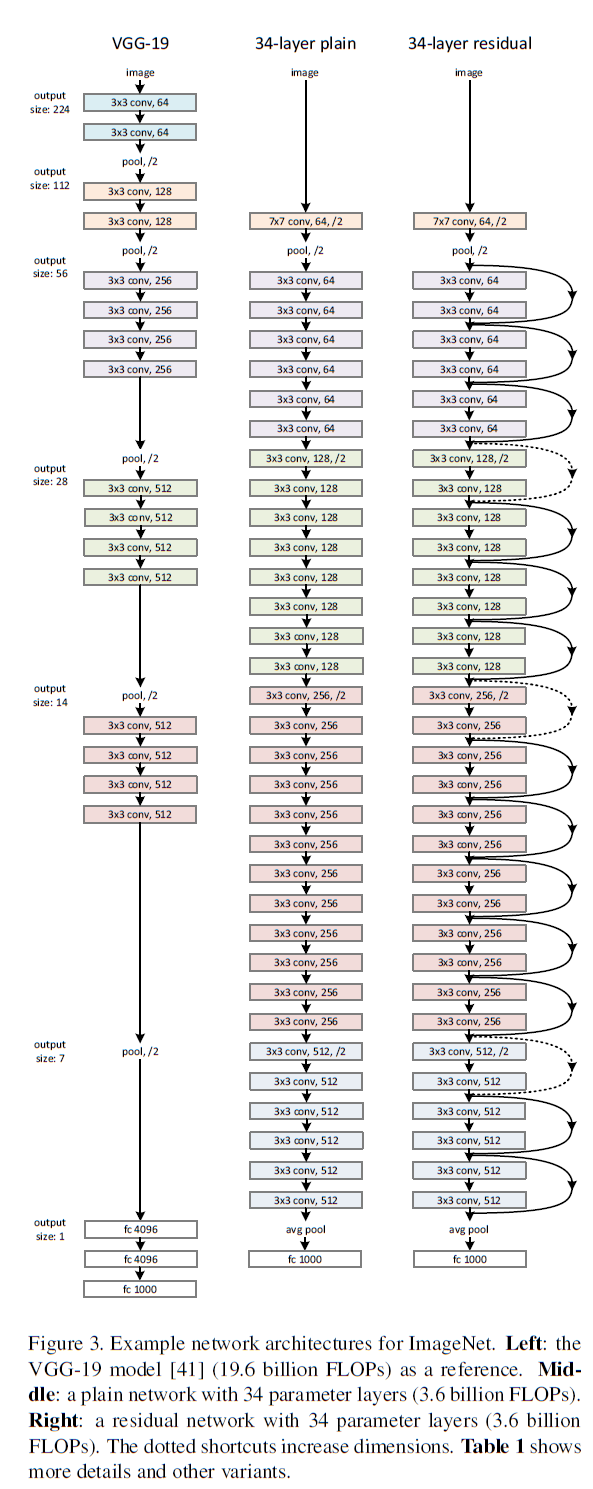
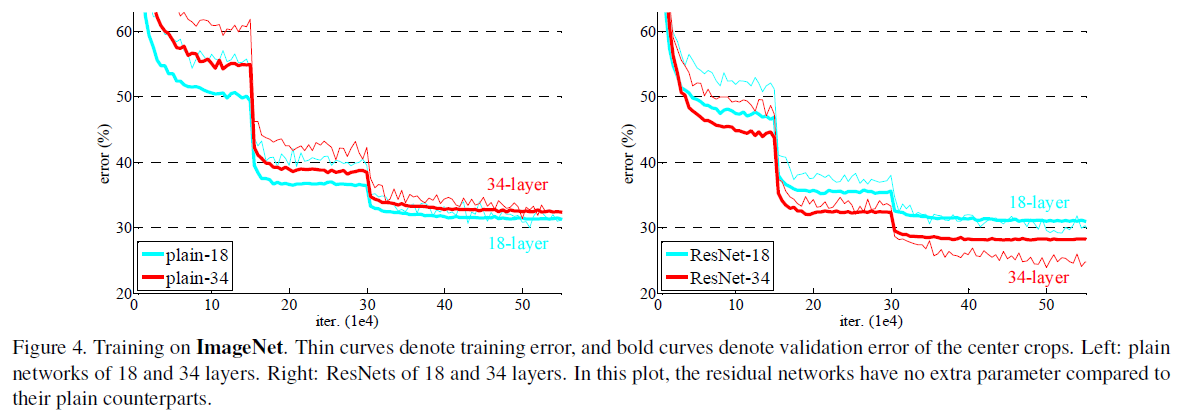
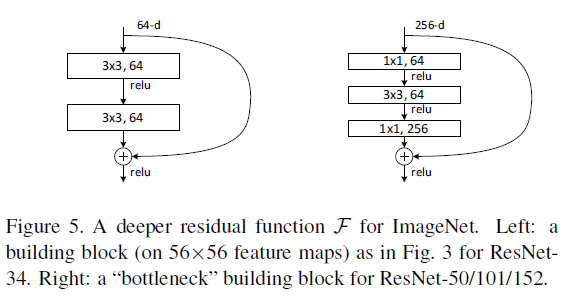
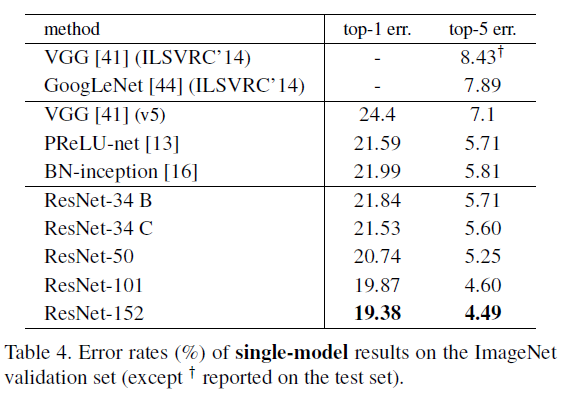
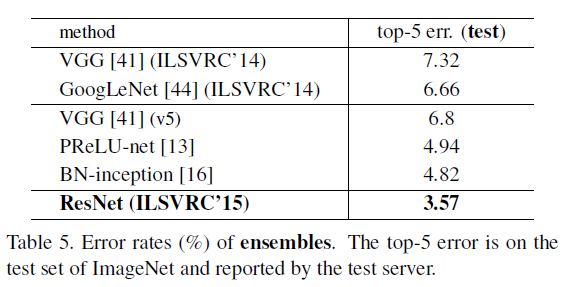
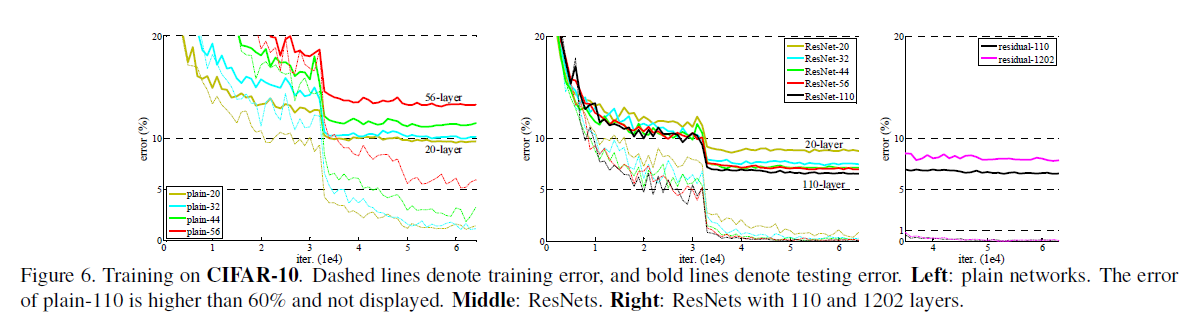
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
|
def residual_unit(data, num_filter, stride, dim_match, name, bottle_neck=True, bn_mom=0.9, workspace=256, memonger=False):
"""Return ResNet Unit symbol for building ResNet
Parameters
----------
data : str
Input data
num_filter : int
Number of output channels
bnf : int
Bottle neck channels factor with regard to num_filter
stride : tuple
Stride used in convolution
dim_match : Boolean
True means channel number between input and output is the same, otherwise means differ
name : str
Base name of the operators
workspace : int
Workspace used in convolution operator
"""
if bottle_neck:
bn1 = mx.sym.BatchNorm(data=data, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_bn1')
act1 = mx.sym.Activation(data=bn1, act_type='relu', name=name + '_relu1')
conv1 = mx.sym.Convolution(data=act1, num_filter=int(num_filter*0.25), kernel=(1,1), stride=(1,1), pad=(0,0),
no_bias=True, workspace=workspace, name=name + '_conv1')
bn2 = mx.sym.BatchNorm(data=conv1, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_bn2')
act2 = mx.sym.Activation(data=bn2, act_type='relu', name=name + '_relu2')
conv2 = mx.sym.Convolution(data=act2, num_filter=int(num_filter*0.25), kernel=(3,3), stride=stride, pad=(1,1),
no_bias=True, workspace=workspace, name=name + '_conv2')
bn3 = mx.sym.BatchNorm(data=conv2, fix_gamma=False, eps=2e-5, momentum=bn_mom, name=name + '_bn3')
act3 = mx.sym.Activation(data=bn3, act_type='relu', name=name + '_relu3')
