CVPR2022的作品,Diffusion model在图像合成表现非常的出色,但是由于其是在图像像素空间进行的去噪等操作,所以相当的费时,本文通过两步走,先训练一个autoencoder将图像空间映射到latent空间,减少了图像的维度,再利用标准的difusion模型来进行加噪声去噪声过程,减少计算量,提高生成速度。另外,作者引入了cross-attention layers,将不同的任务的promt引入,比如:text 或者 bounding box等,使其实现不同的能力。本算法在多个任务上表现sota,比如:image inpainting、class-conditional imagesynthesis等
论文名称:High-Resolution Image Synthesis with Latent Diffusion Models
作者:Robin Rombach等
论文链接:https://arxiv.org/abs/2112.10752
Github:https://github.com/compvis/latent-diffusion
一些可以先研究一下的知识
- VQ-VAE
- VQGAN
introduction
Diffusion模型属于是基于似然估计的模型,由于基于像素的图像表示包含几乎不可察觉的高频细节[16,73],因此最大似然训练会花费不成比例的容量来对它们进行建模,从而导致训练时间过长。所以在训练的时候,需要比较大的资源消耗,为了减少资源消耗,增加其可用性,本文提出了latent diffusion
从分析像素空间中已经训练的扩散模型开始:图2显示了训练模型的速率失真权衡。与任何基于似然的模型一样,学习大致可以分为两个阶段:首先是感知压缩阶段,它会去除高频细节, 但仍然学习很少的语义变化。在第二阶段,实际的生成模型学习数据的语义和概念组成(语义压缩)。因此,我们的目标是首先找到一个感知上等效但计算上更合适的空间,我们将在其中训练用于高分辨率图像合成的扩散模型。
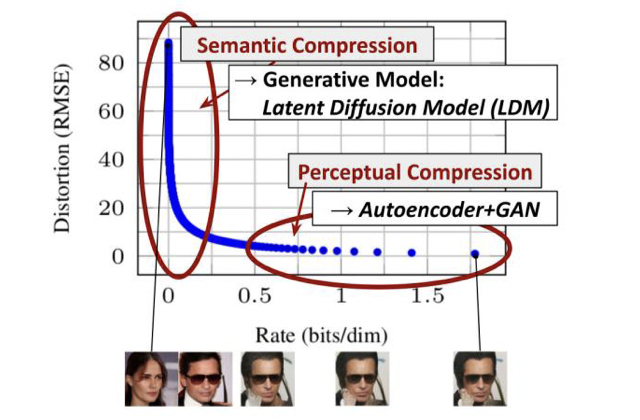
因此,作者将训练变为两个阶段:
- 训练一个autoencoder,将原来的高维转变为低维,autoencoder只训练一次,就可以反复用于下游的DM的训练中。
- 设计了一个transformer架构的UNet,实现标准的denoise过程。
我们的优点:
- 我们方法可以拓展到更高的维度,可以重建更为细节的工作,可应用于百万像素的图像合成。