conv3 = mx.sym.Convolution(data=act3, num_filter=num_filter, kernel=(1,1), stride=(1,1), pad=(0,0), no_bias=True,
workspace=workspace, name=name + '_conv3')
if dim_match:
shortcut = data
else:
shortcut = mx.sym.Convolution(data=act1, num_filter=num_filter, kernel=(1,1), stride=stride, no_bias=True,
workspace=workspace, name=name+'_sc')
if memonger:
shortcut._set_attr(mirror_stage='True')
return conv3 + shortcut
else:
bn1 = mx.sym.BatchNorm(data=data, fix_gamma=False, momentum=bn_mom, eps=2e-5, name=name + '_bn1')
act1 = mx.sym.Activation(data=bn1, act_type='relu', name=name + '_relu1')
conv1 = mx.sym.Convolution(data=act1, num_filter=num_filter, kernel=(3,3), stride=stride, pad=(1,1),
no_bias=True, workspace=workspace, name=name + '_conv1')
bn2 = mx.sym.BatchNorm(data=conv1, fix_gamma=False, momentum=bn_mom, eps=2e-5, name=name + '_bn2')
act2 = mx.sym.Activation(data=bn2, act_type='relu', name=name + '_relu2')
conv2 = mx.sym.Convolution(data=act2, num_filter=num_filter, kernel=(3,3), stride=(1,1), pad=(1,1),
no_bias=True, workspace=workspace, name=name + '_conv2')
if dim_match:
shortcut = data
else:
shortcut = mx.sym.Convolution(data=act1, num_filter=num_filter, kernel=(1,1), stride=stride, no_bias=True,
workspace=workspace, name=name+'_sc')
if memonger:
shortcut._set_attr(mirror_stage='True')
return conv2 + shortcut
def resnet(units, num_stages, filter_list, num_classes, image_shape, bottle_neck=True, bn_mom=0.9, workspace=256, dtype='float32', memonger=False):
"""Return ResNet symbol of
Parameters
----------
units : list
Number of units in each stage
num_stages : int
Number of stage
filter_list : list
Channel size of each stage
num_classes : int
Ouput size of symbol
dataset : str
Dataset type, only cifar10 and imagenet supports
workspace : int
Workspace used in convolution operator
dtype : str
Precision (float32 or float16)
"""
num_unit = len(units)
assert(num_unit == num_stages)
data = mx.sym.Variable(name='data')
if dtype == 'float32':
data = mx.sym.identity(data=data, name='id')
else:
if dtype == 'float16':
data = mx.sym.Cast(data=data, dtype=np.float16)
data = mx.sym.BatchNorm(data=data, fix_gamma=True, eps=2e-5, momentum=bn_mom, name='bn_data')
(nchannel, height, width) = image_shape
if height <= 32:
body = mx.sym.Convolution(data=data, num_filter=filter_list[0], kernel=(3, 3), stride=(1,1), pad=(1, 1),
no_bias=True, name="conv0", workspace=workspace)
else:
body = mx.sym.Convolution(data=data, num_filter=filter_list[0], kernel=(7, 7), stride=(2,2), pad=(3, 3),
no_bias=True, name="conv0", workspace=workspace)
body = mx.sym.BatchNorm(data=body, fix_gamma=False, eps=2e-5, momentum=bn_mom, name='bn0')
body = mx.sym.Activation(data=body, act_type='relu', name='relu0')
body = mx.sym.Pooling(data=body, kernel=(3, 3), stride=(2,2), pad=(1,1), pool_type='max')
for i in range(num_stages):
body = residual_unit(body, filter_list[i+1], (1 if i==0 else 2, 1 if i==0 else 2), False,
name='stage%d_unit%d' % (i + 1, 1), bottle_neck=bottle_neck, workspace=workspace,
memonger=memonger)
for j in range(units[i]-1):
body = residual_unit(body, filter_list[i+1], (1,1), True, name='stage%d_unit%d' % (i + 1, j + 2),
bottle_neck=bottle_neck, workspace=workspace, memonger=memonger)
bn1 = mx.sym.BatchNorm(data=body, fix_gamma=False, eps=2e-5, momentum=bn_mom, name='bn1')
relu1 = mx.sym.Activation(data=bn1, act_type='relu', name='relu1')
pool1 = mx.sym.Pooling(data=relu1, global_pool=True, kernel=(7, 7), pool_type='avg', name='pool1')
flat = mx.sym.Flatten(data=pool1)