- 显著降低了计算成本于推理成本。
- 与过去的基于encoder/decoder的架构相比,我们不需要复杂的参数来进行重建和生成,所以我们的重建效果更好。
- 对于超分辨率,修复等,我们可以使用conv对更大的图像进行处理,比如 1024x1024
- 通过cross-attention,允许多模型的训练,可以实现class-conditional,text-to-image等的训练。
Method
autoencoder先把图像特征维度压缩的二阶段训练的优点:
- 低维度的图像空间可以提高DM模型的计算效率
- 我们利用DM模型从unet继承的归纳偏置(对数据的空间结构数据更有效),减轻了以前方法降低质量的压缩要求。
- 我们得到了通用的压缩模型,其产生的latent space可以应用于很多的下游任务。
Perceptual Image Compression
autoencoder的train:
- preceptual loss
- patch-based adversarial objective
- 这确保了通过强制局部真实性将重建限制在image manifold中,并避免仅依赖像素空间损失(例如L2或L1目标)而引入的模糊。
为了避免随意的高方差的latent space,作者尝试了两种正则化方法这里没细研究:
- KL-reg,读学习的latent加一个正态分布的惩罚。
- VQGAN。
Latent Diffusion Models
LDM与DM相比较,主要啊变化从下面两个loss就能看出来:变化的就是原来的输x变成了E(x)
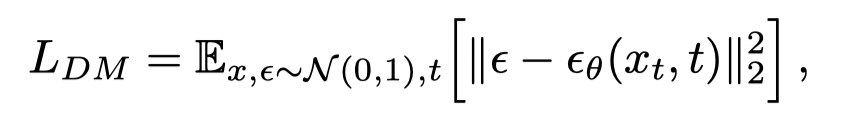
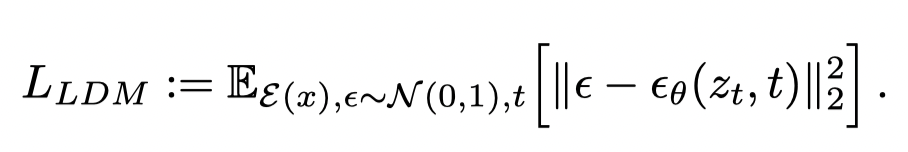
Conditioning Mechanisms
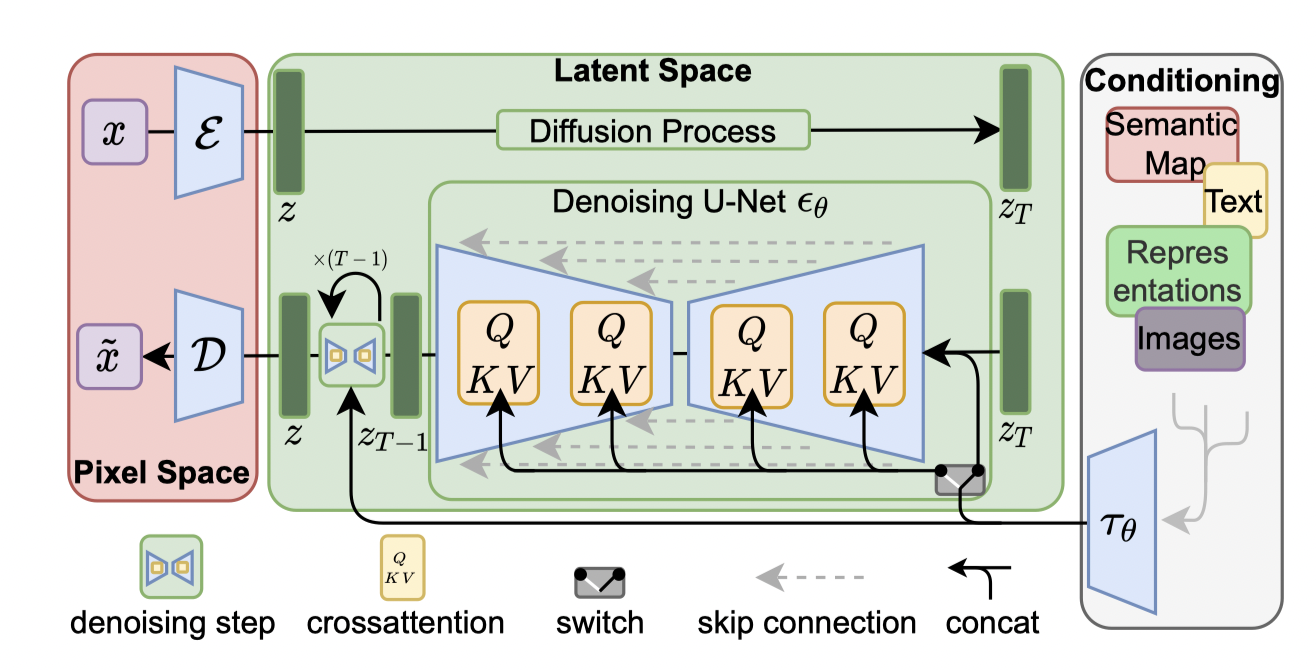
增加了cross-attention mechanism,可以增强识别不同的输入的有效性
整体结构就入下图所示:
实验
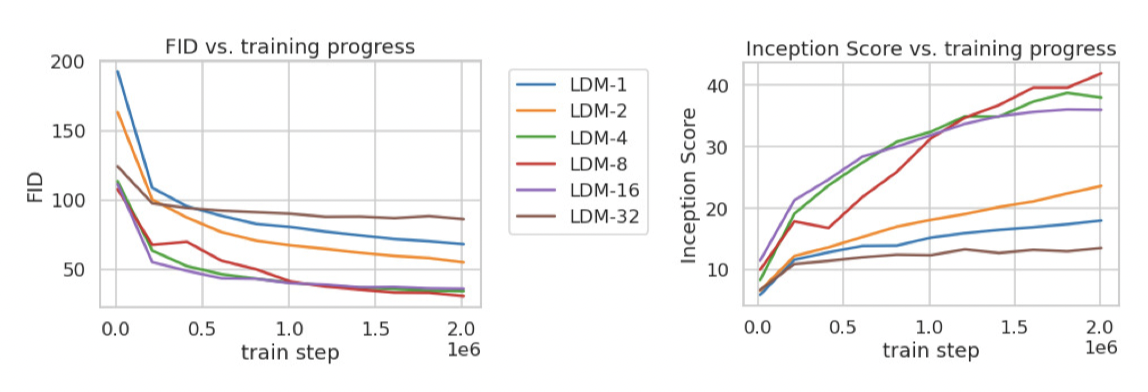
下采样实验:
- 当下采样较小时,可以看到,训练进度比较慢,这主要是由于将大部分感知压缩留给扩散模型导致的。
- 当下采样太大时,训练会停滞,这主要是由于压缩太强,导致信息丢失严重导致的。
- 所以在4-16是表现比较好的。
一些数据集的生成表现也很赞,这里就不一一展示了。