fc1 = mx.sym.FullyConnected(data=flat, num_hidden=num_classes, name='fc1')
if dtype == 'float16':
fc1 = mx.sym.Cast(data=fc1, dtype=np.float32)
return mx.sym.SoftmaxOutput(data=fc1, name='softmax')
def get_symbol(num_classes, num_layers, image_shape, conv_workspace=256, dtype='float32', **kwargs):
"""
Adapted from https://github.com/tornadomeet/ResNet/blob/master/train_resnet.py
Original author Wei Wu
"""
image_shape = [int(l) for l in image_shape.split(',')]
(nchannel, height, width) = image_shape
if height <= 28:
num_stages = 3
if (num_layers-2) % 9 == 0 and num_layers >= 164:
per_unit = [(num_layers-2)//9]
filter_list = [16, 64, 128, 256]
bottle_neck = True
elif (num_layers-2) % 6 == 0 and num_layers < 164:
per_unit = [(num_layers-2)//6]
filter_list = [16, 16, 32, 64]
bottle_neck = False
else:
raise ValueError("no experiments done on num_layers {}, you can do it yourself".format(num_layers))
units = per_unit * num_stages
else:
if num_layers >= 50:
filter_list = [64, 256, 512, 1024, 2048]
bottle_neck = True
else:
filter_list = [64, 64, 128, 256, 512]
bottle_neck = False
num_stages = 4
if num_layers == 18:
units = [2, 2, 2, 2]
elif num_layers == 34:
units = [3, 4, 6, 3]
elif num_layers == 50:
units = [3, 4, 6, 3]
elif num_layers == 101:
units = [3, 4, 23, 3]
elif num_layers == 152:
units = [3, 8, 36, 3]
elif num_layers == 200:
units = [3, 24, 36, 3]
elif num_layers == 269:
units = [3, 30, 48, 8]
else:
raise ValueError("no experiments done on num_layers {}, you can do it yourself".format(num_layers))
return resnet(units = units,
num_stages = num_stages,
filter_list = filter_list,
num_classes = num_classes,
image_shape = image_shape,
bottle_neck = bottle_neck,
workspace = conv_workspace,
dtype = dtype)
|